一 为啥要分库分表
- mysql 单机扛不住并发,
- mysql 磁盘快满了
- mysql单表数据量太大,sql越跑越慢
一般单表数据过500万+就考虑分表分库了。
例如单表数据1千万数据:我们拆分成3个库:
- 每个库就是300万数据,磁盘压力减轻
- 并发量提高三倍
-
二 分库分表中间件
2.1 shardingsphere
这种client层方案的优点在于不用部署,运维成本低,不需要代理层的二次转发请求,性能很高,但是如果遇到升级啥的需要各个系统都重新升级版本再发布,各个系统都需要耦合sharding-jdbc的依赖;
2.2 mycat
这种proxy层方案的缺点在于需要部署,自己及运维一套中间件,运维成本高,但是好处在于对于各个项目是透明的,如果遇到升级之类的都是自己中间件那里搞就行了。
2.2.1 原理
Mycat的原理中最重要的一个动词是“拦截”,它拦截了用户发送过来的SQL语句,首先对SQL语句做了一些特定的分析:如分片分析、路由分析、读写分离分析、缓存分析等,然后将此SQL发往后端的真实数据库,并将返回的结果做适当的处理,最终再返回给用户。

三 数据库如何拆分
3.1 垂直拆分
拆字段:
就是把一个有很多字段的表给拆分成多个表,或者是多个库上去。每个库表的结构都不一样,每个库表都包含部分字段。一般来说,会将较少的访问频率很高的字段放到一个表里去,然后将较多的访问频率很低的字段放到另外一个表里去。因为数据库是有缓存的,你访问频率高的行字段越少,就可以在缓存里缓存更多的行,性能就越好。这个一般在表层面做的较多一些。3.2 水平拆分
拆数据:即数据分片
就是把一个表的数据给弄到多个库的多个表里去,但是每个库的表结构都一样,只不过每个库表放的数据是不同的,所有库表的数据加起来就是全部数据。水平拆分的意义,就是将数据均匀放更多的库里,然后用多个库来抗更高的并发,还有就是用多个库的存储容量来进行扩容。3.2.1 hash路由拆分
根据业务对关键字段hash 取模路由到不同的数据库去。
好处:
可以平均分配没给库的数据量和请求压力
坏处:
扩容起来比较麻烦,会有一个数据迁移的这么一个过程3.2.2 range范围拆分
就是每个库一段连续的数据,这个一般是按比如时间范围来的,但是这种一般较少用,因为很容易产生热点问题,大量的流量都打在最新的数据上了。
好处:
后面扩容的时候,就很容易,因为你只要预备好,给每个月都准备一个库就可以了,到了一个新的月份的时候,自然而然,就会写新的库了。
坏处:
大部分的请求,都是访问最新的数据。实际生产用range,要看场景,你的用户不是仅仅访问最新的数据,而是均匀的访问现在的数据以及历史的数据四 分库分表迁移
4.1 停机分表分库
停机:此时老单库单表数据库没有数据写入。然后你写一个导入数据的工具,将单库单表的数据写到分库分表里面去。
4.2 双写迁移方案
将线上库原来写的地方,同时写到新的数据库中,这就是所谓双写,即:同时写俩库,老库和新库。
数据相差太大:我可以搞个写个工具进行读老库数据写新库,写的时候要根据gmt_modified字段判断这条数据最后修改的时间,除非是读出来的数据在新库里没有,或者是比新库的数据新才会写。
- 数据少许不一致:如果比较一轮之后数据依然不一致,那么比对新老库每个表的每条数据,如果有不一样的,就针对那些不一样的,从老库读数据再次写。反复循环,直到两个库每个表的数据都完全一致为止。
数据一致:当数据一致后,重新发布,走新库即可,这个过程就很快,不需要停机很久。很稳。
五 动态扩容
5.1 停机扩容
这个方案就跟停机迁移一样,步骤几乎一致,唯一的一点就是那个导数的工具,是把现有库表的数据抽出来慢慢倒入到新的库和表里去。
从单库单表迁移到分库分表的时候,数据量并不是很大,单表最大也就两三千万。写个工具,多弄几台机器并行跑,1小时数据就导完了
3个库+12个表,跑了一段时间了,数据量都1亿~2亿了。光是导2亿数据,都要导个几个小时,6点,刚刚导完数据,还要搞后续的修改配置,重启系统,测试验证,10点才可以搞
5.2 预先分配
一开始上来就是32个库,每个库32个表,1024张表。这个分法,第一,基本上国内的互联网肯定都是够用了,第二,无论是并发支撑还是数据量支撑都没问题。
每个库正常承载的写入并发量是1000,那么32个库就可以承载32 1000 = 32000的写并发,如果每个库承载1500的写并发,32 1500 = 48000的写并发,接近5万/s的写入并发,前面再加一个MQ,削峰,每秒写入MQ 8万条数据,每秒消费5万条数据。
- 有些除非是国内排名非常靠前的这些公司,他们的最核心的系统的数据库,可能会出现几百台数据库的这么一个规模,128个库,256个库,512个库
- 1024张表,假设每个表放500万数据,在MySQL里可以放50亿条数据。每秒的5万写并发,总共50亿条数据,对于国内大部分的互联网公司来说,其实一般来说都够了
- 谈分库分表的扩容,第一次分库分表,就一次性给他分个够,32个库,1024张表,可能对大部分的中小型互联网公司来说,已经可以支撑好几年了
PS:
- 其实这里的动态扩容只是扩容的机器,不能改变库和表的数量,不然还得重新路由,重新处理数据。
- 这种方式不需要迁移数据,只需要迁移库就好,dba也方便操作
5.3 升级从库
线上数据库,我们为了保持其高可用,一般都会每台主库配一台从库,读写在主库,然后主从同步到从库。如下,A,B是主库,A0和B0是从库。
线上数据库,我们为了保持其高可用,一般都会每台主库配一台从库,读写在主库,然后主从同步到从库。如下,A,B是主库,A0和B0是从库。
此时,当需要扩容的时候,我们把A0和B0升级为新的主库节点,如此由2个分库变为4个分库。同时在上层的分片配置,做好映射,规则如下:uid%4=0和uid%4=2的分别指向A和A0,也就是之前指向uid%2=0的数据,分裂为uid%4=0和uid%4=2 uid%4=1和uid%4=3的指向B和B0,也就是之前指向uid%2=1的数据,分裂为uid%4=1和uid%4=3
因为A和A0库的数据相同,B和B0数据相同,所以此时无需做数据迁移即可。只需要变更一下分片配置即可,通过配置中心更新,无需重启。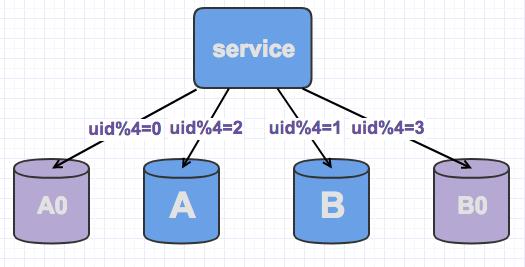
由于之前uid%2的数据分配在2个库里面,此时分散到4个库中,由于老数据还存在(uid%4=0,还有一半uid%4=2的数据),所以需要对冗余数据做一次清理。而这个清理,不会影响线上数据的一致性,可是随时随地进行。
处理完成以后,为保证高可用,以及下一步扩容需求。可以为现有的主库再次分配一个从库。
总结一下此方案步骤如下:
- 修改分片配置,做好新库和老库的映射。
- 同步配置,从库升级为主库
- 解除主从关系
- 冗余数据清理
- 为新的数据节点搭建新的从库
六 分布式ID
6.1 数据库ID
专门开一个服务出来,这个服务每次就拿到当前id最大值,然后自己递增几个id,一次性返回一批id,然后再把当前最大id值修改成递增几个id之后的一个值;但是无论怎么说都是基于单个数据库。
适合的场景: 并发很低,几百/s,但是数据量大,几十亿的数据,所以需要靠分库分表来存放海量的数据。
6.2 基于UUID
在Java的世界里,想要得到一个具有唯一性的ID,首先被想到可能就是UUID,毕竟它有着全球唯一的特性。那么UUID可以做分布式ID吗?是可以的,但是并不推荐!
public static void main(String[] args) {String uuid = UUID.randomUUID().toString().replaceAll("-","");System.out.println(uuid);}
UUID的生成简单到只有一行代码,输出结果 c2b8c2b9e46c47e3b30dca3b0d447718,但UUID却并不适用于实际的业务需求。像用作订单号UUID这样的字符串没有丝毫的意义,看不出和订单相关的有用信息;而对于数据库来说用作业务主键ID,它不仅是太长还是字符串,存储性能差查询也很耗时,所以不推荐用作分布式ID。
优点:
- 生成足够简单,本地生成无网络消耗,具有唯一性
缺点:
- 无序的字符串,不具备趋势自增特性
- 没有具体的业务含义
- 长度过长16 字节128位,36位长度的字符串,存储以及查询对MySQL的性能消耗较大,MySQL官方明确建议主键要尽量越短越好,作为数据库主键 UUID 的无序性会导致数据位置频繁变动,严重影响性能。
6.3 snowflake算法
twitter开源的分布式id生成算法,就是把一个64位的long型的id,1个bit是不用的,用其中的41 bit作为毫秒数,用10 bit作为工作机器id,12 bit作为序列号。
整数标识(0)+毫秒数(41)+机器id(10)+序列号(12)=64
- 1 bit:不用,因为二进制里第一个bit为如果是1,那么都是负数,但是我们生成的id都是正数,所以第一个bit统一都是0
- 41 bit:表示的是时间戳,单位是毫秒。41 bit可以表示的数字多达2^41 - 1,也就是可以标识2 ^ 41 - 1个毫秒值,换算成年就是表示69年的时间。
- 10 bit:记录工作机器id,代表的是这个服务最多可以部署在2^10台机器上哪,也就是1024台机器。但是10 bit里5个bit代表机房id,5个bit代表机器id。意思就是最多代表2 ^ 5个机房(32个机房),每个机房里可以代表2 ^ 5个机器(32台机器)。
- 12 bit:这个是用来记录同一个毫秒内产生的不同id,12 bit可以代表的最大正整数是2 ^ 12 - 1 = 4096,也就是说可以用这个12bit代表的数字来区分同一个毫秒内的4096个不同的id
64位的long型的id,64位的long -> 二进制
例如:
- 2018-01-01 10:00:00 -> 做了一些计算,再换算成一个二进制,41bit来放 -> 0001100 10100010 10111110 10001001 01011100 00
- 机房id,17 -> 换算成一个二进制 -> 10001
- 机器id,25 -> 换算成一个二进制 -> 11001
结果:
0 | 0001100 10100010 10111110 10001001 01011100 00 | 10001 | 1 1001 | 0000 00000000
snowflake算法服务,会判断一下,当前这个请求是否是,机房17的机器25,在2175/11/7 12:12:14时间点发送过来的第一个请求,如果是第一个请求
假设,在2175/11/7 12:12:14时间里,机房17的机器25,发送了第二条消息,snowflake算法服务,会发现说机房17的机器25,在2175/11/7 12:12:14时间里,在这一毫秒,之前已经生成过一个id了,此时如果你同一个机房,同一个机器,在同一个毫秒内,再次要求生成一个id,此时我只能把加1
0 | 0001100 10100010 10111110 10001001 01011100 00 | 10001 | 1 1001 | 0000 00000001
public class IdWorker{private long workerId;private long datacenterId;private long sequence;public IdWorker(long workerId, long datacenterId, long sequence){// sanity check for workerId// 这儿不就检查了一下,要求就是你传递进来的机房id和机器id不能超过32,不能小于0if (workerId > maxWorkerId || workerId < 0) {throw new IllegalArgumentException(String.format("worker Id can't be greater than %d or less than 0",maxWorkerId));}if (datacenterId > maxDatacenterId || datacenterId < 0) {throw new IllegalArgumentException(String.format("datacenter Id can't be greater than %d or less than 0",maxDatacenterId));}System.out.printf("worker starting. timestamp left shift %d, datacenter id bits %d, worker id bits %d, sequence bits %d, workerid %d",timestampLeftShift, datacenterIdBits, workerIdBits, sequenceBits, workerId);this.workerId = workerId;this.datacenterId = datacenterId;this.sequence = sequence;}private long twepoch = 1288834974657L;private long workerIdBits = 5L;private long datacenterIdBits = 5L;private long maxWorkerId = -1L ^ (-1L << workerIdBits); // 这个是二进制运算,就是5 bit最多只能有31个数字,也就是说机器id最多只能是32以内private long maxDatacenterId = -1L ^ (-1L << datacenterIdBits); // 这个是一个意思,就是5 bit最多只能有31个数字,机房id最多只能是32以内private long sequenceBits = 12L;private long workerIdShift = sequenceBits;private long datacenterIdShift = sequenceBits + workerIdBits;private long timestampLeftShift = sequenceBits + workerIdBits + datacenterIdBits;private long sequenceMask = -1L ^ (-1L << sequenceBits);private long lastTimestamp = -1L;public long getWorkerId(){return workerId;}public long getDatacenterId(){return datacenterId;}public long getTimestamp(){return System.currentTimeMillis();}public synchronized long nextId() {// 这儿就是获取当前时间戳,单位是毫秒long timestamp = timeGen();if (timestamp < lastTimestamp) {System.err.printf("clock is moving backwards. Rejecting requests until %d.", lastTimestamp);throw new RuntimeException(String.format("Clock moved backwards. Refusing to generate id for %d milliseconds",lastTimestamp - timestamp));}// 0// 在同一个毫秒内,又发送了一个请求生成一个id,0 -> 1if (lastTimestamp == timestamp) {sequence = (sequence + 1) & sequenceMask; // 这个意思是说一个毫秒内最多只能有4096个数字,无论你传递多少进来,这个位运算保证始终就是在4096这个范围内,避免你自己传递个sequence超过了4096这个范围if (sequence == 0) {timestamp = tilNextMillis(lastTimestamp);}} else {sequence = 0;}// 这儿记录一下最近一次生成id的时间戳,单位是毫秒lastTimestamp = timestamp;// 这儿就是将时间戳左移,放到41 bit那儿;将机房id左移放到5 bit那儿;将机器id左移放到5 bit那儿;将序号放最后10 bit;最后拼接起来成一个64 bit的二进制数字,转换成10进制就是个long型return ((timestamp - twepoch) << timestampLeftShift) |(datacenterId << datacenterIdShift) |(workerId << workerIdShift) |sequence;}private long tilNextMillis(long lastTimestamp) {long timestamp = timeGen();while (timestamp <= lastTimestamp) {timestamp = timeGen();}return timestamp;}private long timeGen(){return System.currentTimeMillis();}//---------------测试---------------public static void main(String[] args) {IdWorker worker = new IdWorker(1,1,1);for (int i = 0; i < 30; i++) {System.out.println(worker.nextId());}}}
6.4 基于Redis模式
Redis也同样可以实现,原理就是利用redis的 incr命令实现ID的原子性自增。
127.0.0.1:6379> set seq_id 1 // 初始化自增ID为1
OK
127.0.0.1:6379> incr seq_id // 增加1,并返回递增后的数值
(integer) 2
用redis实现需要注意一点,要考虑到redis持久化的问题。redis有两种持久化方式RDB和AOF
- RDB会定时打一个快照进行持久化,假如连续自增但redis没及时持久化,而这会Redis挂掉了,重启Redis后会出现ID重复的情况。
- AOF会对每条写命令进行持久化,即使Redis挂掉了也不会出现ID重复的情况,但由于incr命令的特殊性,会导致Redis重启恢复的数据时间过长。
6.5 基于数据库的号段模式
号段模式是当下分布式ID生成器的主流实现方式之一,号段模式可以理解为从数据库批量的获取自增ID,每次从数据库取出一个号段范围,例如 (1,1000] 代表1000个ID,具体的业务服务将本号段,生成1~1000的自增ID并加载到内存。表结构如下:CREATE TABLE id_generator ( id int(10) NOT NULL, max_id bigint(20) NOT NULL COMMENT '当前最大id', step int(20) NOT NULL COMMENT '号段的布长', biz_type int(20) NOT NULL COMMENT '业务类型', version int(20) NOT NULL COMMENT '版本号', PRIMARY KEY (`id`) )

等这批号段ID用完,再次向数据库申请新号段,对max_id字段做一次update操作,update max_id= max_id + step,update成功则说明新号段获取成功,新的号段范围是(max_id ,max_id +step]。
update id_generator set max_id = #{max_id+step}, version = version + 1 where version = # {version} and biz_type = XXX
由于多业务端可能同时操作,所以采用版本号version乐观锁方式更新,这种分布式ID生成方式不强依赖于数据库,不会频繁的访问数据库,对数据库的压力小很多。
6.6 zookeeper的分布式id生成器
实现方式有两种,一种通过节点,一种通过节点的版本号
- 节点的特性,持久顺序节点(PERSISTENT_SEQUENTIAL)。他的基本特性和持久节点是一致的,额外的特性表现在顺序性上。在ZooKeeper中,每个父节点都会为他的第一级子节点维护一份顺序,用于记录下每个子节点创建的先后顺序。基于这个顺序特性,在创建子节点的时候,可以设置这个标记,那么在创建节点过程中,ZooKeeper会自动为给定节点加上一个数字后缀,作为一个新的、完整的节点名。另外需要注意的是,这个数字后缀的上限是整型的最大值。
- 版本-保证分布式数据原子性操作。ZooKeeper中为数据节点引入了版本的概念,每个数据节点都具有三种类型的版本信息,对数据节点的任何更新操作都会引起版本号的变化。
6.6.1 创建持久顺序节点
创建持久顺序节点,只要不把节点删除,那么就不会重复; ```java
import org.apache.curator.framework.CuratorFramework; import org.apache.curator.framework.CuratorFrameworkFactory; import org.apache.curator.framework.api.BackgroundCallback; import org.apache.curator.framework.api.CuratorEvent; import org.apache.curator.framework.recipes.locks.InterProcessMutex; import org.apache.curator.retry.ExponentialBackoffRetry;
import java.util.concurrent.ExecutorService; import java.util.concurrent.Executors; import java.util.concurrent.TimeUnit;
/**
- 类描述:Curator实现的分布式锁
创建人:simonsfan */ public class DistributedLock {
private static CuratorFramework curatorFramework;
private static InterProcessMutex interProcessMutex;
private static final String connectString = “localhost:2181”;
private static final String root = “/root”;
private static ExecutorService executorService;
private String lockName;
public String getLockName() {
return lockName;}
public void setLockName(String lockName) {
this.lockName = lockName;}
static {
curatorFramework = CuratorFrameworkFactory.builder().connectString(connectString).connectionTimeoutMs(5000).sessionTimeoutMs(5000).retryPolicy(new ExponentialBackoffRetry(1000, 3)).build(); executorService = Executors.newCachedThreadPool(); curatorFramework.start();}
public DistributedLock(String lockName) {
this.lockName = lockName; interProcessMutex = new InterProcessMutex(curatorFramework, root.concat(lockName));}
/上锁/ public boolean tryLock() {
int count = 0; try { while (!interProcessMutex.acquire(100, TimeUnit.SECONDS)) { count++; if (count > 3) { TimeUnit.SECONDS.sleep(1); return false; } } } catch (Exception e) { e.printStackTrace(); } return true;}
/释放/ public void releaseLock() {
try { if (interProcessMutex != null) { interProcessMutex.release(); } curatorFramework.delete().inBackground(new BackgroundCallback() { @Override public void processResult(CuratorFramework curatorFramework, CuratorEvent curatorEvent) throws Exception { } }, executorService).forPath(root.concat(lockName)); } catch (Exception e) { e.printStackTrace(); }} public static void main(String[] args) {
for (int i = 0; i < 1000; i++) {
DistributedIdGeneraterService distributedIdGeneraterService = new DistributedIdGeneraterService();
String s = distributedIdGeneraterService.generateId();
System.out.println(s);
}
// ZkIdGenerator zkIdGenerator = new ZkIdGenerator(“localhost:2181”, “/id-gen”); // System.out.println( zkIdGenerator.next()); // for (int i = 0; i < 1000; i++) { // }
}
}
<a name="KtdqK"></a>
### 6.6.2 节点版本方式
只要修改了节点,版本号就会加一
```java
import org.apache.zookeeper.CreateMode;
import org.apache.zookeeper.KeeperException;
import org.apache.zookeeper.ZooDefs;
import org.apache.zookeeper.ZooKeeper;
import org.apache.zookeeper.data.Stat;
import java.io.IOException;
/**
* 使用zk生成分布式唯一id,自增有序
*
* @author CC11001100
*/
public class ZkIdGenerator {
private ZooKeeper zk;
private String path;
public ZkIdGenerator(String serverAddress, String path) {
try {
this.path = path;
zk = new ZooKeeper(serverAddress, 3000, event -> {
System.out.println(event.toString());
});
if (zk.exists(path, false) == null) {
zk.create(path, new byte[0], ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);
}
} catch (IOException | InterruptedException | KeeperException e) {
e.printStackTrace();
}
}
public long next() {
try {
Stat stat = zk.setData(path, new byte[0], -1);
return stat.getVersion();
} catch (KeeperException | InterruptedException e) {
e.printStackTrace();
}
return -1;
}
public static void main(String[] args) {
// for (int i = 0; i < 1000; i++) {
// DistributedIdGeneraterService distributedIdGeneraterService = new DistributedIdGeneraterService();
// String s = distributedIdGeneraterService.generateId();
// System.out.println(s);
// }
ZkIdGenerator zkIdGenerator = new ZkIdGenerator("localhost:2181", "/id-gen");
for (int i = 0; i < 1000; i++) {
System.out.println(zkIdGenerator.next());
}
}
}
七 mysql 读写分离
7.1 如何实现读写分离
简单来说,就搞一个主库,挂多个从库,然后我们就单单只是写主库,然后主库会自动把数据给同步到从库上去。
7.2 MySQL主从复制原理
主库将变更写binlog日志,然后从库连接到主库之后,从库有一个IO线程,将主库的binlog日志拷贝到自己本地,写入一个中继日志中。接着从库中有一个SQL线程会从中继日志读取binlog,然后执行binlog日志中的内容,也就是在自己本地再次执行一遍SQL,这样就可以保证自己跟主库的数据是一样的。
这里有一个非常重要的一点,就是从库同步主库数据的过程是串行化的,也就是说主库上并行的操作,在从库上会串行执行。所以这就是一个非常重要的点了,由于从库从主库拷贝日志以及串行执行SQL的特点,在高并发场景下,从库的数据一定会比主库慢一些,是有延时的。所以经常出现,刚写入主库的数据可能是读不到的,要过几十毫秒,甚至几百毫秒才能读取到。
7.3 数据丢失问题:
就是如果主库突然宕机,然后恰好数据还没同步到从库,那么有些数据可能在从库上是没有的,有些数据可能就丢失了。
7.4 半同步复制(semi-sync复制)
指的就是主库写入binlog日志之后,就会将强制此时立即将数据同步到从库,从库将日志写入自己本地的relay log之后,接着会返回一个ack给主库,主库接收到至少一个从库的ack之后才会认为写操作完成了。
7.5 并行复制
多库并发重放relay日志,缓解主从延迟问题,指的是从库开启多个线程,并行读取relay log中不同库的日志,然后并行重放不同库的日志,这是库级别的并行。
7.6 主从同步延时问题
- 强制读主库的方式
- 避免更新之后就查询的逻辑
- 分库,降低并发压力,降低延迟问题

若有收获,就点个赞吧
0 人点赞
