一、什么是多级缓存
传统的缓存策略一般是请求到达Tomcat后,先查询Redis,如果未命中则查询数据库,如图: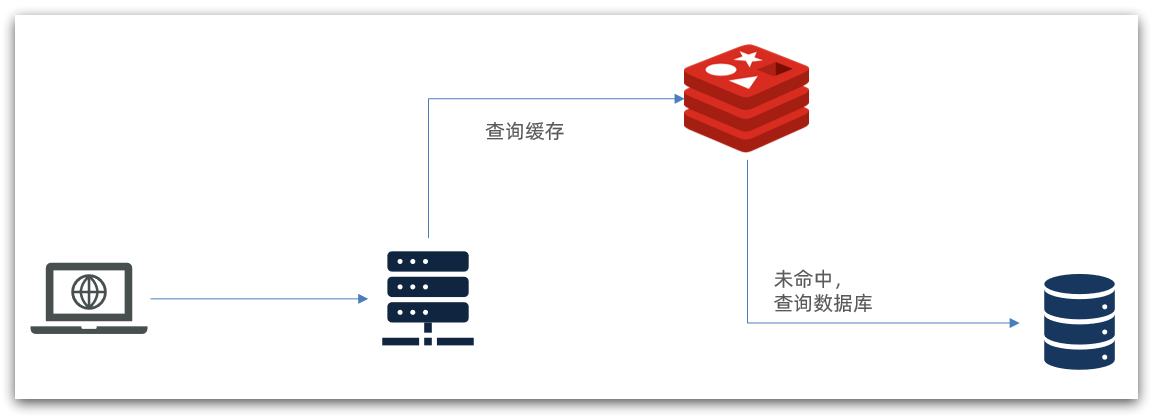
存在下面的问题:
•请求要经过Tomcat处理,Tomcat的性能成为整个系统的瓶颈
•Redis缓存失效时,会对数据库产生冲击
多级缓存就是充分利用请求处理的每个环节,分别添加缓存,减轻Tomcat压力,提升服务性能:
- 浏览器访问静态资源时,优先读取浏览器本地缓存
- 访问非静态资源(ajax查询数据)时,访问服务端
- 请求到达Nginx后,优先读取Nginx本地缓存
- 如果Nginx本地缓存未命中,则去直接查询Redis(不经过Tomcat)
- 如果Redis查询未命中,则查询Tomcat
- 请求进入Tomcat后,优先查询JVM进程缓存
- 如果JVM进程缓存未命中,则查询数据库
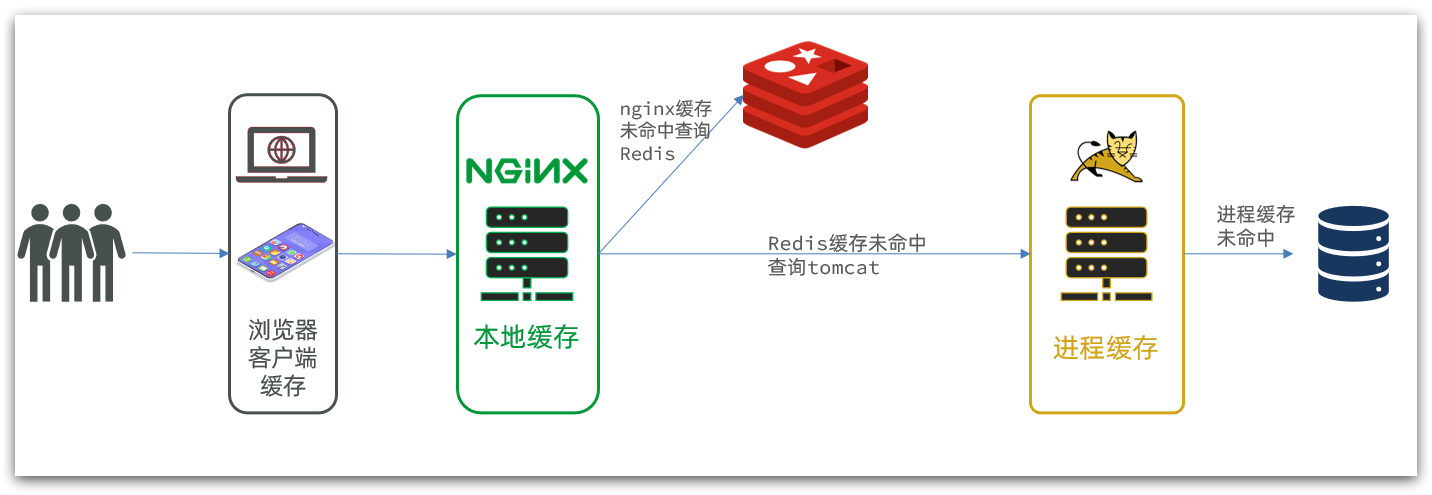
在多级缓存架构中,Nginx内部需要编写本地缓存查询、Redis查询、Tomcat查询的业务逻辑,因此这样的nginx服务不再是一个反向代理服务器,而是一个编写业务的Web服务器了。
因此这样的业务Nginx服务也需要搭建集群来提高并发,再有专门的nginx服务来做反向代理,如图: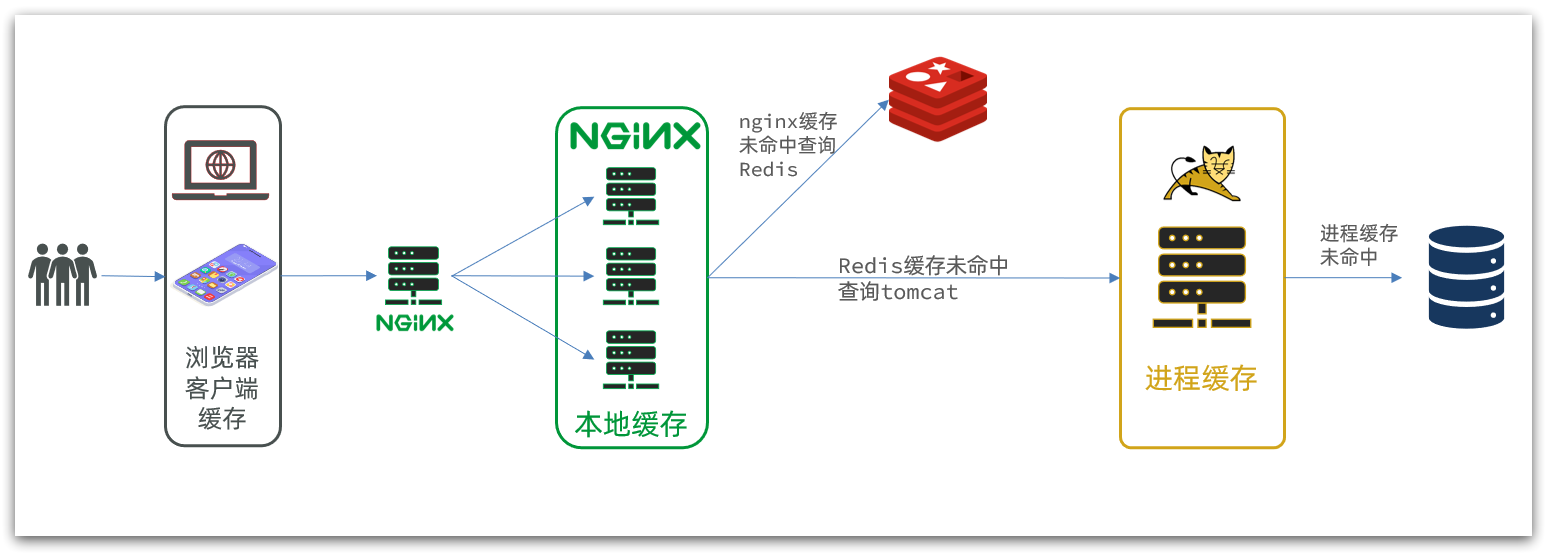
另外,我们的Tomcat服务将来也会部署为集群模式: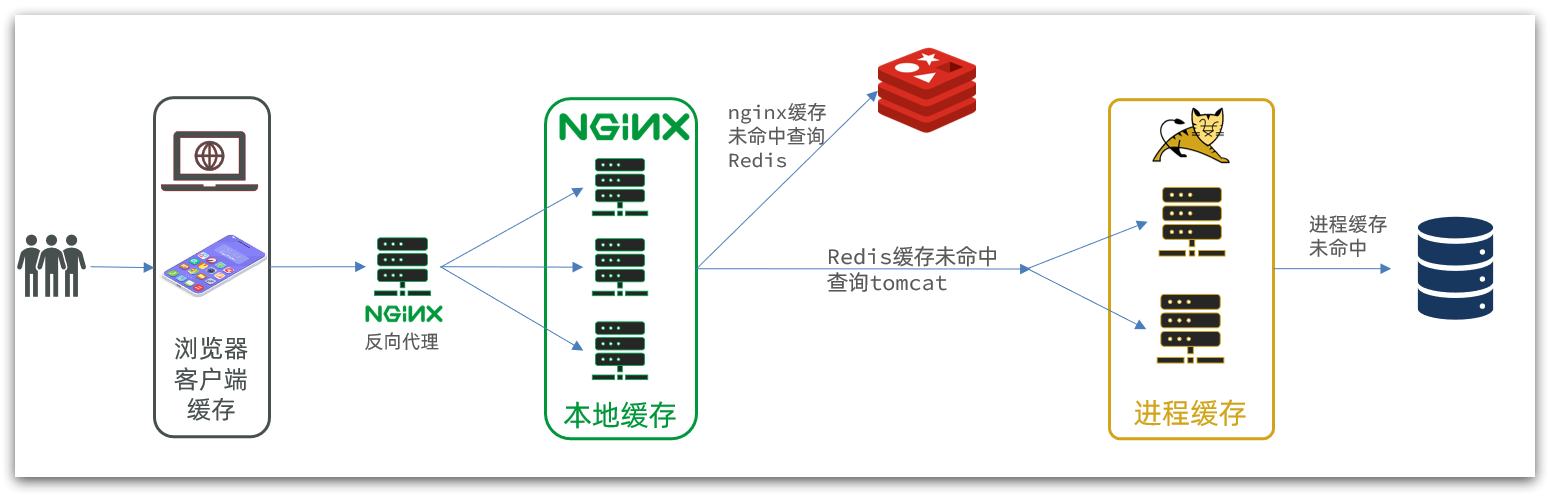
二、JVM进程缓存
1、初识Caffeine
缓存在日常开发中启动至关重要的作用,由于是存储在内存中,数据的读取速度是非常快的,能大量减少对数据库的访问,减少数据库的压力。我们把缓存分为两类:
- 分布式缓存,例如Redis:
- 优点:存储容量更大、可靠性更好、可以在集群间共享
- 缺点:访问缓存有网络开销
- 场景:缓存数据量较大、可靠性要求较高、需要在集群间共享
- 进程本地缓存,例如HashMap、GuavaCache:
- 优点:读取本地内存,没有网络开销,速度更快
- 缺点:存储容量有限、可靠性较低、无法共享
- 场景:性能要求较高,缓存数据量较小
我们今天会利用Caffeine框架来实现JVM进程缓存。
Caffeine是一个基于Java8开发的,提供了近乎最佳命中率的高性能的本地缓存库。目前Spring内部的缓存使用的就是Caffeine。GitHub地址:https://github.com/ben-manes/caffeine
Caffeine的性能非常好。
缓存使用的基本API:
public class CacheTestDemo {@Testpublic void testBasicOps() {// 构建cache对象Cache<String, String> cache = Caffeine.newBuilder().build();// 存数据cache.put("gf", "迪丽热巴");// 取数据String gf = cache.getIfPresent("gf");System.out.println("gf = " + gf);// 取数据,包含两个参数:// 参数一:缓存的key// 参数二:Lambda表达式,表达式参数就是缓存的key,方法体是查询数据库的逻辑// 优先根据key查询JVM缓存,如果未命中,则执行参数二的Lambda表达式String defaultGF = cache.get("defaultGF", key -> {// 根据key去数据库查询数据return "柳岩";});System.out.println("defaultGF = " + defaultGF);}}
// 检索一个entry,如果没有则为nullcache.getIfPresent(key);// 检索一个entry,如果entry为null,则通过key创建一个entry并加入缓存cache.get(key, k -> createExpensiveGraph(key));// 插入或更新一个实体cache.put(key, graph);// 移除一个实体cache.invalidate(key);
Caffeine既然是缓存的一种,肯定需要有缓存的清除策略,不然的话内存总会有耗尽的时候。
Caffeine提供了三种缓存驱逐策略:
基于容量:设置缓存的数量上限
// 创建缓存对象Cache<String, String> cache = Caffeine.newBuilder().maximumSize(1) // 设置缓存大小上限为 1.build();
基于时间:设置缓存的有效时间
// 创建缓存对象Cache<String, String> cache = Caffeine.newBuilder()// 设置缓存有效期为 10 秒,从最后一次写入开始计时.expireAfterWrite(Duration.ofSeconds(10)).build();
基于引用:设置缓存为软引用或弱引用,利用GC来回收缓存数据。性能较差,不建议使用。
**注意**:在默认情况下,当一个缓存元素过期的时候,Caffeine不会自动立即将其清理和驱逐。而是在一次读或写操作后,或者在空闲时间完成对失效数据的驱逐。
2、需求
利用Caffeine实现下列需求:
给根据id查询商品的业务添加缓存,缓存未命中时查询数据库
- 给根据id查询商品库存的业务添加缓存,缓存未命中时查询数据库
- 缓存初始大小为100
缓存上限为10000
@Configurationpublic class CaffeineConfig {@Bean("integerCache")public Cache<Long, Integer> itemCache(){final Cache<Long, Integer> build = Caffeine.newBuilder()// 初始容量.initialCapacity(100)// 缓存上限.maximumSize(10_000).build();build.put(1L,123);return build;}@Bean("stringCache")public Cache<Long, String> stockCache(){return Caffeine.newBuilder().initialCapacity(100).maximumSize(10_000).build();}}
```java @RestController @RequestMapping(“cache”) public class CacheController {
@Resource(name = “integerCache”) private Cache
@GetMapping(“{id}”) public Integer cache01(@PathVariable(“id”) Long id) {
Integer realResult = integerCache.get(id, k -> {// 模拟查询数据库// 查询完成后会自动将查询结果封装进缓存,其中Key即为Lamdba中的参数kInteger result = Math.toIntExact(id);// 返回结果return result;});return realResult;
}
}
<a name="uXPjD"></a># 三、缓存预热Redis缓存会面临冷启动问题:<br />**冷启动**:服务刚刚启动时,Redis中并没有缓存,如果所有商品数据都在第一次查询时添加缓存,可能会给数据库带来较大压力。<br />**缓存预热**:在实际开发中,我们可以利用大数据统计用户访问的热点数据,在项目启动时将这些热点数据提前查询并保存到Redis中。这里我们利用InitializingBean接口来实现,因为InitializingBean可以在对象被Spring创建并且成员变量全部注入后执行。<a name="FKWqe"></a>#### 作用:1. InitializingBean接口为bean提供了初始化方法的方式,它只包括afterPropertiesSet方法,凡是继承该接口的类,在初始化bean的时候都会执行该方法。```java@Componentpublic class hcyr implements InitializingBean {@Overridepublic void afterPropertiesSet() throws Exception {// 执行初始化工作}}
四、数据同步策略
缓存数据同步的常见方式有三种:
设置有效期:给缓存设置有效期,到期后自动删除。再次查询时更新
- 优势:简单、方便
- 缺点:时效性差,缓存过期之前可能不一致
- 场景:更新频率较低,时效性要求低的业务
同步双写:在修改数据库的同时,直接修改缓存
- 优势:时效性强,缓存与数据库强一致
- 缺点:有代码侵入,耦合度高;
- 场景:对一致性、时效性要求较高的缓存数据
异步通知:修改数据库时发送事件通知,相关服务监听到通知后修改缓存数据
- 优势:低耦合,可以同时通知多个缓存服务
- 缺点:时效性一般,可能存在中间不一致状态
- 场景:时效性要求一般,有多个服务需要同步
而异步实现又可以基于MQ或者Canal来实现:
1)基于MQ的异步通知: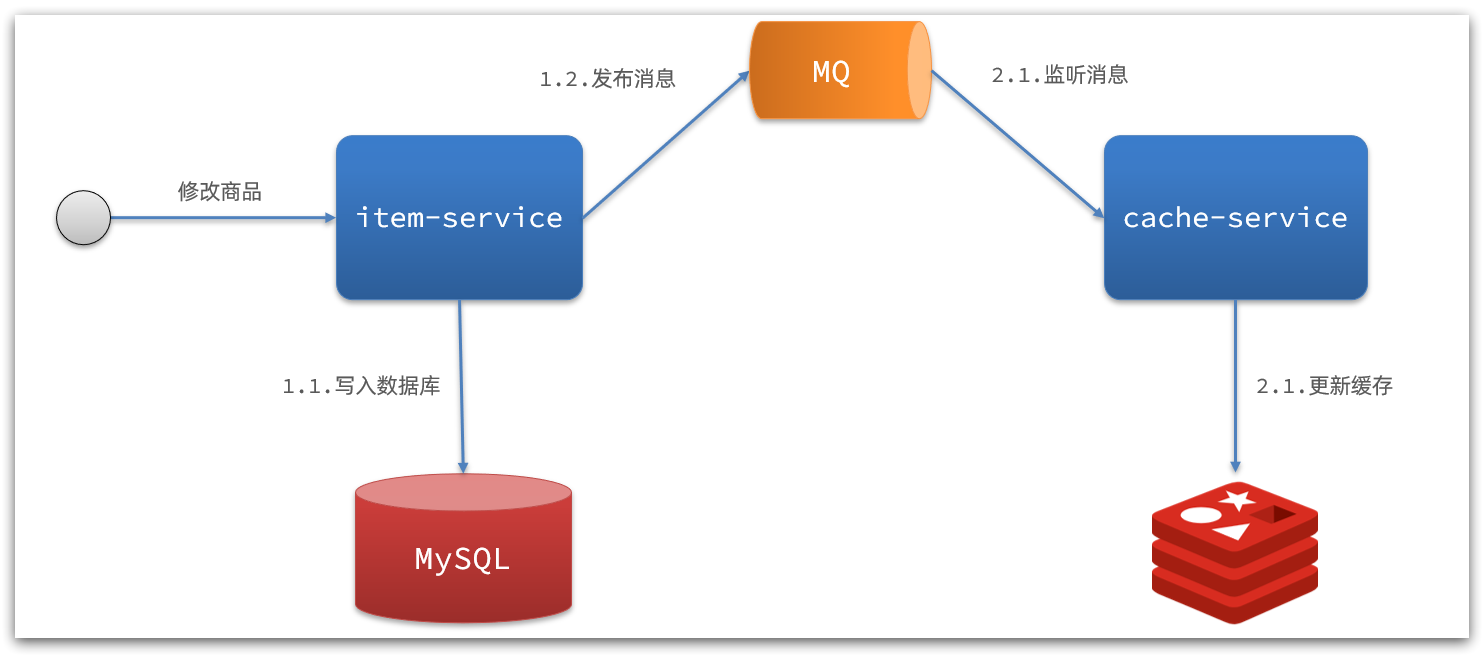
解读:
- 商品服务完成对数据的修改后,只需要发送一条消息到MQ中。
- 缓存服务监听MQ消息,然后完成对缓存的更新
依然有少量的代码侵入。
2)基于Canal的通知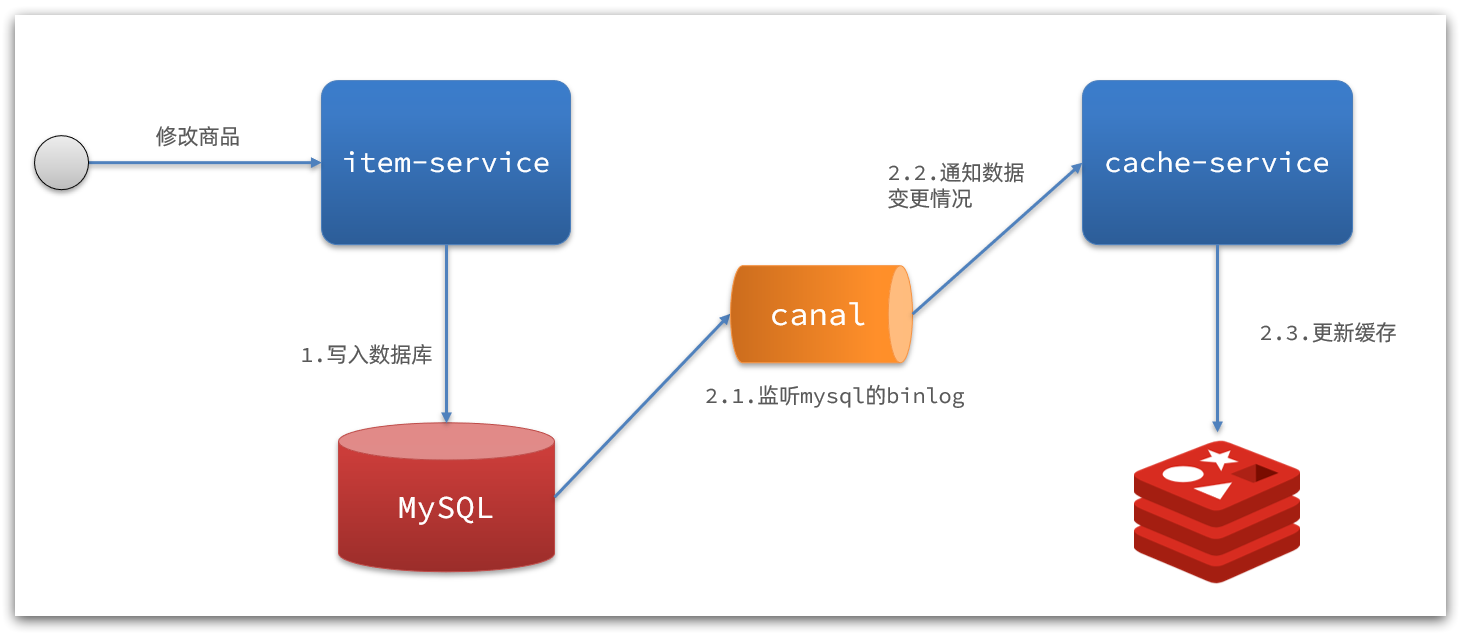
解读:
- 商品服务完成商品修改后,业务直接结束,没有任何代码侵入
- Canal监听MySQL变化,当发现变化后,立即通知缓存服务
- 缓存服务接收到canal通知,更新缓存
代码零侵入
五、Caffeine实现原理
1、简介
官方介绍Caffeine是基于JDK8的高性能本地缓存库,提供了几乎完美的命中率。它有点类似JDK中的ConcurrentMap,实际上,Caffeine中的LocalCache接口就是实现了JDK中的ConcurrentMap接口,但两者并不完全一样。最根本的区别就是,ConcurrentMap保存所有添加的元素,除非显示删除之(比如调用remove方法)。而本地缓存一般会配置自动剔除策略,为了保护应用程序,限制内存占用情况,防止内存溢出。
Caffeine提供了灵活的构造方法,从而创建可以满足如下特性的本地缓存:
- 自动把数据加载到本地缓存中,并且可以配置异步;
- 基于数量剔除策略;
- 基于失效时间剔除策略,这个时间是从最后一次访问或者写入算起;
- 异步刷新;
- Key会被包装成Weak引用;
- Value会被包装成Weak或者Soft引用,从而能被GC掉,而不至于内存泄漏;
- 数据剔除提醒;
- 写入广播机制;
缓存访问可以统计;
@Testvoid contextLoads() throws InterruptedException {Cache<String, String> cache = Caffeine.newBuilder()// 数量上限.maximumSize(1024)// 过期机制.expireAfterWrite(5, TimeUnit.SECONDS)// 弱引用key.weakKeys()// 弱引用value.weakValues()// 剔除监听.removalListener((RemovalListener<String, String>) (key, value, cause) ->System.out.println("key:" + key + ", value:" + value + ", 删除原因:" + cause.toString())).build();// 将数据放入本地缓存中cache.put("username", "afei");cache.put("password", "123456");// 从本地缓存中取出数据System.out.println(cache.getIfPresent("username"));System.out.println(cache.getIfPresent("password"));System.out.println(cache.get("blog", key -> {// 本地缓存没有的话,从数据库或者Redis中获取return "数据库取得数据";}));}}
当然,使用本地缓存时,我们也可以使用异步加载机制:
AsyncLoadingCache<String, String> cache = Caffeine.newBuilder()// 数量上限.maximumSize(2)// 失效时间.expireAfterWrite(5, TimeUnit.MINUTES).refreshAfterWrite(1, TimeUnit.MINUTES)// 异步加载机制.buildAsync(new CacheLoader<String, String>() {@Nullable@Overridepublic String load(@NonNull String key) throws Exception {return getValue(key);}});System.out.println(cache.get("username").get());System.out.println(cache.get("password").get(10, TimeUnit.MINUTES));System.out.println(cache.get("username").get(10, TimeUnit.MINUTES));System.out.println(cache.get("blog").get());
过期机制
本地缓存的过期机制是非常重要的,因为本地缓存中的数据并不像业务数据那样需要保证不丢失。本地缓存的数据一般都会要求保证命中率的前提下,尽可能的占用更少的内存,并可在极端情况下,可以被GC掉。
Caffeine的过期机制都是在构造Cache的时候申明,主要有如下几种:expireAfterWrite:表示自从最后一次写入后多久就会过期;
- expireAfterAccess:表示自从最后一次访问(写入或者读取)后多久就会过期;
- expireAfter:自定义过期策略;
刷新机制
在构造Cache时通过refreshAfterWrite方法指定刷新周期,例如refreshAfterWrite(10, TimeUnit.SECONDS)表示10秒钟刷新一次:
需要注意的是,Caffeine的刷新机制是「被动」的。举个例子,假如我们申明了10秒刷新一次。我们在时间T访问并获取到值v1,在T+5秒的时候,数据库中这个值已经更新为v2。但是在T+12秒,即已经过了10秒我们通过Caffeine从本地缓存中获取到的「还是v1」,并不是v2。在这个获取过程中,Caffeine发现时间已经过了10秒,然后会将v2加载到本地缓存中,下一次获取时才能拿到v2。即它的实现原理是在get方法中,调用afterRead的时候,调用refreshIfNeeded方法判断是否需要刷新数据。这就意味着,如果不读取本地缓存中的数据的话,无论刷新时间间隔是多少,本地缓存中的数据永远是旧的数据!.build(new CacheLoader<String, String>() {@Overridepublic String load(String k) {// 这里我们就可以从数据库或者其他地方查询最新的数据return getValue(k);}});
剔除机制
在构造Cache时可以通过removalListener方法申明剔除监听器,从而可以跟踪本地缓存中被剔除的数据历史信息。根据RemovalCause.java枚举值可知,剔除策略有如下5种:
- 「EXPLICIT」:调用方法(例如:cache.invalidate(key)、cache.invalidateAll)显示剔除数据;
- 「REPLACED」:不是真正被剔除,而是用户调用一些方法(例如:put(),putAll()等)盖了之前的值;
- 「COLLECTED」:表示缓存中的Key或者Value被垃圾回收掉了;
- 「EXPIRED」: expireAfterWrite/expireAfterAccess约定时间内没有任何访问导致被剔除;
- 「SIZE」:超过maximumSize限制的元素个数被剔除的原因;

若有收获,就点个赞吧
0 人点赞
