1.术语
相邻顶点:
当两个顶点通过一条边相连时,我们称这两个顶点是相邻的,并且称这条边依附于这两个顶点。
度:
某个顶点的度就是依附于该顶点的边的个数
子图:
是一幅图的所有边的子集(包含这些边依附的顶点)组成的图;
路径:
是由边顺序连接的一系列的顶点组成
环:
是一条至少含有一条边且终点和起点相同的路径 
连通图:
如果图中任意一个顶点都存在一条路径到达另外一个顶点,那么这幅图就称之为连通图
连通子图:
一个非连通图由若干连通的部分组成,每一个连通的部分都可以称为该图的连通子图 
2.存储结构
要表示一幅图,只需要表示清楚以下两部分内容即可:
1. 图中所有的顶点;
2. 所有连接顶点的边;
常见的图的存储结构有两种:邻接矩阵和邻接表
邻接矩阵
使用一个V*V的二维数组int[V][V] adj,把索引的值看做是顶点;
2. 如果顶点v和顶点w相连,我们只需要将adj[v][w]和adj[w][v]的值设置为1,否则设置为0即可。
很明显,邻接矩阵这种存储方式的空间复杂度是V^2的,如果我们处理的问题规模比较大的话,内存空间极有可能不够用。邻接表
1.使用一个大小为V的数组 Queue[V] adj,把索引看做是顶点;
2.每个索引处adj[v]存储了一个队列,该队列中存储的是所有与该顶点相邻的其他顶点 
邻接表的空间并不是是线性级别的
3.图的实现
package 图;import 线性表.Queue;public class Graph {//顶点数目private final int V;//边的数目private int E;//邻接表private Queue<Integer>[] adj;public Graph(int V) {//初始化顶点数量this.V = V;//初始化边的数量this.E = 0;//初始化邻接表this.adj = new Queue[V];//初始化邻接表中的空队列for (int i = 0; i < adj.length; i++) {adj[i] = new Queue<Integer>();}}//获取顶点数目public int V() {return V;}//获取边的数目public int E() {return E;}//向图中添加一条边 v-wpublic void addEdge(int v, int w) {//把w添加到v的链表中,这样顶点v就多了一个相邻点wadj[v].enqueue(w);//把v添加到w的链表中,这样顶点w就多了一个相邻点vadj[w].enqueue(v);//边的数目自增1E++;}//获取和顶点v相邻的所有顶点public Queue<Integer> adj(int v) {return adj[v];}}
4.图的搜索
在很多情况下,需要遍历图,得到图的一些性质,例如,找出图中与指定的顶点相连的所有顶点,或者判定某个顶点与指定顶点是否相通,是非常常见的需求。
有关图的搜索,最经典的算法有深度优先搜索和广度优先搜索
- 深度优先搜索
所谓的深度优先搜索,指的是在搜索时,如果遇到一个结点既有子结点,又有兄弟结点,那么先找子结点,然后找 兄弟结点。 
很明显,在由于边是没有方向的,所以,如果4和5顶点相连,那么4会出现在5的相邻链表中,5也会出现在4的相邻链表中,那么为了不对顶点进行重复搜索,应该要有相应的标记来表示当前顶点有没有搜索过,可以使用一个布 尔类型的数组 boolean[V] marked,索引代表顶点,值代表当前顶点是否已经搜索,如果已经搜索,标记为true, 如果没有搜索,标记为false。
代码实现:
package 图;public class DepthFirstSearch {//索引代表顶点,值表示当前顶点是否已经被搜索private boolean[] marked;//记录有多少个顶点与s顶点相通private int count;//构造深度优先搜索对象,使用深度优先搜索找出G图中s顶点的所有相邻顶点public DepthFirstSearch(Graph G, int s) {//创建一个和图的顶点数一样大小的布尔数组marked = new boolean[G.V()];//搜索G图中与顶点s相同的所有顶点dfs(G, s);}//使用深度优先搜索找出G图中v顶点的所有相邻顶点private void dfs(Graph G, int v) {//把当前顶点标记为已搜索marked[v] = true;//遍历v顶点的邻接表,得到每一个顶点wfor (Integer w : G.adj(v)) {//如果当前顶点w没有被搜索过,则递归搜索与w顶点相通的其他顶点if (!marked[w]) {dfs(G, w);}}//相通的顶点数量+1count++;}//判断w顶点与s顶点是否相通public boolean marked(int w) {return marked[w];}//获取与顶点s相通的所有顶点的总数public int count() {return count;}}
- 广度优先搜索
所谓的深度优先搜索,指的是在搜索时,如果遇到一个结点既有子结点,又有兄弟结点,那么先找兄弟结点,然后找子结点。 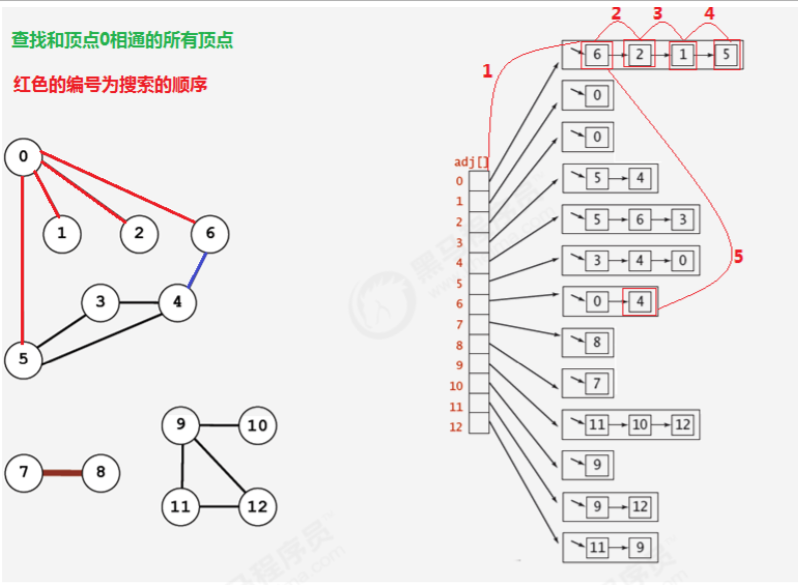
代码实现:
package 图;
import 线性表.Queue;
public class BreadthFirstSearch {
//索引代表顶点,值表示当前顶点是否已经被搜索
private boolean[] marked;
//记录有多少个顶点与s顶点相通
private int count;
//用来存储待搜索邻接表的点
private Queue<Integer> waitSearch;
//构造广度优先搜索对象,使用广度优先搜索找出G图中s顶点的所有相邻顶点
public BreadthFirstSearch(Graph G, int s) {
//创建一个和图的顶点数一样大小的布尔数组
marked = new boolean[G.V()];
//初始化待搜索顶点的队列
waitSearch = new Queue<Integer>();
//搜索G图中与顶点s相同的所有顶点
dfs(G, s);
}
//使用广度优先搜索找出G图中v顶点的所有相邻顶点
private void dfs(Graph G, int v) {
//把当前顶点v标识为已搜索
marked[v] = true;
//让顶点v进入队列,待搜索
waitSearch.enqueue(v);
System.out.print("节点" + v + "广度遍历顺序为:" + v);
//通过循环,如果队列不为空,则从队列中弹出一个待搜索的顶点进行搜索
while (!waitSearch.isEmpty()) {
//弹出一个待搜索的顶点
Integer wait = waitSearch.dequeue();
//遍历wait顶点的邻接表
for (Integer w : G.adj(wait)) {
// 该顶点还没被搜索过 对其进行搜索
if (!marked(w)) {
marked[w] = true;
// 将节点放入堆栈中,用于后续的获取该节点的子节点
waitSearch.enqueue(w);
//让相通的顶点+1;
count++;
System.out.print(" " + w);
}
}
}
System.out.println();
}
//判断w顶点与s顶点是否相通
public boolean marked(int w) {
return marked[w];
}
//获取与顶点s相通的所有顶点的总数
public int count() {
return count;
}
}
5.案例-畅通工程

总共有20个城市,目前已经修改好了7条道路,问9号城市和10号城市是否相通?9号城市和8号城市是否相通?
解题思路:
1.创建一个图Graph对象,表示城市;
2.分别调用addEdge(0,1),addEdge(6,9),addEdge(3,8),addEdge(5,11),addEdge(2,12),addEdge(6,10),addEdge(4,8),表示已 经修建好的道路把对应的城市连接起来;
3.通过Graph对象和顶点9,构建DepthFirstSearch对象或BreadthFirstSearch对象;
4.调用搜索对象的marked(10)方法和marked(8)方法,即可得到9和城市与10号城市以及9号城市与8号城市是否相通。
代码实现:
package 图;
import java.io.BufferedReader;
import java.io.InputStreamReader;
public class Traffic_Project2 {
public static void main(String[] args) throws Exception {
//创建输入流
BufferedReader reader = new BufferedReader(new
InputStreamReader(Traffic_Project2.class.getClassLoader().getResourceAsStream("traffic_proje
ct.txt")));
//读取城市数目,初始化Graph图
int number = Integer.parseInt(reader.readLine());
Graph G = new Graph(number);
//读取已经修建好的道路数目
int roadNumber = Integer.parseInt(reader.readLine());
//循环读取已经修建好的道路,并调用addEdge方法
for (int i = 0; i < roadNumber; i++) {
String line = reader.readLine();
int p = Integer.parseInt(line.split(" ")[0]);
int q = Integer.parseInt(line.split(" ")[1]);
G.addEdge(p, q);
}
//根据图G和顶点9构建图的搜索对象
//BreadthFirstSearch search = new BreadthFirstSearch(G,9);
DepthFirstSearch search = new DepthFirstSearch(G, 9);
//调用搜索对象的marked(10)方法和marked(8)方法
boolean flag1 = search.marked(10);
boolean flag2 = search.marked(8);
System.out.println("9号城市和10号城市是否已相通:" + flag1);
System.out.println("9号城市和8号城市是否已相通:" + flag2);
}
}
6.路径查找

在实际生活中,地图是我们经常使用的一种工具,通常我们会用它进行导航,输入一个出发城市,输入一个目的地 城市,就可以把路线规划好,而在规划好的这个路线上,会路过很多中间的城市。这类问题翻译成专业问题就是: 从s顶点到v顶点是否存在一条路径?如果存在,请找出这条路径。
实现:
基于深度优先搜索来完成 

实现代码:
package 图;
import 线性表.Stack;
public class DepthFirstPaths {
//索引代表顶点,值表示当前顶点是否已经被搜索
private boolean[] marked;
//起点
private int s;
//索引代表顶点,值代表从起点s到当前顶点路径上的最后一个顶点
private int[] edgeTo;
//构造深度优先搜索对象,使用深度优先搜索找出G图中起点为s的所有路径
public DepthFirstPaths(Graph G, int s) {
//创建一个和图的顶点数一样大小的布尔数组
marked = new boolean[G.V()];
//创建一个和图顶点数一样大小的整型数组
edgeTo = new int[G.V()];
//初始化顶点
this.s = s;
//搜索G图中起点为s的所有路径
dfs(G, s);
}
//使用深度优先搜索找出G图中v顶点的所有相邻顶点
private void dfs(Graph G, int v) {
//把当前顶点标记为已搜索
marked[v] = true;
//遍历v顶点的邻接表,得到每一个顶点w
for (Integer w : G.adj(v)) {
//如果当前顶点w没有被搜索过,则将edgeTo[w]设置为v,表示w的前一个顶点为v,并递归搜索与w顶点相通的其他顶点
if (!marked[w]) {
edgeTo[w] = v;
dfs(G, w);
}
}
}
//判断w顶点与s顶点是否存在路径
public boolean hasPathTo(int v) {
return marked[v];
}
//找出从起点s到顶点v的路径(就是该路径经过的顶点)
public Stack<Integer> pathTo(int v) {
//当前v顶点与s顶点不连通,所以直接返回null,没有路径
if (!hasPathTo(v)) {
return null;
}
//创建路劲中经过的顶点的容器
Stack<Integer> path = new Stack<Integer>();
//第一次把当前顶点存进去,然后将x变换为到达当前顶点的前一个顶点edgeTo[x],在把前一个顶点存进去,继续将x变化为到达前一个顶点的前一个顶点,继续存,一直到x的值为s为止,相当于逆推法,最后把s放进去
for (int x = v; x != s; x = edgeTo[x]) {
//把当前顶点放入容器
path.push(x);
}
//把起点s放入容器
path.push(s);
return path;
}
}

若有收获,就点个赞吧
0 人点赞
