基础知识
常见的数据库分为两种类型:
- RDBMS(关系型数据库)
- 常见的关系型数据库有Oracle、DB2、Microsoft SQL Server、Microsoft Access、MySQL
- NOSQL(非关系型数据库)
- 常见的非关系型数据库有MongoDB、Redis、Voldemort、Cassandra、Riak、Couchbase、CouchDB
NoSQL(非关系型数据库具有以下优点)
易扩展,NoSQL数据库种类繁多,但它们都有一个共同的特点:都去掉了关系型数据库的关系型
特性,数据与数据之间没有关系、非常容易扩展,无形之间也在架构的层面上带来了可扩展的能
大数据量:高性能,NoSQL数据库都具有非常高的读写性能,尤其是在处理庞大数据时表现优
- 灵活,NoSQL随时都可以存储任意类型的数据,无须提前为要存储的数据建立字段。
高可用,NoSQL在不太影响性能的情况下,就可以方便地实现高可用的架构,比如Cassandra、
HBase模型,通过复制模型也能实现高可用。<br />NoSQL数据库在以下的这几种情况下比较适用
数据模型比校简单
- 对灵活性要求很强的系统
- 对数据库性要求胶高
- 不需要高度的数据一致性
- 对于给定ky,比较容易映射复杂值的环境
数据库事务
- 数据库事务的作用:要么全部执行成功,要么全部执行失败
- 平时的事务,如果没有特指分布式事务,一般指数据库事务
事务的ACID特性
原子性(Atomicity):事务是不可分割的最小的执行单位。事务的原子性确保动作要么全部完成,要
么都不发生。
一致性(Consistency):执行事务前后,数据保持一致,如:转账业务中,无论事务是否成功,转账
者和收款人的总额应该是不变的(事务开始和结束时,外部数据一致;在整个事务过程中,操作是连
续的)。
隔离性(Isolation):并发访问数据库时,一个用户的事务不被其他事务所干扰,各并发事务之间数
据是独立的。
持久性(Durability):一个事务被提交之后,它对数据库中数据的改变是持久的,即使数据库发生故
障也不应该对其有任何影响。
数据类型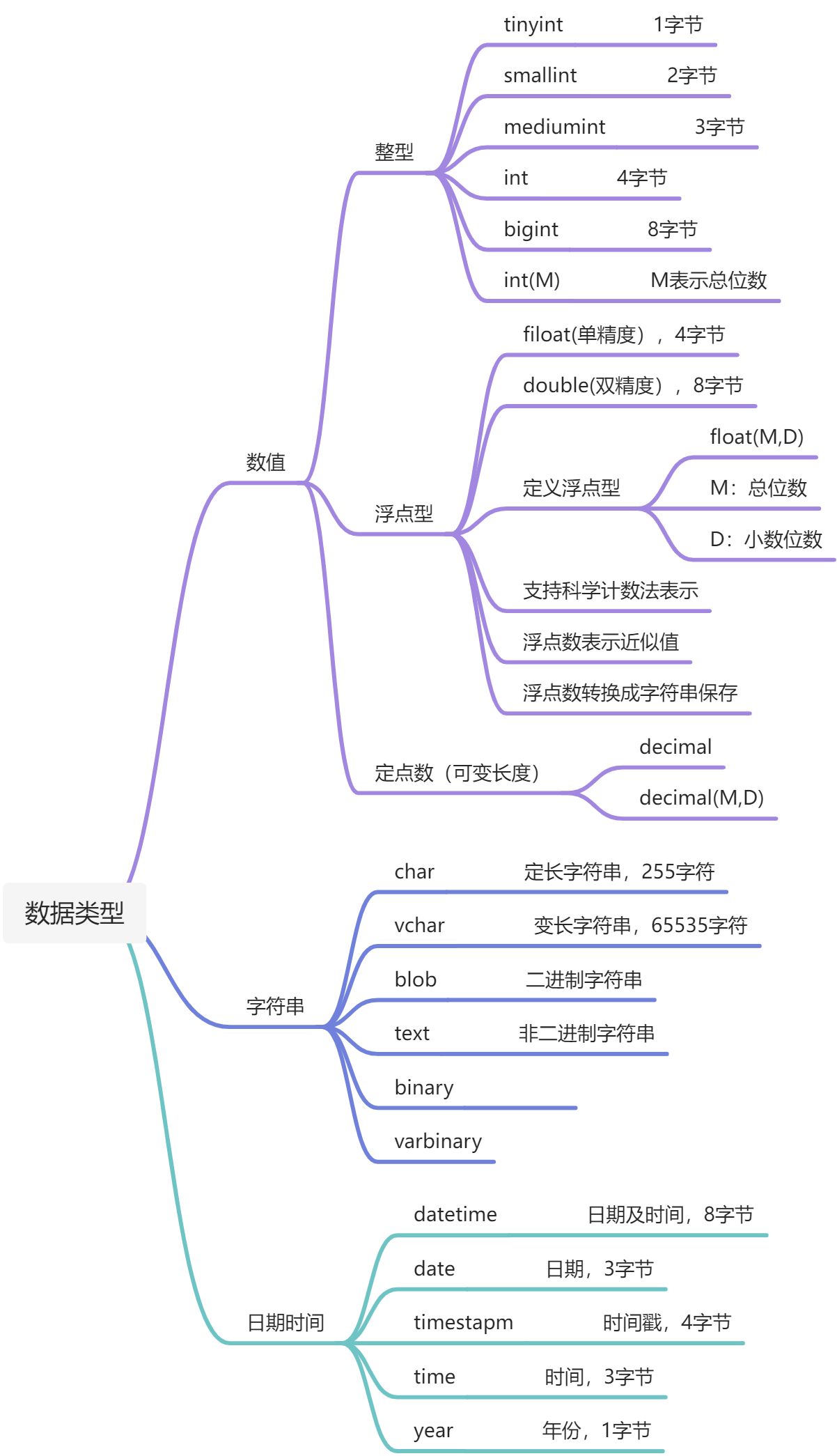
操作语句
select * from table 检索所有的列select distinct name from table 去重查询select * from table order by name;默认升序排列select * from table order by name asc;升序排列select * from table order by name desc ;降序排列select * from table where name is null;查询空select count(*) from table; 计数函数select max () from table; 求最大值select min() from table; 求最小值select sum(score) from table; 求和select avg(score) from table; 求平均值select * from table where name like 's%';模糊查询select * from table limit offset ;分页查询select name from table group by name having 分组并过滤insert into table(name) values (值);插入数据update table set name=value where 条件;修改数据delete from table where 条件;删除数据
时间查询
查询当天数据select * from table where date(字段名) =curdate();select * from table where to_days(字段名) = to_days(now());查询昨天数据select * from table where to_days(now())-to_days(字段名)=1查询近7天数据:select * from table where date_sub(curdate(),interval 7day)<=date(字段名);查询近30天数据:select * from table where date_sub(curdate(),interval 30 day)<=date(字段名);查询本周数据:select * from table where yearweek(date_format(字段名,'%Y-%m-%d))=yearweek(now());查询上周数据:select * from table where yearweek(date_format(字段名,'%Y-%m-%d))=yearweek(now())-1;查询本月数据:select * from table where date_format(字段名,'%Y%m') =date_format(curdate(), 'Y%m');查询本季度数据:select * from table where quarter(字段名)=quarter(now());查询本年数据:select * from table where year (字段名)= year (now());
SQL优化
http://testerhome.com/topics/15871
1、一定要正确的设计索引
2、一定避免SQL全表扫描,所以SQL一定要走索引
3、一定要要避免limit 100000,20这样的查询
4、一定要避免LEFTJOIN之类大查询,不要吧这样的逻辑交给数据库
5、每个表不索引不要建太多,大数据时会增加数据库读写压力
6、避免where子局中对null进行判断,否则将导致放弃索引走全表扫描
可以在num上设置默认值0,确保num列没有null之用0查询
7、避免where子句中国使用or 连接条件,否则将放弃索引使用全表扫描,用union all代替
8、百分号不能前置,否将也会放弃索引进行全表扫描
9、in 和not in也要慎用,连续数值能用between就不要用in了
10、避免where子句中对表达式进行操作,否则将会导致放弃索引走全表扫描
11、避免where子句中进行函数操作,将导致放弃索引走全表扫描
12、不要在where字句中”=”左边进行函数,算数运算,或其他表达式,否则将无法使用索引
13、使用索引作为条件时,如果索引是复合索引,必须使用索引中第一个字段
14、使用exists代替in是个不错的选择
15、索引不是越多越好,虽然提高了select效率,但是降低了insert和update效率,因为插入更新都会重建索引,所以创建索引时应该慎重考虑,视情况而定
16、尽量使用数字型字段,只含数值信息的字段尽量不要设计为字符型,这样会降低查询性能
17、使用vachar/nvachar代替char/nchar,因为变长字段存储空间小,节省存储空间
18、任何地方不要使用select from t ,用具体字段代替 ,不要返回用不到的字段
19、尽量使用表变量代替临时表,如果表变量有大量数据,注意索引非常有限
20、避免频繁创建和删除临时表,减少系统表资源的消耗
21、临时表并不是不可用,适当使用他们可以使某些例程更有效,对于一次性事件,用导出表
22、应尽可能的避免更新 clustered 索引数据列,因为 clustered 索引数据列的顺序就是表记录的物理存储顺序,一旦该列值改变将导致整个表记录的顺序的调整,会耗费相当大的资源。若应用系统需要频繁更新 clustered 索引数据列,那么需要考虑是否将该索引建为 clustered 索引
23、新建临时表时,如果一次性插入数据量很大,使用select into 代替create table ,避免造成大量log,提高速度,如果数据量不大,为了缓和系统表资源,先create table,再insert
24、如果使用到了临时表,在存储过程的最后务必将所有的临时表显式删除,先 truncate table ,然后 drop table ,这样可以避免系统表的较长时间锁定
25、尽量避免使用游标,因为游标的效率较差,如果游标操作的数据超过 1 万行,那么就应该考虑改写
26、使用基于游标的方法或临时表方法之前,应先寻找基于集的解决方案来解决问题,基于集的方法通常更有效
27、避免向客户端返回大量数据,数据量过大,考虑需求是否合理
28、尽量避免大事务操作,提高系统并发能力

若有收获,就点个赞吧
0 人点赞
