一、Stream的操作三个步骤
- 创建Stream
- 一个数据源(如:集合,数组),获取一个流
- 中间操作
- 一个中间操作链,对数据源的数据进行处理
终止操作(终端操作)
-
二、获取Stream流的几种方式
@Testpublic void test() {// 1.可以通过Collection系列结合提供的stream() 或 parallelStream()List<String> list = new ArrayList<>();Stream<String> stream = list.stream();Stream<String> stringStream = list.parallelStream();// 2.通过Arrays中的静态方法stream()获取数组流Integer[] array = new Integer[10];Stream<Integer> stream1 = Arrays.stream(array);// 3.通过Stream类中的静态方法of()Stream<String> stream2 = Stream.of("aa", "bb", "cc");// 4.创建无限流// 4.1 迭代Stream<Integer> iterate = Stream.iterate(0, x -> x + 2);iterate.limit(10).forEach(System.out::println);// 4.2 生成Stream<Double> generate = Stream.generate(() -> Math.random());generate.forEach(System.out::println);}
三、Stream中常用方法(中间操作)
多个中间操作可以连接起来形成一个流水线,除非流水线触发终止操作,否则中间操作不会执行任何的处理!而在终止操作时一次性全部处理,称为“惰性求值”。
1、筛选与切片
-
- filter()——接收Lambda,从流中排除某些元素。
- limit(n)——截断流,使其元素不超过非定数量
- skip(n)——跳过元素,返回一个扔掉了前n个元素的流,若流中的元素不足n个,则返回一个空流。与limit()互补
distinct——筛选,通过流所生成元素的hashCode()和equals()去除重复元素
2、映射
map——接收lambda,将元素转换成其他形式或提取信息,接收一个函数作为参数,该函数会被应用到每个
flatMap——接收一个函数作为参数,将流中的每个值都换成另一个流,然后把所有流连接成一个流
3、排序
sorted()——自然排序
sorted(Comparator com)——定制排序
/*** 排序* sorted()——自然排序(Comparable)* sorted(Comparator com)——定制排序*/@Testpublic void testSort() {List<String> list = Arrays.asList("aaa", "ddd", "bbb", "zz", "fff");// 自然排序list.stream().sorted().forEach(System.out::println); // aaa,bbb,ddd,fff,zz// 定制排序List<Person> people = Arrays.asList(new Person("周杰伦", 18), new Person("方文山", 40), new Person("林俊杰", 28), new Person("周杰伦", 20));people.stream().sorted( (p1,p2) -> {if (p1.getName().equals(p2.getName())) {return p1.getAge().compareTo(p2.getAge());} else {return p1.getName().compareTo(p2.getName());}}).forEach(System.out::println);}
四、Stream中常用方法(终止操作)
1. 查找与匹配
allMatch()——检查是否匹配所有元素
- anyMatch()——检查是否至少匹配一个元素
- noneMatch()——检查是否没有匹配所有元素
- findFirst()——返回第一个元素
findAny()——返回当前流中的任意元素
@Testpublic void test() {List<Person> people = Arrays.asList(new Person("周杰伦", 18), new Person("方文山", 40), new Person("昆凌", 40), new Person("薛之谦", 40));// 检查是否匹配所有元素boolean b = people.stream().allMatch(e -> e.getName().equals("周杰伦"));System.out.println(b); // false// 检查是否至少匹配一个元素boolean b1 = people.stream().anyMatch(e -> e.getName().equals("周杰伦"));System.out.println(b1); // true// 检查是否没有匹配所有元素boolean b2 = people.stream().noneMatch(e -> e.getName().equals("林俊杰"));System.out.println(b2); // true// 返回第一个元素Optional<Person> first = people.stream().findFirst();System.out.println(first); // Optional[Person(name=周杰伦, age=18)]// 返回当前流中的任意元素for (int i = 0; i < 100; i++) {Optional<Person> any = people.parallelStream().findAny();System.out.println(any);}}
count()——返回流中元素的总个数
- max()——返回流中最大值
min()——返回流中最小值
@Testpublic void test3() {List<Person> people = Arrays.asList(new Person("周杰伦", 18), new Person("方文山", 45), new Person("昆凌", 40), new Person("薛之谦", 40));// 返回流中元素的总个数long count = people.stream().count();System.out.println(count); // 4// 返回流中最大值Optional<Person> max = people.stream().max((p1, p2) -> p1.getAge().compareTo(p2.getAge()));System.out.println(max); // Optional[Person(name=方文山, age=45)]// 返回流中最小值Optional<Integer> min = people.stream().map(Person::getAge).min((p1, p2) -> Integer.compare(p1, p2));System.out.println(min); // Optional[18]}
4、归约
reduce(T identity,BinaryOperator)/reduce(BinaryOperator)——可以将流中元素反复结合起来 ,得到一个值
备注:map和reduce的连接通常称为map-reduce模式,因Google用它来进行网络搜索而出名。
@Testpublic void test4() {List<Integer> list = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);// 可以将流中元素反复结合起来 ,得到一个值(两个参数的)Integer reduce = list.stream().reduce(0, (x, y) -> x + y); // 第一个参数是起始值,此例中:0作为x,然后从集合中取出第一个元素1,将二者相加,再取第二个元素2.....以此类推System.out.println(reduce); // 55// 可以将流中元素反复结合起来 ,得到一个值(一个参数的)Optional<Integer> reduce2 = list.stream().reduce(Integer::sum);System.out.println(reduce2); // 55}
collect——将流转换为其他形式,接收一个Collector接口的实现,用于stream中元素做汇总的方法。
Collector接口中方法的实现决定了如何对流执行收集操作(如收集到List,Set,Map)。但是COllectors实用类提供了很多静态方法,可以方便的创建常见收集器实例。
@Testpublic void test5() {List<Person> people = Arrays.asList(new Person("周杰伦", 18),new Person("周杰伦", 18), new Person("方文山", 45), new Person("昆凌", 40), new Person("薛之谦", 40));// 将流转换为其他形式,接收一个Collector接口的实现,用于stream中元素做汇总的方法。List<String> collect = people.stream().map(Person::getName).collect(Collectors.toList());collect.forEach(System.out::print); // 周杰伦周杰伦方文山昆凌薛之谦System.out.println();System.out.println("-------------------");Set<String> collect1 = people.stream().map(Person::getName).collect(Collectors.toSet()); // 做到去重效果collect1.forEach(System.out::print); // 周杰伦方文山薛之谦昆凌System.out.println();System.out.println("-------------------");HashSet<String> collect2 = people.stream().map(Person::getName).collect(Collectors.toCollection(HashSet::new)); // Collectors.toCollection() 想放到哪个集合中,就指定哪个集合collect2.forEach(System.out::print); // 周杰伦方文山薛之谦昆凌}
@Testpublic void test6() {List<Person> people = Arrays.asList(new Person("周杰伦", 18),new Person("周杰伦", 18), new Person("方文山", 45), new Person("昆凌", 40), new Person("薛之谦", 40));// 1.总数Long collect = people.stream().collect(Collectors.counting());System.out.println(collect); // 5// 2.平均值Double collect1 = people.stream().collect(Collectors.averagingInt(Person::getAge));System.out.println(collect1); // 32.2// 总和Integer collect2 = people.stream().collect(Collectors.summingInt(Person::getAge));System.out.println(collect2); // 161// 最大值Optional<Integer> collect3 = people.stream().map(Person::getAge).collect(Collectors.maxBy((p1, p2) -> Integer.compare(p1, p2)));System.out.println(collect3); // Optional[45]// 最小值Optional<Integer> collect4 = people.stream().map(Person::getAge).collect(Collectors.minBy((p1, p2) -> Integer.compare(p1, p2)));System.out.println(collect4); // Optional[18]}
/*** 分组*/@Testpublic void test7() {List<Person> people = Arrays.asList(new Person("周杰伦", 18),new Person("周杰伦", 18), new Person("方文山", 45), new Person("昆凌", 40), new Person("薛之谦", 40));Map<String, List<Person>> collect = people.stream().collect(Collectors.groupingBy(Person::getName)); // 按照姓名分组// 注意:map不能forEach.必须要获取到他的key或value集合才能forEachSystem.out.println(collect); // {周杰伦=[Person(name=周杰伦, age=18), Person(name=周杰伦, age=18)], 薛之谦=[Person(name=薛之谦, age=40)], 方文山=[Person(name=方文山, age=45)], 昆凌=[Person(name=昆凌, age=40)]}/*** 输出:* {* 周杰伦=[Person(name=周杰伦, age=18), Person(name=周杰伦, age=18)],* 薛之谦=[Person(name=薛之谦, age=40)],* 方文山=[Person(name=方文山, age=45)],* 昆凌=[Person(name=昆凌, age=40)]* }*/}
/*** 多级分组*/@Testpublic void test8() {List<Person> people = Arrays.asList(new Person("周杰伦", 45),new Person("周杰伦", 18),new Person("周杰伦", 18), new Person("方文山", 45), new Person("昆凌", 40), new Person("薛之谦", 40));Map<String, Map<Integer, List<Person>>> collect = people.stream().collect(Collectors.groupingBy(Person::getName, Collectors.groupingBy(Person::getAge)));System.out.println(collect);/*** 输出:* {* 周杰伦={* 18=[Person(name=周杰伦, age=18), Person(name=周杰伦, age=18)],* 45=[Person(name=周杰伦, age=45)]* },* 薛之谦={40=[Person(name=薛之谦, age=40)]},* 方文山={45=[Person(name=方文山, age=45)]},* 昆凌={40=[Person(name=昆凌, age=40)]}* }*/}
/*** 分区* 满足条件的一个区* 不满足条件的一个区*/@Testpublic void test9() {List<Person> people = Arrays.asList(new Person("周杰伦", 45),new Person("周杰伦", 18),new Person("周杰伦", 18), new Person("方文山", 45), new Person("昆凌", 40), new Person("薛之谦", 40));Map<Boolean, List<Person>> collect = people.stream().collect(Collectors.partitioningBy(p -> p.getAge() > 20));System.out.println(collect);/*** 输出:* {* false=[Person(name=周杰伦, age=18), Person(name=周杰伦, age=18)],* true=[Person(name=周杰伦, age=45), Person(name=方文山, age=45), Person(name=昆凌, age=40), Person(name=薛之谦, age=40)]* }*/}
@Testpublic void test10() {List<Person> people = Arrays.asList(new Person("周杰伦", 45),new Person("周杰伦", 18),new Person("周杰伦", 18), new Person("方文山", 45), new Person("昆凌", 40), new Person("薛之谦", 40));IntSummaryStatistics collect = people.stream().collect(Collectors.summarizingInt(Person::getAge));System.out.println(collect.getSum());System.out.println(collect.getAverage());System.out.println(collect.getMax());System.out.println(collect.getMin());System.out.println(collect.getCount());/*** 输出:* 206* 34.333333333333336* 45* 18* 6*/}
@Testpublic void test11() {List<Person> people = Arrays.asList(new Person("周杰伦", 45),new Person("周杰伦", 18),new Person("周杰伦", 18), new Person("方文山", 45), new Person("昆凌", 40), new Person("薛之谦", 40));String collect = people.stream().map(Person::getName).collect(Collectors.joining()); // 连接System.out.println(collect); // 周杰伦周杰伦周杰伦方文山昆凌薛之谦String collect1 = people.stream().map(Person::getName).collect(Collectors.joining(",")); // 连接,并且想在名字之间加个“,”System.out.println(collect1); // 周杰伦,周杰伦,周杰伦,方文山,昆凌,薛之谦String collect2 = people.stream().map(Person::getName).collect(Collectors.joining(",","开始——(",")——结束")); // 连接,并且想在名字之间加个“,”,再在收尾加个标识System.out.println(collect2); // 开始——(周杰伦,周杰伦,周杰伦,方文山,昆凌,薛之谦)——结束}
五、并行流与顺序流(串行流)
1、简介
并行流就是把一个内容分成多个数据块,并用不同的线程分别处理每个数据块的流。
Java 8 中将并行进行了优化,我们可以很容易的对数据进行并行操作。Steam API 可以声明性地通过paraller()与sequential()在并行流与顺序流之间进行切换。2、了解Fork/Join框架
2.1 简介
Fork/Join框架:就是在必要的情况下,将一个大任务,进行拆分(fork)成若干个小任务(拆到不可再拆时 ),再将一个个的小任务运算结果进行join汇总。
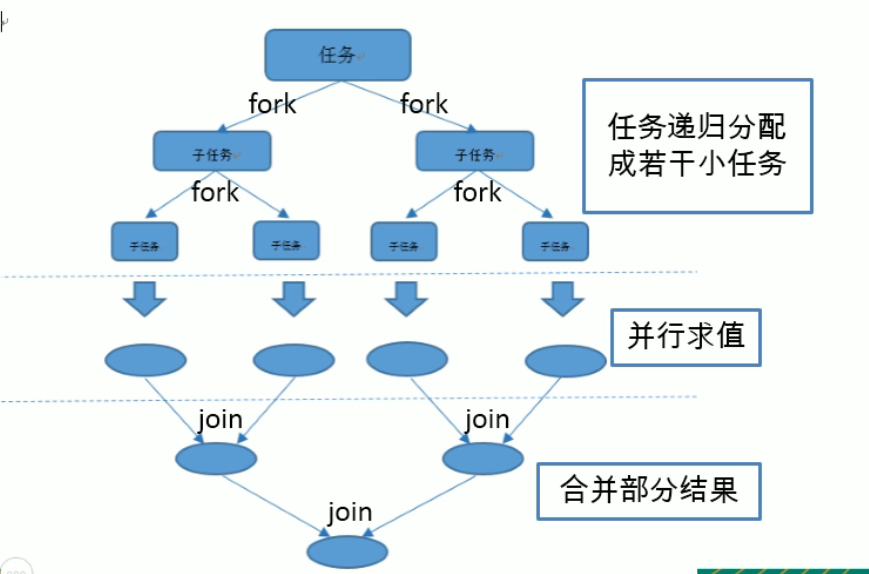
2.2 Fork/Join框架与传统线程池的区别
采用“工作窃取”模式(work—stealing)
当执行新的任务时他可以将其拆分分成更小的任务执行,并将小任务加到线程队列中,然后再从一个随机线程的队列中偷入一个并把它放到自己的队列中。
相对于一般的线程池实现,fork/join框架的优势体现在对其中包含的任务的处理方式上,在一般的线程正在执行的任务由于某些原因无法继续执行,那么该线程将会处于等待状态,而fork/join框架实现中,如果某个子问题由于等待另一个子问题的完成而无法继续执行,那么处理该子问题的线程会主动寻求其他尚未运行的子问题来执行,这种方式减少了线程的等待时间,提高了性能。2.3 案例
@Testpublic void test12() {long start = System.currentTimeMillis();long sum = 0;for (long i = 0; i < 10000000000L; i++) {sum += i;}System.out.println(sum);Long end = System.currentTimeMillis();System.out.println(end-start); // 2297}// 并行流@Testpublic void test13() {Instant start = Instant.now();long reduce = LongStream.rangeClosed(0, 10000000000L).parallel().reduce(0, Long::sum);System.out.println(reduce);Instant end = Instant.now();System.out.println(Duration.between(start,end).toMillis()); // 475}
六、Optional类
Optional
类(java.util.Optional)是一个容器类,代表一个值存在或不存在,原来用null来表示一个值不存在,现在Optional可以更好的表达这个概念,并且可以避免空指针异常。 常用方法:


若有收获,就点个赞吧
0 人点赞
