一 分布式系统框架
1.1 spring cloud
1.1.1 底层架构
它主要包括四个:
- 服务注册中心:比如 Eureka
- 服务注册中心,是分布式服务,或者是微服务的基础,没有他就谈不上分布式服务
- 服务调用:比如feign
- 这个他就是根据接口定义,然后帮我一个完成的http调用,一个很好用的调用工具
- 负载均衡:Ribbon
- 这个有很多机制,轮询,随机等等,一把结合接口调用使用,比如feign里面就嵌入了负载机制
- 网关:zuul Gatway nginx
- 这个就是统一处理的一个入口,最直接的,就是Url地址统一。
- 灰度发布、统一熔断、统一降级、统一缓存、统一限流、统一授权认证
下图结合场景模拟一个spring cloud的架构。订单系统、库存系统、仓储系统、积分系统
主要归纳2过程
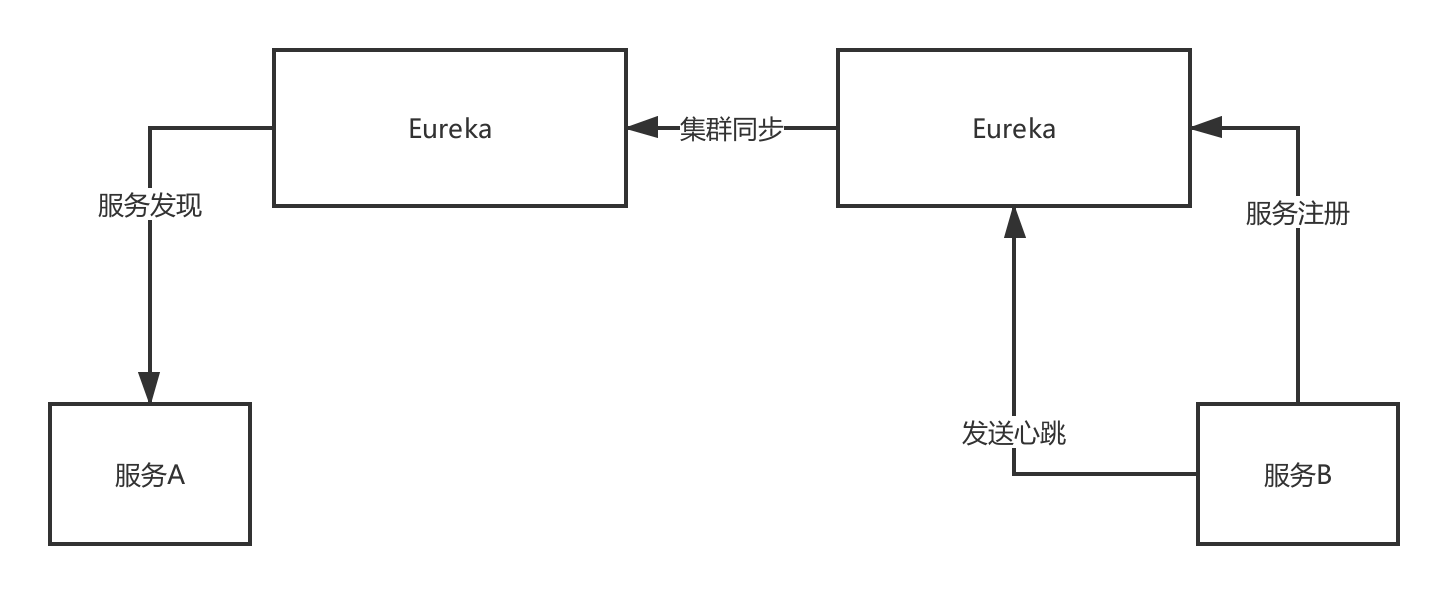
- 服务注册发现
- 首先将我们系统的四个微服务,注册到服务中心,比如说Eureka.
- 注册成功之后,每个子服务通过服务发现,定时的去服务中心拉取 服务注册表
- 服务中心通过心跳机制验证服务的存活
- 用户下单:
- 通过网关的路由分发,比如路由到订单系统
- 订单系统通过feign ,然后在通过Ribbon 负载均衡到库存,仓促和积分服务
1.2 dubbo
1.2.1 dubbo底层架构
- 服务注册中心 :
- dubbo 虽然没有提供默认的注册中心服务,但是提供接口,可以支持很多分布式协调组件 例如 zookeeper
- 消费者
- 动态代理 Proxy
- 负载均衡 Cluster,负载均衡,故障转移
- 注册中心 Registry
- 通信协议 Protocol,filter机制,http、rmi、dubbo等协议
- 网络通信:Transport,netty、mina
- 序列化:封装好的请求如何序列化成二进制数组,通过netty/mina发送出去
- 提供者
- 网络通信 Transport,基于netty/mina实现的Server
- 信息交换 Exchange,Response
- 通信协议 Protocol,filter机制
- 动态代理 Proxy
下图模拟一个借口调用来讲述:
主要分成两步:
- 服务注册与与发现
- 将服务提供者的信息注册到服务中心
- 服务消费者感知注册中心的注册列表
- 消费者发送接口请求
- 调用接口的动态代理对象
- 通过负载机制Cluster ,选择一台机器
- 主选通信协议,组织请求
- 封装请求为request
- 通过netty 进行nio通信,通信的数据要进行序列化
服务者接受请求
每个Boss NioEventLoop循环执行的步骤有3步:
- 轮询accept事件
- 处理accept事件,与client建立连接,生成NioSocketChannel,并将其注册到某个Worker NioEventLoop的selector上。
- 处理任务队列到任务,即runAllTasks
- 每个Worker NioEventLoop循环执行的步骤:
- 轮询read,write事件
- 处理I/O事件,即read,write事件,在对应的NioSocketChannel中进行处理
- 处理任务队列的任务,即runAllTasks
每个 Worker NioEventLoop处理业务时,会使用pipeline(管道),pipeline中维护了一个ChannelHandlerContext链表,而ChannelHandlerContext则保存了Channel相关的所有上下文信息,同时关联一个ChannelHandler对象。如图所示,Channel和pipeline一一对应,ChannelHandler和ChannelHandlerContext一一对应。
1.2.3 dubbo伸缩设计
是核心的组件全部接口化,组件和组件之间的调用,必须全部是依托于接口,去动态找配置的实现类,如果没有配置就用他自己默认的。
提供一种自己实现的组件的配置的方式,比如说你要是自己实现了某个组件,配置一下,人家到时候运行的时候直接找你配置的那个组件即可,作为实现类,不用自己默认的组件了。
1.3 对比
1.3.1 如何选型
Dubbo,RPC的性能比HTTP的性能更好,并发能力更强,经过深度优化的RPC服务框架,性能和并发能力是更好一些。例如Dubbo一次请求10ms,Spring Cloud耗费20ms
- 对很多中小型公司而言,性能、并发,并不是最主要的因素。Spring Cloud这套架构原理,走HTTP接口和HTTP请求,就足够满足性能和并发的需要了,没必要使用高度优化的RPC服务框架
- Dubbo之前的一个定位,就是一个单纯的服务框架而已,不提供任何其他的功能,配合的网关还得选择其他的一些技术
- Spring Cloud,中小型公司用的特别多,老系统从Dubbo迁移到Spring Cloud,新系统都是用Spring Cloud来进行开发,全家桶,主打的是微服务架构里,组件齐全,功能齐全。网关直接提供了,分布式配置中心,授权认证,服务调用链路追踪,Hystrix可以做服务的资源隔离、熔断降级、服务请求QPS监控、契约测试、消息中间件封装、ZK封装
Spring Cloud原来支持的一些技术慢慢的未来会演变为,跟阿里技术体系进行融合,Spring Cloud Alibaba,阿里技术会融入Spring Cloud里面去
1.3.2 如何设计一个RPC
要考虑下面几个因素:
动态代理
- 负载均衡
- 服务注册与发现
- 序列化机制
-
二 服务注册中心
服务注册与发现是分布式系统的核心,之核心,虽然有好多注册中心Eureka、ZooKeeper、Consul、Nacos,其实他们的原理都是类似的
存在元数据,即服务注册表
- 心跳机制检测存活

3.1 zookeeper
3.1.1 zk 高可用
ZooKeeper服务注册和发现的原理,它存在两种角色Leader + Follower,只有Leader可以负责写也就是服务注册,他可以把数据同步给Follower,读的时候leader/follower都可以读。
CAP,C是一致性,A是可用性,P是分区容错性
它保住了 CP**
- ZooKeeper是有一个leader节点会接收数据, 然后同步写其他节点,
- 一旦leader挂了,要重新选举leader,选举过程外部不可调用,这个过程里为了保证C,就牺牲了A,
不可用一段时间,但是一个leader选举好了,那么就可以继续写数据了,保证一致性
3.2 Eureka
3.2.1 Eureka 高可用
Eureka,peer-to-peer,部署一个集群,但是集群里每个机器的地位是对等的,各个服务可以向任何一个Eureka实例服务注册和服务发现,集群里任何一个Euerka实例接收到写请求之后,会自动同步给其他所有的Eureka实例
Eureka是peer模式,可能还没同步数据过去,结果自己就死了,此时还是可以继续从别的机器上拉取注册表,但是看到的就不是最新的数据了,但是保证了可用性,AP
3.2.2 Eureka 底层原理

化并发冲突
- eurake 它不是直接读服务注册表,而是做了,多级缓存,避免读写冲突
- 因为存在数据不一致问题,它又做了异步线程进行数据定时同步
3.3 zookeeper&Eureka对比
3.3.1 时效性优化
zk一般来说还好,服务注册和发现,都是很快的
eureka:必须优化参数
服务端:
//默认30秒,改成3秒定时同步一次
eureka.server.responseCacheUpdateIntervalMs = 3000
//默认60秒,改成每隔6秒去check
eureka.server.evictionIntervalTimerInMs = 6000
//默认90秒,线程每隔9秒去check 服务是否有心跳,没有心跳就干掉
eureka.instance.leaseExpirationDurationInSeconds = 9
自我保护机制关掉
客户端:
//拉取服务list3秒
eureka.client.registryFetchIntervalSeconds = 3000
//心跳间隔3秒
eureka.client.leaseRenewalIntervalInSeconds = 3
服务发现的时效性变成秒级,几秒钟可以感知服务的上线和下线3.3.2 部署优化
我们的机器是 eureka 是两台高可用,zk 是三台机器是 8核 16g**三 网关
它的核心功能:
动态路由:
- 新开发某个服务,动态把请求路径和服务的映射关系热加载到网关里去;服务增减机器,网关自动热感知
- 我们是为维护在mysql里的,可以在页面里面配置即可
- 灰度发布
- 授权认证
- 性能监控:每个API接口的耗时、成功率、QPS
- 系统日志
- 数据缓存
-
3.1 网关的高可用高并发
32核64G 2.5万 qps/s 10万qps=5台
16核32G 8千 qps/s 1万qps=3台 (我们是三台)
8核16G 3千 qps/s 1万qps=5台
动态路由:新开发某个服务,动态把请求路径和服务的映射关系热加载到网关里去;服务增减机器,网关自动热感知
灰度发布:基于现成的开源插件来做
性能监控:每个API接口的耗时、成功率、QPS3.2 网关-优化动态路由
数据库创建路由表
- 定时查询数据库的路由表
- 存储到路由表里
- routeLocator
-
3.3 1万+服务中心
其实这个很那实现
eureka:peer-to-peer,每台机器都是高并发请求,有瓶颈
- zookeeper:服务上下线,全量通知其他服务,网络带宽被打满,有瓶颈
- 分布式服务注册中心,分片存储服务注册表,横向扩容,每台机器均摊高并发请求,各个服务主动拉取,避免反向通知网卡被打满

3.4 灰度发布实现
在zuul里面加入下面的filter,可以在zuul的filter里定制ribbon的负载均衡策略, gray_release_config 设置flag 然后执行流量导入,它也是每隔5秒去获取数据的数据,是否需要灰度调度
3.5 生产实践
- 开发了一个新的服务,线上部署,配合网关动态路由的功能,在网关里配置一下路径和新服务的映射关系,此时请求过来直接就可以走到新的服务里去
对已有服务进行迭代和开发,新版本,灰度发布,新版本部署少数几台机器,通过一个界面,开启这个服务的灰度发布,此时zuul filter启用,按照你的规则,把少量的流量打入到新版本部署的机器上去,观察一下少量流量在新版本的机器上运行是否正常。版本改成current,全量机器部署,关闭灰度发布功能,网关就会把流量均匀分发给那个服务了。
四 超时重试幂等机制
Spring Cloud生产优化,系统第一次启动的时候,人家调用你经常会出现timeout?
4.1 饥饿加载 ribbon
每个服务第一次被请求的时候,他会去初始化一个Ribbon的组件,初始化这些组件需要耗费一定的时间,所以很容易会导致。让每个服务启动的时候就直接初始化Ribbon相关的组件,避免第一次请求的时候初始化
ribbon:eager-load:enabled: trueConnectTimeout: 3000ReadTimeout: 3000OkToRetryOnAllOperations: trueMaxAutoRetries: 1MaxAutoRetriesNextServer: 1
中小型的系统,没必要直接开启hystrix,资源隔离、熔断、降级,如果你没有设计好一整套系统高可用的方案
zuul请求一个订单服务,超过1秒就认为超时了,此时会先重试一下订单服务这台机器,如果还是不行就重试一下订单服务的其他机器4.2 幂等操作
4.2.1 数据库唯一索引
对于插入类的操作,一般都是建议大家要在数据库表中设计一些唯一索引
4.2.2 自我保证重复回滚机制
比如说一旦库存扣减成功之后,就立马要写一条数据到redis里去,order_id_11356_stock_deduct,写入redis中,如果写入成功,就说明之前这个订单的库存扣减,没人执行过
- 如果此时有一重试的请求,调用你的库存扣减接口,他同时也进行了库存的扣减,但是他用同样的一个key,order_id_11356_stock_deduct,写入redis中,此时会发现已经有人写过key,key已经存在
- 那么你直接对刚才的库存扣减逻辑做一个反向的回滚逻辑,update product_stock set stock = stock - 100,update product_stock set stock = stock + 100,反向逻辑,回滚掉,自己避免说重复扣减库存
五 分布式事务
5.1 seata tcc事务原理
它基于mysql里面创建一些表,基于表中的数据进行状态的更新

- 核心链路中的各个服务都需要跟TC这个角色进行频繁的网络通信,频繁的网络通信其实就会带来性能的开销,本来一次请求不引入分布式事务只需要100ms,此时引入了分布式事务之后可能需要耗费200ms
- 网络请求可能还挺耗时的,上报一些分支事务的状态给TC,seata-server,选择基于哪种存储来放这些分布式事务日志或者状态的,file,磁盘文件,MySQL,数据库来存放对应的一些状态
- 高并发场景下,seata-server 也需要支持扩容,也需要部署多台机器,用一个数据库来存放分布式事务的日志和状态的话,假设并发量每秒上万,分库分表,对TC背后的数据库也会有同样的压力,这个时候对TC背后的db也得进行分库分表,抗更高的并发压力
5.3 最终一致事务原理
六 分布式锁
6.1 分布式锁使用场景

创建一个订单,订单里会指定对哪些商品要购买多少件,此时就需要走一个流程,校验一下库存查库存,确认库存充足,锁定库存。这个过程必须用分布式锁,锁掉这个商品的库存,对一个商品的购买同一时间只能有一个人操作。6.2 redis 分布式锁-Redisson
Redisson框架,他基于Redis实现了一系列的开箱即用的高级功能,比如说分布式锁 redisson.lock(“product_1_stock”)
- 看门狗watchdog,redisson框架后台执行一段逻辑,每隔10s去检查一下这个锁是否还被当前客户端持有,如果是的话,重新刷新一下key的生存时间为30s
- 其他客户端尝试加锁,这个时候发现“product_1_stock”这个key已经存在了,里面显示被别的客户端加锁了,此时他就会陷入一个无限循环,阻塞住自己,不能干任何事情,必须在这里等待
- 第一个客户端加锁成功了,此时有两种情况,第一种情况,这个客户端操作完毕之后,主动释放锁;第二种情况,如果这个客户端宕机了,那么这个客户端的redisson框架之前启动的后台watchdog线程,就没了此时最多30s,key-value就消失了,自动释放了宕机客户端之前持有的锁
6.2.1 集群故障,分布式锁失效问题
虽然很难出现,但是有可能当主节点,宕机,从节点还没有获取锁,导致分布式锁失效,这个就麻烦了,很难搞,除非改源码,当主节点加锁成功,然后从节点成功才可以加锁成功。6.3 zk分布式锁-curator

6.4.1 单节点引发的羊群效应

如果几十个客户端同时争抢一个锁,此时会导致任何一个客户端释放锁的时候,zk反向通知几十个客户端,几十个客户端又要发送请求到zk去尝试创建锁,所以大家会发现,几十个人要加锁,大家乱糟糟的,无序的
羊群效应
造成很多没必要的请求和网络开销,会加重网络的负载6.4.2 脑裂
ZK有时候因为网路问题,任务A系统挂了,怎么临时节点删除,那么B系统加锁成功,这个时候锁失效。无解。6.5 分布式锁保证高并发
redis 抗个几万个qps 没问题6.5.1 分段加锁
分段加锁 + 合并扣减
你的苹果库存有10000个,此时你在数据库中创建10个库存字段,一个表里有10个库存字段,stock_01,stock_02,每个库存字段里放1000个库存,此时这个库存的分布式锁,对应10个key,product_1_stock_01,product_1_stock_02,请求过来之后,你从10个key随机选择一个key,去加锁就可以了,每秒过来1万个请求,此时他们会对10个库存分段key加锁,每个key就1000个请求,每台服务器就1000个请求而已。
6.5.2 丝芙兰的做法
直接是redis 直接内存操作,包括用户的下单操作,然后mq异步入库。

若有收获,就点个赞吧
0 人点赞
