- https://arxiv.org/abs/2104.11227
- https://github.com/facebookresearch/pytorchvideo/blob/main/pytorchvideo/models/vision_transformers.py
一、要解决什么问题?
- 之前的模型无法充分的利用时间信息
- 其他的transformer模型计算量较大
-
二、如何解决的?
2.1 Patch
ViT使用了非重叠的patch方案,而MViT使用了重叠的方案。
2.2 Multi Head Pooling Attention
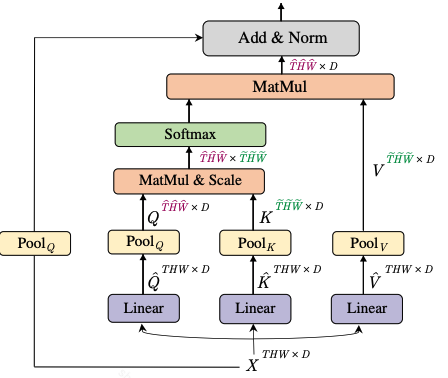
MHPA主要是为了降低图像的时空分辨率,等同于CNN中的下采样。
在之前的多头注意力中,图像分辨率(也就是ViT中的序列长度,patch累加和,比如224的图像按照77切成了3232个patch,这个序列长度就是1024代表了图像分辨率)是没有变化的,这一次对它进行了改进,使用池化将其降维。同时由于增加了时间维度,这样这个池化就相当于降低了图像的时空分辨率。
相对于之前的patch,这次的patch增加了一个时空维度,由原来代表空间分辨率的patch变成了时空分辨率patch。多个patch堆叠变成序列L,用于表示整图的时空分辨率THW,结合embedding就是[L,embedidng dim]。
在ViT中的L的尺寸是没有变化的,但是在mvit中使用了MHPA对其进行调整。具体的调整方式如下:
2.3 Channel expansion
在之前的ViT中,D也就是patch embedding的维度是不发生变化的,这一次通过MLP提升它的尺寸也就是相当于在提升CNN中的channel数。
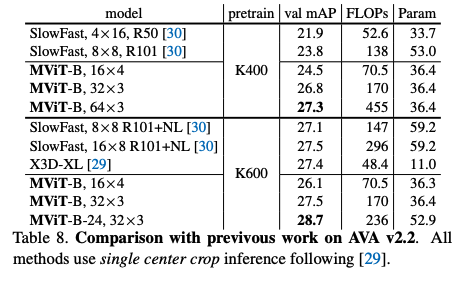
2.4 性能
三、实现细节
论文以及实现细节以Pytorch Video的官方源码为准。

3.1 Patch
Pytorch Video支持2D的Patch和3D的Patch,如果使用2D的,则输入的帧数必须为1。
使用3D卷积核进行卷积获得Patch Embedding ```python
MViT-B的设置
conv_patch_embed_kernel: Tuple[int] = (3, 7, 7) conv_patch_embed_stride: Tuple[int] = (2, 4, 4) conv_patch_embed_padding: Tuple[int] = (1, 3, 3) def create_conv_patch_embed( *, in_channels: int, out_channels: int, conv_kernel_size: Tuple[int] = (1, 16, 16), conv_stride: Tuple[int] = (1, 4, 4), conv_padding: Tuple[int] = (1, 7, 7), conv_bias: bool = True, conv: Callable = nn.Conv3d, ) -> nn.Module: “”” Creates the transformer basic patch embedding. It performs Convolution, flatten and transpose.
::
Conv3d↓flatten↓transpose
Args:
in_channels (int): input channel size of the convolution. out_channels (int): output channel size of the convolution. conv_kernel_size (tuple): convolutional kernel size(s). conv_stride (tuple): convolutional stride size(s). conv_padding (tuple): convolutional padding size(s). conv_bias (bool): convolutional bias. If true, adds a learnable bias to the output. conv (callable): Callable used to build the convolution layer.Returns:
(nn.Module): transformer patch embedding layer.“”” conv_module = conv(
in_channels=in_channels, out_channels=out_channels, kernel_size=conv_kernel_size, stride=conv_stride, padding=conv_padding, bias=conv_bias,) return PatchEmbed(patch_model=conv_module)
class PatchEmbed(nn.Module): “”” Transformer basic patch embedding module. Performs patchifying input, flatten and and transpose.
::
PatchModel
↓
flatten
↓
transpose
The builder can be found in `create_patch_embed`.
"""
def __init__(
self,
*,
patch_model: nn.Module = None,
) -> None:
super().__init__()
set_attributes(self, locals())
assert self.patch_model is not None
def forward(self, x) -> torch.Tensor:
x = self.patch_model(x)
# B C (T) H W -> B (T)HW C
return x.flatten(2).transpose(1, 2)
<a name="zNGdm"></a>
## 3.2 Multi Head Pooling Attention
```python
class MultiScaleBlock(nn.Module):
"""
Implementation of a multiscale vision transformer block. Each block contains a
multiscale attention layer and a Mlp layer.
::
Input
|-------------------+
↓ |
Norm |
↓ |
MultiScaleAttention Pool
↓ |
DropPath |
↓ |
Summation ←-------------+
|
|-------------------+
↓ |
Norm |
↓ |
Mlp Proj
↓ |
DropPath |
↓ |
Summation ←------------+
"""
def __init__(
self,
dim: int,
dim_out: int,
num_heads: int,
mlp_ratio: float = 4.0,
qkv_bias: bool = False,
dropout_rate: float = 0.0,
droppath_rate: float = 0.0,
act_layer: nn.Module = nn.GELU,
norm_layer: nn.Module = nn.LayerNorm,
kernel_q: _size_3_t = (1, 1, 1),
kernel_kv: _size_3_t = (1, 1, 1),
stride_q: _size_3_t = (1, 1, 1),
stride_kv: _size_3_t = (1, 1, 1),
pool_mode: str = "conv",
has_cls_embed: bool = True,
pool_first: bool = False,
) -> None:
"""
Args:
dim (int): Input feature dimension.
dim_out (int): Output feature dimension.
num_heads (int): Number of heads in the attention layer.
mlp_ratio (float): Mlp ratio which controls the feature dimension in the
hidden layer of the Mlp block.
qkv_bias (bool): If set to False, the qkv layer will not learn an additive
bias. Default: False.
dropout_rate (float): DropOut rate. If set to 0, DropOut is disabled.
droppath_rate (float): DropPath rate. If set to 0, DropPath is disabled.
act_layer (nn.Module): Activation layer used in the Mlp layer.
norm_layer (nn.Module): Normalization layer.
kernel_q (_size_3_t): Pooling kernel size for q. If pooling kernel size is
1 for all the dimensions, pooling is not used (by default).
kernel_kv (_size_3_t): Pooling kernel size for kv. If pooling kernel size
is 1 for all the dimensions, pooling is not used. By default, pooling
is disabled.
stride_q (_size_3_t): Pooling kernel stride for q.
stride_kv (_size_3_t): Pooling kernel stride for kv.
pool_mode (str): Pooling mode. Option includes "conv" (learned pooling), "avg"
(average pooling), and "max" (max pooling).
has_cls_embed (bool): If set to True, the first token of the input tensor
should be a cls token. Otherwise, the input tensor does not contain a
cls token. Pooling is not applied to the cls token.
pool_first (bool): If set to True, pool is applied before qkv projection.
Otherwise, pool is applied after qkv projection. Default: False.
"""
super().__init__()
self.dim = dim
self.dim_out = dim_out
self.norm1 = norm_layer(dim)
kernel_skip = [s + 1 if s > 1 else s for s in stride_q]
stride_skip = stride_q
padding_skip = [int(skip // 2) for skip in kernel_skip]
self.attn = MultiScaleAttention(
dim,
num_heads=num_heads,
qkv_bias=qkv_bias,
dropout_rate=dropout_rate,
kernel_q=kernel_q,
kernel_kv=kernel_kv,
stride_q=stride_q,
stride_kv=stride_kv,
norm_layer=nn.LayerNorm,
has_cls_embed=has_cls_embed,
pool_mode=pool_mode,
pool_first=pool_first,
)
self.drop_path = (
DropPath(droppath_rate) if droppath_rate > 0.0 else nn.Identity()
)
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.has_cls_embed = has_cls_embed
self.mlp = Mlp(
in_features=dim,
hidden_features=mlp_hidden_dim,
out_features=dim_out,
act_layer=act_layer,
dropout_rate=dropout_rate,
)
if dim != dim_out:
self.proj = nn.Linear(dim, dim_out)
self.pool_skip = (
nn.MaxPool3d(kernel_skip, stride_skip, padding_skip, ceil_mode=False)
if len(kernel_skip) > 0
else None
)
def forward(
self, x: torch.Tensor, thw_shape: List[int]
) -> Tuple[torch.Tensor, List[int]]:
"""
Args:
x (torch.Tensor): Input tensor.
thw_shape (List): The shape of the input tensor (before flattening).
"""
x_block, thw_shape_new = self.attn(self.norm1(x), thw_shape)
x_res, _ = _attention_pool(
x, self.pool_skip, thw_shape, has_cls_embed=self.has_cls_embed
)
x = x_res + self.drop_path(x_block)
x_norm = self.norm2(x)
x_mlp = self.mlp(x_norm)
if self.dim != self.dim_out:
x = self.proj(x_norm)
x = x + self.drop_path(x_mlp)
return x, thw_shape_new
3.3 cls and positional encoding
使用spatiotemporal encoding和class token。
class SpatioTemporalClsPositionalEncoding(nn.Module):
"""
Add a cls token and apply a spatiotemporal encoding to a tensor.
"""
def __init__(
self,
embed_dim: int,
patch_embed_shape: Tuple[int, int, int],
sep_pos_embed: bool = False,
has_cls: bool = True,
) -> None:
"""
Args:
embed_dim (int): Embedding dimension for input sequence.
patch_embed_shape (Tuple): The number of patches in each dimension
(T, H, W) after patch embedding.
sep_pos_embed (bool): If set to true, one positional encoding is used for
spatial patches and another positional encoding is used for temporal
sequence. Otherwise, only one positional encoding is used for all the
patches.
has_cls (bool): If set to true, a cls token is added in the beginning of each
input sequence.
"""
super().__init__()
assert (
len(patch_embed_shape) == 3
), "Patch_embed_shape should be in the form of (T, H, W)."
self.cls_embed_on = has_cls
self.sep_pos_embed = sep_pos_embed
self._patch_embed_shape = patch_embed_shape
self.num_spatial_patch = patch_embed_shape[1] * patch_embed_shape[2]
self.num_temporal_patch = patch_embed_shape[0]
if self.cls_embed_on:
self.cls_token = nn.Parameter(torch.zeros(1, 1, embed_dim))
num_patches = self.num_spatial_patch * self.num_temporal_patch + 1
else:
num_patches = self.num_spatial_patch * self.num_temporal_patch
if self.sep_pos_embed:
self.pos_embed_spatial = nn.Parameter(
torch.zeros(1, self.num_spatial_patch, embed_dim)
)
self.pos_embed_temporal = nn.Parameter(
torch.zeros(1, self.num_temporal_patch, embed_dim)
)
if self.cls_embed_on:
self.pos_embed_class = nn.Parameter(torch.zeros(1, 1, embed_dim))
else:
self.pos_embed = nn.Parameter(torch.zeros(1, num_patches, embed_dim))
@property
def patch_embed_shape(self):
return self._patch_embed_shape
def forward(self, x: torch.Tensor) -> torch.Tensor:
"""
Args:
x (torch.Tensor): Input tensor.
"""
B, N, C = x.shape
if self.cls_embed_on:
cls_tokens = self.cls_token.expand(B, -1, -1)
x = torch.cat((cls_tokens, x), dim=1)
if self.sep_pos_embed:
pos_embed = self.pos_embed_spatial.repeat(
1, self.num_temporal_patch, 1
) + torch.repeat_interleave(
self.pos_embed_temporal,
self.num_spatial_patch,
dim=1,
)
if self.cls_embed_on:
pos_embed = torch.cat([self.pos_embed_class, pos_embed], 1)
x = x + pos_embed
else:
x = x + self.pos_embed
return x
3.4 Stages

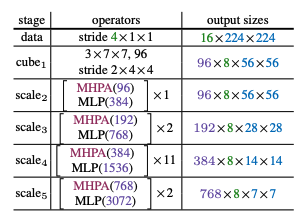
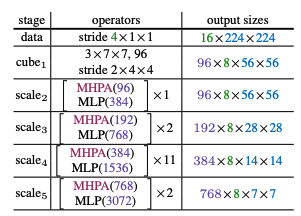
- 通过上图可以看出时空分辨率不断下降(THW)不断下降,而通道(D)的数量是在不断的翻倍,这个需要根据一定的比例进行设置,比如时空分辨率下降4倍,图像的通道数增加2倍。
- 每个stage最开始只对Q的序列L进行池化,因为KV的L长度并不会影响序列L的长度。但是KV会影响计算强度,因此在stage的其他部分则是对KV进行池化,降低计算量。video代码使用的是conv(可学习),但是也支持avg,和max。
- 对于一个stage内的skip connection,这里并不是直接连接,因为序列长度和通道都发生了变化,因此对初始的X进行池化(这个池化默认是maxpool3d),与论文的图不太一样。
- 初始的注意力头为1,随着stage的变化,头也会变化,但是始终保持D/H= 96。
video 代码通过生成一个与model层数相同的列表进行head数和embedding尺寸的控制,在特定的位置设置为2。
embed_dim_mul = [[1, 2.0], [3, 2.0], [14, 2.0]] atten_head_mul = [[1, 2.0], [3, 2.0], [14, 2.0]] # 配置维度和head的比率,其他位置的head不变,只对相应层的进行*2 dim_mul, head_mul = torch.ones(depth + 1), torch.ones(depth + 1) if embed_dim_mul is not None: for i in range(len(embed_dim_mul)): dim_mul[embed_dim_mul[i][0]] = embed_dim_mul[i][1] if atten_head_mul is not None: for i in range(len(atten_head_mul)): head_mul[atten_head_mul[i][0]] = atten_head_mul[i][1] # 首先计算改stage需要的head以及embed的尺寸,然后生成该mvit_block for i in range(depth): # 对头和embed dim进行控制 num_heads = round_width(num_heads, head_mul[i], min_width=1, divisor=1) patch_embed_dim = round_width(patch_embed_dim, dim_mul[i], divisor=num_heads) dim_out = round_width( patch_embed_dim, dim_mul[i + 1], divisor=round_width(num_heads, head_mul[i + 1]), ) mvit_blocks.append( MultiScaleBlock( dim=patch_embed_dim, dim_out=dim_out, num_heads=num_heads, mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, dropout_rate=dropout_rate_block, droppath_rate=dpr[i], norm_layer=norm_layer, kernel_q=pool_q[i], kernel_kv=pool_kv[i], stride_q=stride_q[i], stride_kv=stride_kv[i], pool_mode=pooling_mode, has_cls_embed=cls_embed_on, pool_first=pool_first, ) )

若有收获,就点个赞吧
0 人点赞
