前言
该文档主要为开发者提供一个参考,具体以官网为准,算是一个抛转引玉吧。
不论Kafka如何演变,万变不离其宗的是,它一定有一些外部的生产者(producer) 应用 程序给自己发送消息,然后还有一些外部的消费者 ( consumer) 应用程序读取 producer 发送的 消息。
一 生产者(producer)
简单来说,Kafka producer 就是负责向 Kafka 写入数据的应用程序。
Java 版本 producer 的工作原理。
producer 首先使用一个线程(用户主线程,也就是用户启动 producer 的线程) 将待发送的消息封装进一个 ProducerRecord 类实例,然后将其序列化之后发送给 partitioner, 再由后者确定了目标分区后一同发送到位于 producer 程序中的一块内存缓冲E中。而 producer 的另一个工作线程(I/O 发送线程,也称 Sender 线程)则负责实时地从该缓冲区中提取出准备 就绪的消息封装进一个批次(batch) ,统一发送给对应的 broker。整个 producer的工作流程大 概就是这样的。
1.1 springboot producer demo
- 新建个springboot(2.x) maven工程
- 引入需要的jar包
<dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-actuator</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>org.springframework.kafka</groupId><artifactId>spring-kafka</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope></dependency><dependency><groupId>org.springframework.kafka</groupId><artifactId>spring-kafka-test</artifactId><scope>test</scope></dependency></dependencies>
- 配置相关参数
spring:
kafka:
# 指定kafka server的地址,集群配多个,中间,逗号隔开
bootstrap-servers: 192.168.64.202:9092,192.168.64.202:9093,192.168.64.202:9094
producer:
# 写入失败时,重试次数。当leader节点失效,一个repli节点会替代成为leader节点,此时可能出现写入失败,
# 当retris为0时,produce不会重复。retirs重发,此时repli节点完全成为leader节点,不会产生消息丢失。
retries: 0
# 每次批量发送消息的数量,produce积累到一定数据,一次发送
batch-size: 5
# produce积累数据一次发送,缓存大小达到buffer.memory就发送数据
buffer-memory: 33554432
#procedure要求leader在考虑完成请求之前收到的确认数,用于控制发送记录在服务端的持久化,其值可以为如下:
#acks = 0 如果设置为零,则生产者将不会等待来自服务器的任何确认,该记录将立即添加到套接字缓冲区并视为已发送。在这种情况下,无法保证服务器已收到记录,并且重试配置将不会生效(因为客户端通常不会知道任何故障),为每条记录返回的偏移量始终设置为-1。
#acks = 1 这意味着leader会将记录写入其本地日志,但无需等待所有副本服务器的完全确认即可做出回应,在这种情况下,如果leader在确认记录后立即失败,但在将数据复制到所有的副本服务器之前,则记录将会丢失。
#acks = all 这意味着leader将等待完整的同步副本集以确认记录,这保证了只要至少一个同步副本服务器仍然存活,记录就不会丢失,这是最强有力的保证,这相当于acks = -1的设置。
#可以设置的值为:all, -1, 0, 1
acks: all
# 指定消息key和消息体的编解码方式
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.apache.kafka.common.serialization.StringSerializer
- 编写相关测试代码
package cn.sephora.producer.web;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.web.bind.annotation.*;
/**
* @author hezhaoming
* @date 2020/4/22
*/
@RestController
public class KafkaController {
public final KafkaTemplate kafkaTemplate;
public KafkaController(KafkaTemplate kafkaTemplate) {
this.kafkaTemplate = kafkaTemplate;
}
@GetMapping("/message/send")
public boolean send(@RequestParam String message){
kafkaTemplate.send("test",message);
return true;
}
}
- 跑起来测试

PS:我遇到过连不上 idea的程序连不上虚拟机的kafka,主要原因是:
- kafka 监听配置写成了127.0.0.1 ,应该改成具体的ip,如下

- 关闭防火墙
1.2 producer demo 相关说明
程序跑了起来,消息也能发送了,但是我们还是不能理解到底是怎么运行的,原理我在前面提过,我现在基于代码的层面说明下。其实主要说明干两件事,一个是构建消息,且把消息封装成ProducerRecord,另一个发送消息。
- 因为springboot是自动配置的,所以我需要找到关于kafka的配置
org.springframework.boot.autoconfigure.kafka.KafkaAutoConfiguration
KafkaAutoConfiguration 依据配置 KafkaProperties 去构建相关对象,比如KafkaTemplate ,这个是我们很常见的了。

- 我们调用比如KafkaTemplate.send的方法,这个方法干两件事,一个封装消息ProducerRecord

- 一个是发送消息。

- 红色的部分,我标注了,ProducerRecord多线程的处理,ListenableFuture 对发送异步回调的支持。
1.3 producer 主要参数说明
我们生产端,开发的时候,除了这几个参数:bootstarp.servers,key.serialier,value.serializer 还需要注意的几个参数的配置
acks
他是控制 producer 生产消息的持久性(durability)。
当acks=0,表示producer 不关心 leader broker端的处理结果,此时producer发送消息后,立即开启下一条消息的发送,根本不等待 leader broker端返回结果。因此它的吞吐量是最高的。
当acks=all||-1,此时producer发送消息后 ,leader broker不仅将消息写入日志,还会等待ISR中所有的其他副本都成功写入日志,才发送响应结果给producer ,因此他最大限度保证了数据不丢失,但是它的吞吐是最低的。
当acks=1,broker将消息写入日志后,便发送响应结果给producer,无需等待ISR中其他副本写入消息,理论上,如果 该 leader broker一直存活,则消息就不会丢失,他是消息可靠性和吞吐量一个折中的选择。
buffer.memory
该参数指定了producer端缓存消息的缓冲区大小33554432(32MB)。因为是异步发送,producer 先把即将发送的消息,缓存到缓冲区内,然后由另一个线程负责发送。若 producer 写到 缓冲区的消息速度超过,发送的速度,则会使得缓冲区空间不断扩大
此时,producer 会停止工作等待 发送线程 发送消息。如果还是追不上,那么producer 会抛出异常,期望人工接入
compression.type
参数设置 producer 端是否压缩消息,默认值是 none, 即不压缩消息。
推荐使用Zstandard算法,他是效率最高的。
retries
错误重试,处理写入请求时可能因为瞬时的故障(比如瞬时的 leader 选举或者网络抖 动)导致消息发送失败,默认重试0 ,实际业务中设置是大于0的。
消息重发意味着,出现两个问题。
- 消息重复 [消费端设计幂等处理]
- 消息的乱序[producer 端设置 max.in.flight.requets.perconnection 参数。 一旦用户将此参数设置成 1,producer 将确保某一时刻只能发送一个请求]
此外,重试之间的时间间隔可以设置的etry.backoff.ms 默认是100毫秒。
batch.size
batch.size 是 producer 最重要的参数之一!它对于调优 producer 吞吐量和延时性能指标都 有着非常重要的作用。
batch.size 参数默认值是 16384, 即 16KB,
通常来说,一个小的 batch 中包含的消息数很少,因 而一次发送请求能够写入的消息数也很少,所以 producer 的吞吐量会很低;但若一个 batch 非 常之巨大,那么会给内存使用带来极大的压力,因为不管是否能够填满,producer 都会为该 batch 分配固定大小的内存。因此 batch.size 参数的设置其实是一种时间与空间权衡的体现。
linger.ms
linger.rns 参数就是控制消息发送延时行为的。该参数默认值是 0, 表示消息需要被立即 发送,无须关心 batch 是否已被填满,大多数情况下这是合理的,毕竟我们总是希望消息被尽 可能快地发送。不过这样做会拉低 producer 吞吐量,毕竟 producer 发送的每次请求中包含的消 息数越多,producer 就越能将发送请求的开销摊薄到更多的消息上,从而提升吞吐量
建议 100毫秒
max.request.size
该参数用于控制 producer 发送请求的大小
:默认:1048576 建议值:10485760
request.timeout.ms
当 producer 发送请求给 broker 后,broker 需要在规定的时间范围内将处理结果返还给 producer。这段时间便是由该参数控制的,
默认 30 秒 建议:60秒
1.4 消息分区机制
Kafka producer 提供了分区策略以及对应的分区器 ( partitioner) 供用户使用. partitioner 会尽力确保具有相同 key 的所有消息都会被发送到相同的分区上;若没有为消 息指定 key,则该 partitioner 会选择轮询的方式来确保消息在 topic 的所有分区上均勾分配.
1.4.1 自定义分区机制
如果producer没指定落地到指定partition中,Kafak通过默认的分区器对数据进行partition,默认的分区的规则是对key进行hash取值 % 分区数, 相同的key会分布到同一分区中。如果没指定key,则就按照轮询算法将消息均匀的分布在主题的可用分区上。
- 实现分区器接口(partitioner) ``` package cn.sephora.config;
import org.apache.kafka.clients.producer.Partitioner; import org.apache.kafka.common.Cluster;
import java.util.Map;
/**
- @author hezhaoming
@date 2020/4/24 */ public class MyPartitioner implements Partitioner {
@Override public int partition(String s, Object o, byte[] bytes, Object o1, byte[] bytes1, Cluster cluster) {
//编写自己分区规则 int numPartitions =cluster.partitionCountForTopic(s); // 让所有数据都写到0分区中 return 0;}
@Override public void close() { }
@Override public void configure(Map
}
}
- 配置自定义的配置
package cn.sephora.config;
import lombok.extern.slf4j.Slf4j; import org.apache.kafka.clients.consumer.ConsumerConfig; import org.apache.kafka.clients.producer.ProducerConfig; import org.apache.kafka.common.serialization.StringDeserializer; import org.apache.kafka.common.serialization.StringSerializer; import org.springframework.beans.factory.annotation.Value; import org.springframework.boot.context.properties.ConfigurationProperties; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; import org.springframework.kafka.annotation.EnableKafka; import org.springframework.kafka.core.DefaultKafkaProducerFactory; import org.springframework.kafka.core.KafkaTemplate; import org.springframework.kafka.core.ProducerFactory;
import java.util.HashMap; import java.util.Map;
/**
- @author hezhaoming
@date 2020/4/24 */ @Configuration @Slf4j public class KafkaConfiguration {
@Value(“${spring.kafka.bootstrap-servers}”) private String bootstrapServers;
@Value(“${spring.kafka.consumer.enable-auto-commit}”) private Boolean autoCommit;
@Value(“${spring.kafka.consumer.auto-commit-interval}”) private Integer autoCommitInterval;
@Value(“${spring.kafka.consumer.group-id}”) private String groupId;
@Value("${spring.kafka.consumer.auto-offset-reset}")
private String autoOffsetReset;
/**
* 消息发送失败重试次数
*/
@Value("${spring.kafka.producer.retries}")
private int retries;
/**
* 消息批量发送容量
*/
@Value("${spring.kafka.producer.batch-size}")
private int batchSize;
/**
* 缓存容量
*/
@Value("${spring.kafka.producer.buffer-memory}")
private int bufferMemory;
/**
* 消费者配置信息
*/
@Bean
public Map<String, Object> consumerConfigs() {
log.info("Kafka消费者配置");
Map<String, Object> props = new HashMap<>();
props.put(ConsumerConfig.GROUP_ID_CONFIG, groupId);
props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, autoOffsetReset);
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);
props.put(ConsumerConfig.SESSION_TIMEOUT_MS_CONFIG, 120000);
props.put(ConsumerConfig.REQUEST_TIMEOUT_MS_CONFIG, 180000);
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
return props;
}
/**
* 生产者相关配置
* @return
*/
public Map<String, Object> producerConfigs() {
log.info("Kafka生产者配置");
Map<String, Object> props = new HashMap<>(6);
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);
props.put(ProducerConfig.RETRIES_CONFIG, retries);
props.put(ProducerConfig.BATCH_SIZE_CONFIG, batchSize);
props.put(ProducerConfig.BUFFER_MEMORY_CONFIG, bufferMemory);
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
props.put(ProducerConfig.PARTITIONER_CLASS_CONFIG, MyPartitioner.class);
return props;
}
/**
* 生产者创建工厂
* @return
*/
public ProducerFactory<String, String> producerFactory() {
return new DefaultKafkaProducerFactory<>(producerConfigs());
}
/**
* kafkaTemplate 覆盖默认配置类中的kafkaTemplate
* @return
*/
@Bean
public KafkaTemplate<String, String> kafkaTemplate() {
return new KafkaTemplate<String, String>(producerFactory());
}
}
- 发送几条消息试试
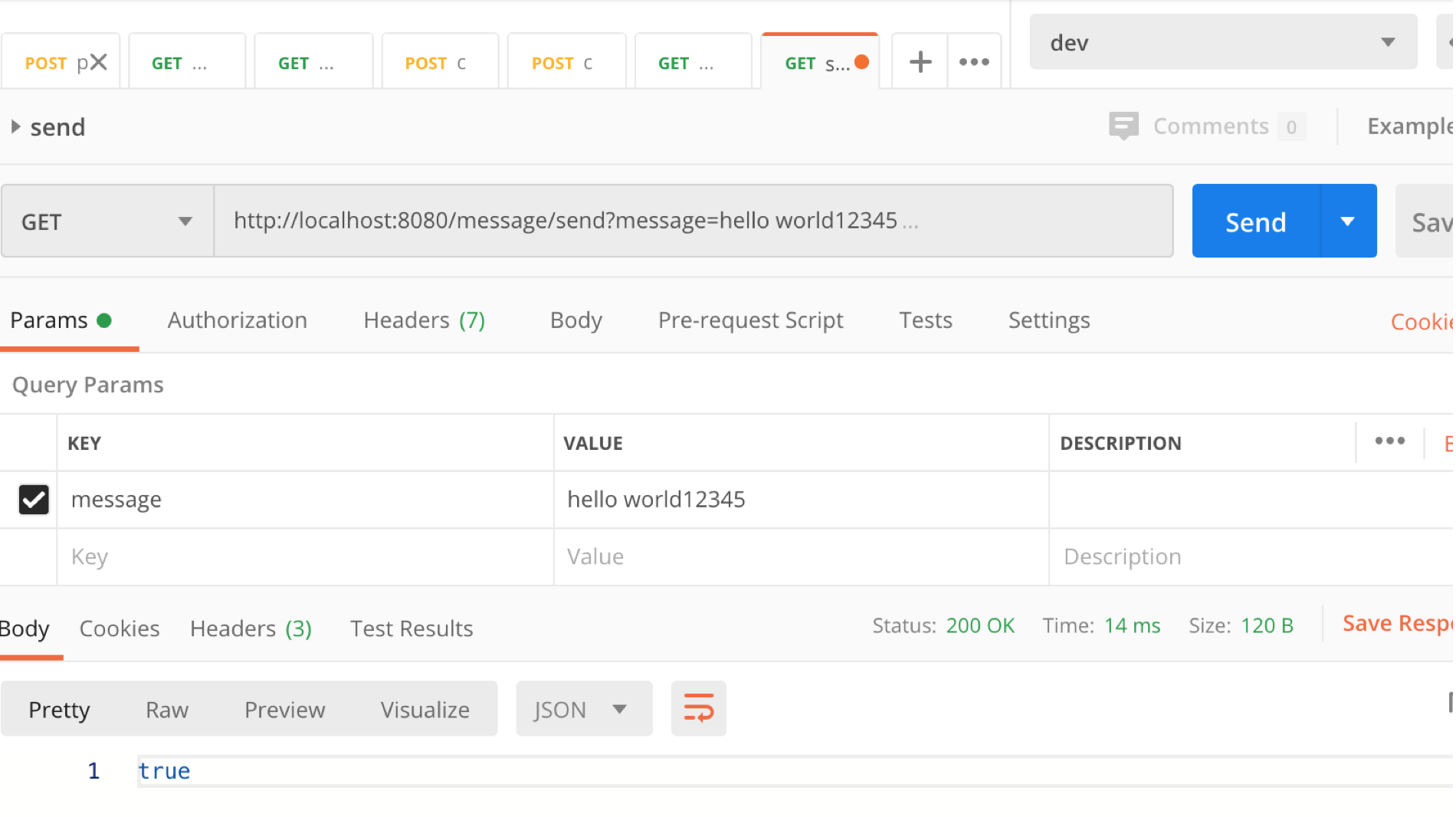
bin/kafka-run-class.sh kafka.tools.GetOffsetShell —broker-list 192.168.64.202:9092,192.168.64.202:9093,192.168.64.202:9094 —topic test

<a name="b60284ce"></a>
## 1.5 消息序列化
在网络中发送数据都是以字节的方式,Kafka 也不例外。Apache Kaflca 支持用户给 broker 发送各种类型的消息。因此需要序列化数据<br />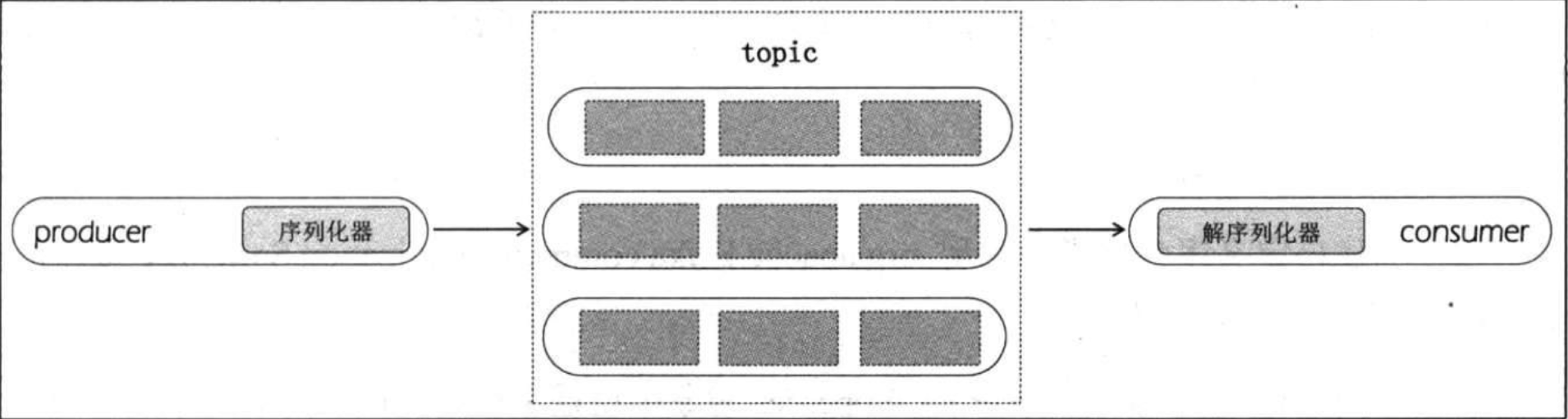
<a name="5164cbb9"></a>
### 1.5.1 自定义序列化
不建议自定义
<a name="161a3c6f"></a>
## 1.6 producer 拦截器
interceptor(拦截器) 使得用户在消息发送前以及 producer 回调逻辑前有机会对 消息做一些定制化需求,比如修改消息等
- onSend(ProducerRecord): 该方法封装进 KafkaProducensend 方法中,即它运行在用户 主线程中。producer 确保在消息被序列化以计算分区前调用该方法。用户可以在该方 法中对消息做任何操作,但最好保证不要修改消息所属的 topic 和分区,否则会影响目 标分区的计算。
- onAcknowledgement RecordMetadata,Exception: 该方法会在消息被应答之前或消息发送失败时调用,并且通常都是在 producer 回调逻辑触发之前。onAcknowledgement 运 行在 producer 的 I/O 线程中,因此不要在垓方法中放入很“重”的逻辑,否则会拖慢 producer 的消息发送效率。
- close:关闭 interceptor,主要用于执行一些资源清理工作
1. 实现接口 ProducerInterceptor
package cn.sephora.config;
import org.apache.kafka.clients.producer.ProducerInterceptor; import org.apache.kafka.clients.producer.ProducerRecord; import org.apache.kafka.clients.producer.RecordMetadata;
import java.util.Map;
/**
- @author hezhaoming
- @date 2020/4/24 */ public class TimeStampPrependerlnterceptor implements ProducerInterceptor {
/**
* 该方法封装进 KafkaProducensend 方法中,即它运行在用户 主线程中。
* producer 确保在消息被序列化以计算分区前调用该方法。
* 用户可以在该方 法中对消息做任何操作,但最好保证不要修改消息所属的 topic 和分区,否则会影响目 标分区的计算。
* @author hezhaoming
* @date 2020/4/24
*/
@Override
public ProducerRecord onSend(ProducerRecord record) {
return new ProducerRecord(record.topic(),
record.partition(),
record.timestamp(),
record.key(),
System.currentTimeMillis() + "," + record.value());
}
/**
* 该方法会在消息被应答之前或消息发送失败时调用,并且通常都是在 producer 回调逻辑触发之前。
* onAcknowledgement 运行在 producer 的 I/O 线程中,因此不要在垓方法中放入很“重”的逻辑,否则会拖慢 producer 的消息发送效率。
* @param recordMetadata
* @param e
*/
@Override
public void onAcknowledgement(RecordMetadata recordMetadata, Exception e) {
}
/**
* 关闭 interceptor,主要用于执行一些资源清理工作
*/
@Override
public void close() {
}
@Override
public void configure(Map<String, ?> map) {
}
}
2. 添加配置
List<String> list=new ArrayList<String>();
list.add("cn.sephora.config.TimeStampPrependerlnterceptor");
list.add("cn.sephora.config.Countnterceptor");
props.put(ProducerConfig.INTERCEPTOR_CLASSES_CONFIG,list);
```

1.7 无消息丢失配置
producer 端配置
- max.block.ms=true 表示 内存缓存区被填满时producer 处于阻塞状态,而不是抛出异常。
- acks=all 表示最强持久化保证,必须等到所有的follower 响应
- retries=Integer.MAX_VALUE 表示 无线重试 可恢复的异常。
- max.in.flight.requests.per.connection=1 表示防止乱序,即producer在某个broker发送响应之前,无法再给该broker 发送消息。
使用带有回调的send ,如果没有回调,则发送失败,send 方法无法感知。
6.Callback 逻辑中显示的立即关闭producer ,如果不立即关闭,可能造成消息乱序。broker 端配置
unclean.leader.election.enable=false
关闭 unclean leader 选举,即不允许非 ISR 中的副本被选举为 leader,从而避免 broker 端因 日志水位截断而造成的消息丢失
2. replication.factor=3
一定要使 用多个副本来保存消息
3. min.insync.replicas=2
用于控制某条消息至少被写入到 ISR 中的多少个副本才算成功,设置成大于 1 是为了提升 producer 端发送语义的持久性。记住只有在 producer 端 acks 被设置成 all 或 时 ,这 个 参 数 才
有意义。在实际使用时,不要使用默认值
4. replication.factor>min.insync.replicas
推荐配置replication.factor=min.insync.replicas+1
5. enable.auto.commit=false
1.8 消息压缩
1.9 多线程处理

如果是对分区数不多的 Kafka集群而言,比较推荐使用第一种方法,即在多个 producer 用户线程中共享一个 KafkaProducer 实例。若是对那些拥有超多分区的集群而言,采 用第二种方法具有较高的可控性,方便 producer 的后续管理
二 消费者(consumer)开发
2.1 spring boot consumer demo
启动一个demo

若有收获,就点个赞吧
0 人点赞
