一:集合的概念:
对象的容器,定义了对多个对象进行操作的常用方法。可实现数组的功能。
和数组的区别:
- 数组的长度固定,集合长度不固定
- 数组可以存储基本类型和引用类型,集合只能存储引用类型(如果要存储引用类型的话则要用他们的包装类)
Collection体系:
![UYABWU$8CMWR0[HEIE{A.png
二:Collection接口
方法:
boolean add(Object obj);//添加一个对象boolean addAll(Collection c);//讲一个集合中所有对象添加到此集合中void clear();//清空此集合中的所有对象boolean contains(Object o);//检查此集合中是否包含o对象boolean equals(Object o);//比较此集合是否与指定对象相等boolean isEmpty();//判断此集合是否为空boolean remove(Object o);//在此集合中移除o对象int size();//返回此集合中的元素个数Object[] toArray();//将此集合转换成数组Iterator<E> iterator();//返回在此Collection的元素上进行迭代的迭代器
迭代器(专门用来遍历集合的一种方式)
Iterator it = 集合名称.iterator();while(it.hasNext()){ //boolean hasNext(); 集合中有没有下一个元素,若有,返回trueObject o = it.next(); //Object next(); 获取下一个元素System.out.println(o);it.remove(); //void remove(); 移除下一个元素,用迭代器遍历集合时,若要移除集合中的元素,那只能用迭代器中的remove()方法}
三:List接口与实现类
(1)List接口:
特点:有序,有下标,元素可以重复。
特有的方法:(相对于Collection接口)
void add(int index,Object o); //在Index位置插入对象oboolean addAll(int index,Collection c);//将一个集合中的元素添加到此集合的index位置上Object get(int index);//返回集合中指定位置的元素List subList(int fromIndex,int toIndex);//返回fromIndex和toIndex之间的元素集合ListIterator<> ListIterator(int index);//可以以任意方向遍历集合(里面有许多方法),比Iterator功能强大
(2)实现类:
ArrayList【重点】
1. 数组结构实现,查询快,增删慢;1. JDK1.2版本,运行效率快,线程不安全。
LinkedList【重点】
1. (双向)链表结构实现,增删快,查询慢
Vector【了解】
1. 数组结构实现,查询快,增删慢(和ArrayList很像)1. JDK1.0版本,运行效率慢,线程安全。
四:泛型和工具类_
概念:JAVA泛型是JDK1.5中引入的一个新特性,其本质是参数化类型,把类型作为参数传递。
常见形式有泛型类(类名
//泛型类举例public class MyGeneric<T> {T t;void print(T t){System.out.println(t);}T show(T t){return t;}}
语法:
好处:
- 提高代码的重用性。
- 防止类型转换异常,提高代码的安全性。
泛型集合:
概念:参数化类型、类型安全的集合,强制集合元素的类型必须一致。
特点:
1. 编译时即可检查,而非运行时抛出异常。1. 访问时,不必类型转换(拆箱)。1. 不停泛型之间引用不能相互赋值,泛型不存在多态。
五:Set接口与实现类
Set接口
实现类
- HashSet【重点】
- 基于HashCode实现元素不重复
- 当存入元素的哈希值相同时,会调用equals()进行确认,如结果为true,则拒绝后者存入。
- 存储结构:哈希表(数组+链表+红黑树)
- TreeSet:
- 基于排列顺序实现元素不重复。
- 实现了SortedSet接口,对集合元素自动排序。
- 元素对象的类型(即要往TreeSet集合中存储的类)必须实现Comparable接口,指定排序规则。
- 通过CompareTo()方法确定是否为重复元素。
- 存储结构:红黑树
```java
//元素对象的类型(即要往TreeSet集合中存储的类)必须实现Comparable接口;
//指定排序规则。
public class Person implements Comparable
{ //通过CompareTo()方法确定是否为重复元素。 @Override public int compareTo(Person o) { //先按姓名比,再按年龄比 int n1 = this.getName().compareTo(o.getName()); int n2 = this.age-o.getAge(); return n1==0?n2:n1; } }
//也可以不用实现Comparable接口,而是在创建TreeSet集合时实现一个比较器Comparator.
TreeSet
<a name="ne94e"></a>### 拓展:<a name="e1S5q"></a>#### (1)哈希值与地址值的区别:1. 地址是存储某个数据的位置信息,两个地址相同的对象,根本上就是同一个,其中一个的内容变化,另一个也同样变化,直到其中一个变量指向另一地址。1. 哈希值是对象所有或者指定内容根据一特定算法得到的值,java对象中继承自object类的**_equals方法就是默认比较哈希值_**的,两个不同地址的对象,如果哈希值相同,使用默认equals()比较方法是会被认为相等,但是一个对象变化并不会引起另一个的反应。1. 哈希值和地址值是不一样的,哈希值是通过哈希算法散列得来的,而地址值是通过是和物理层面有关,是系统分配的,是不存在相同的,而哈希值是可以通过强制手段设置为相同的,也就是说哈希值是一种逻辑上的确保唯一性,而地址值就是物理上确保唯一性。1. 我们覆盖hashCode()方法的目的是为了让我们认为相同的元素得到的hash值相同; 简而言之:就是为了去重。<a name="gEJ03"></a>#### (2)a.equals(b)和a==b的区别:1. 如果a和b都是基本数据类型,则a.equals(b) 和 a == b 结果相同,但是在引用类型中它们的行为是不同的。1. "==" : 对于基本数据类型,操作比较的是两个变量的值是否相等。对于引用数据类型,表示的是两个变量在堆中存储的地址是否相同,即栈中的内容是否相同。1. "equals" : 操作表示的两个变量是否是对同一个对象的引用(哈希值),即堆中的内容是否相同。<a name="k8vFr"></a>## 六:Map接口与实现类<a name="ezJJ8"></a>#### Map体系: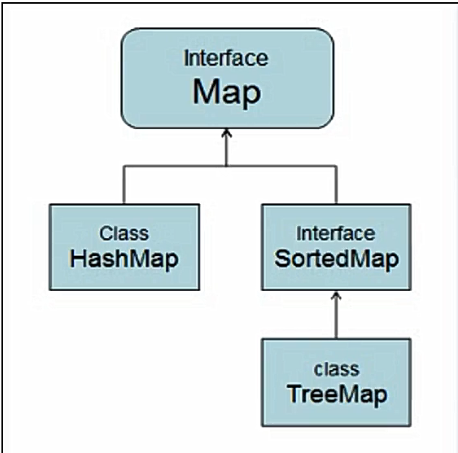<a name="Cte1K"></a>#### Map接口的特点:1. 用于存储任意键值对(Key—Value)。1. 键:无序、无下标、不允许重复(唯一)。1. 值:无序、无下标、允许重复。<a name="iRmYq"></a>#### Map常用方法:```javaMap<String,Integer> map = new HashMap<>();V put(K Key,V Value);//将对象存入到集合中,关联键值。key重复则覆盖原值。Object get(Object Key);//根据键获取对应的值Set<K>;//返回所有的KeyCollection<V> values();//返回包含所有值的Collection集合Set<Map,Entry<K,V>>;//键值匹配的Set集合Set<Map,Entry<K,V>> entrySet();//返回此映射中包含的映射关系的Set视图Set<K> KeySet();//返回此映射中包含的键的Set视图
遍历Map集合:
//遍历Map集合:使用keySet().Set<String> keyset = map.keySet();for (String key : keyset) {System.out.println("Key值是:"+key+"。value值是:"+map.get(key));}//遍历Map集合:使用entrySet().(这个效率相对较高)Set<Map.Entry<String, String>> entries = map.entrySet();for (Map.Entry<String, String> entry : entries) {System.out.println(entry.getKey()+"---"+entry.getValue());}
实现类:
(1)HashMap:【重点】
- JDK1.2版本,线程不安全(也就是说只能在单线程情况下使用),运行效率快;允许用null作为key或是value。
-
(2)Hashtable
JDK1.0版本,线程安全,运行效率慢;不允许null作为key或是value。
(3)Properties
Hashtable
要求key和value都是String。通常用于配置文件的读取。
(4)TreeMap
实现了SortedMap接口(是Map的子接口),可以对Key自动排序。
七:Colletions工具类
概念:
方法:
public static void reverse(List<?> list);//反转集合中元素的顺序public static void shuffle(List<?> list);//随机重置集合元素的顺序public static void sort(List<?> list);//升序排序(元素(引用)类型必须实现Comparable接口)
八:集合总结
集合概念:
对象的容器,和数组类似,定义了对多个对象进行操作的常用方法。
List集合:
有序,有下标,元素可以重复。(ArrayList,LinkedList,Vector)
Set集合:
无序,无下标,元素不可以重复。(HashSet,TreeSet)
Map集合:
存储一对数据,无序,无下标,键不可重复,值可重复。(HashMap,HashTable,TreeMap)
Collections工具类:
集合工具类,定义了除了存取以外的集合常用方法。

若有收获,就点个赞吧
0 人点赞

{kind=link}