论文:https://www.aminer.cn/pub/5e63725891e011ae97a69abb/memorizing-normality-to-detect-anomaly-memory-augmented-deep-autoencoder-for-unsupervised-anomaly
代码:donggong1/memae-anomaly-detection: MemAE for anomaly detection. — Gong, Dong, et al. “Memorizing Normality to Detect Anomaly: Memory-augmented Deep Autoencoder for Unsupervised Anomaly Detection”. ICCV 2019. (github.com)
1.论文
MemAE思想
仅使用正常样本进行训练,MemAE中的内存记录了典型的正常模式。测试时,在MemAE的内存块中找到与输入帧最相似的模式进行重构,重构得到的输出与输入差别很大,则可以判断输入帧的样本为异常,否则为正常。
Contribution
由于深度学习能力的强大,有时自动编码器“泛化”得很好,它也可以很好地重建异常,导致异常的误检测。为了减轻基于自动编码器的异常检测的这一缺点,该论文提出内存增强的自动编码器。
模型
图1 为模型模型整体图,图2 详细介绍了基于注意力的稀疏寻址的内存模块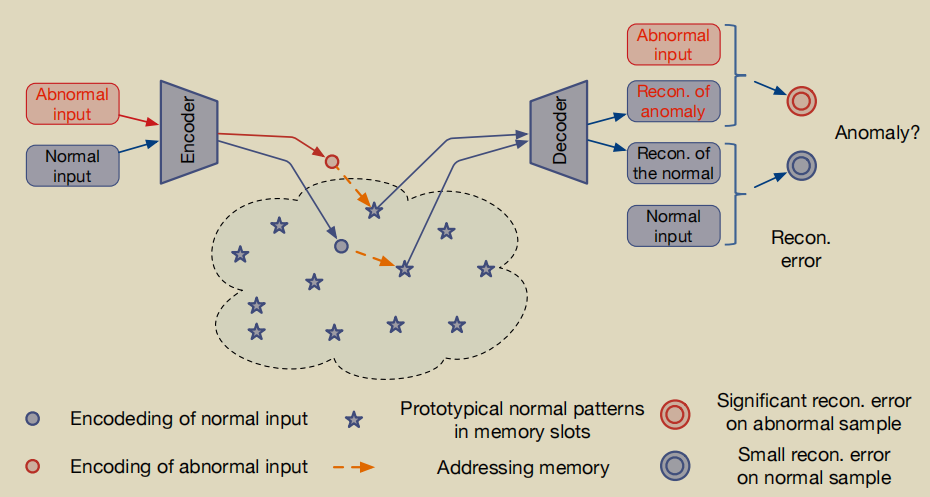
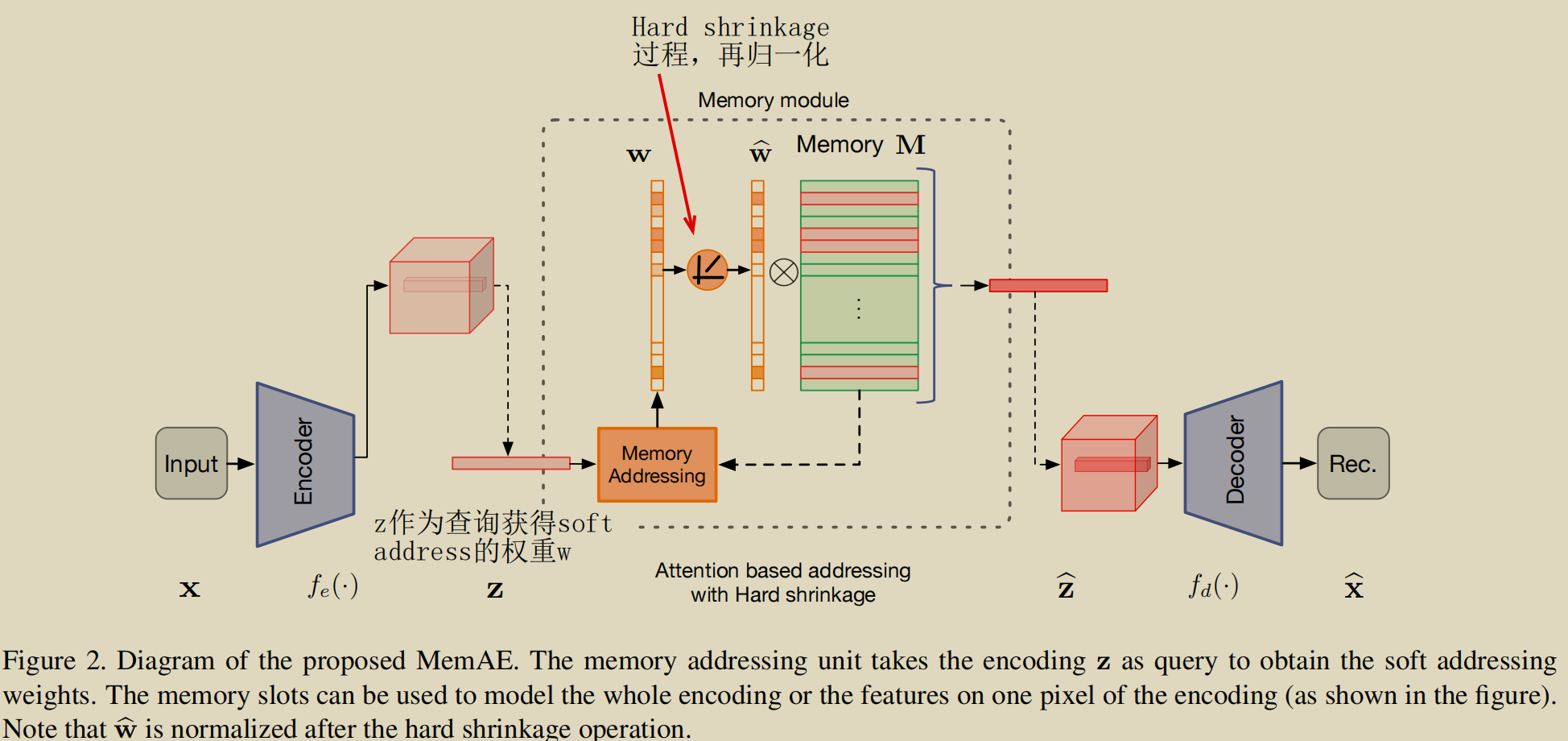
- 编码与解码
以图2为例,x为输入数据样本,z为编码域。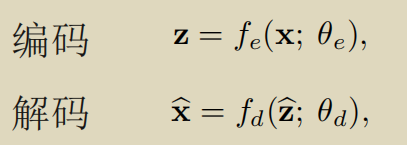
- MemAE Module
图2中详细介绍了Memory Module。Z与M经过softmax操作计算得到wi,wi经过Relu激活函数和归一化得到 wihead,zhead= WheadM。
在test时,如何在memory力找到与输入帧最相似的memory item呢?
在论文的3.3.2 Attention for Memory Address,wi是通过z和mi计算得到的,z与mi越相似,wi的值越大。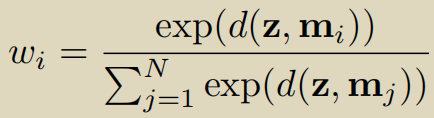
计算zhead时,wi的值越大,即mi所占权值越大,计算得到的zhead与z越相似。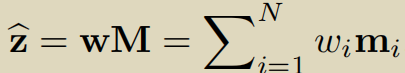
训练与测试
- 给定一个输入,MemAE首先从编码器中获得编码,然后将其作为查询,检索最相关的内存项进行重建。在训练阶段,会更新内存内容,并鼓励其表示正常数据的原型元素。
- 在测试阶段,学习到的记忆将被固定下来,并从正常数据的记忆中获得重建项。
实验
UCSD数据集
| 数据预处理 | 使用C3D进行编码、解码提取视频的时空块以保存视频的时间信息。 |
|---|---|
| 网络的输入 | 一个灰度叠加16个邻居帧构建的长方体。 |
2.网络
| Model | Encoder
nn.Conv3d(1, 96, (3, 3, 3), stride=(1, 2, 2), padding=(1, 1, 1))## 输出结构(1,96,15,128,128)
nn.Conv3d(96, 128, (3, 3, 3), stride=(2, 2, 2), padding=(1, 1, 1)),## 输出结构(1,128,8,64,64)
nn.Conv3d(128, 256, (3, 3, 3), stride=(2, 2, 2), padding=(1, 1, 1)),## 输出结构(1,128,4,32,32)
nn.Conv3d(256, 256, (3, 3, 3), stride=(2, 2, 2), padding=(1, 1, 1))## 输出结构(1,256,2,16,16)
Memory
Decoder
| | —- | —- |
在Encoder的output结果中,可以看出Memory 模块的input.shape为5D.
2.1 网络替换
在mmaction中寻找了一下backbone,将其替换MemAE中的Encoder。经过某人的引导、批评与指导。完成以下内容:
Plan A :SlowOnly
通过用mmcv的框架,快速的调用模型,Config获取模型参数,Builder实例化模型,初始化模型参数。
cfg = Config.fromfile('configs/_base_/models/slowonly_r50.py')SlowOnlybackbone = builder.build_backbone(cfg.model.backbone)SlowOnlybackbone.init_weights()
数据部分是在MemAE中直接copy的,DataSet和DataLoader。
# 加载数据v_dir = 'test1'frame_idx = [ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15]# frame_idx = [ 1, 2, 3]tmp_frame_trans = transforms.ToTensor()norm_mean = [0.5]norm_std = [0.5]frame_trans = transforms.Compose([transforms.ToTensor(),transforms.Normalize(norm_mean, norm_std)])frames = torch.cat([frame_trans(np.expand_dims(io.imread(os.path.join(v_dir, ('%03d' % i) + '.jpg')),axis=2)).unsqueeze(1) for i in frame_idx], 1)print(frames.shape)test_x = torch.unsqueeze(frames.data, dim=0).type(torch.FloatTensor)[:1]print(type(test_x))tr_data_loader = DataLoader(frames ,batch_size=1,shuffle = False,num_workers=1)
测试模型是否可用,模型输出是否与Memory的input一致。注:由于使用slowonly的cfg.model.backbone,其中的conv1_stride_t需要调整为我们实际需要的,它控制这最后模型output.shape中的T。
for item, frames in enumerate(tr_data_loader):test_x = torch.unsqueeze(frames.data, dim=0).type(torch.FloatTensor)[:1]print(test_x.shape)f = SlowOnlybackbone(test_x)print(f.size())
torch.Size([1, 1, 15, 256, 256]) # test_x.shapetorch.Size([1, 512, 2, 8, 8]) # f.size()
*slowonly模型的output.shape与Memory需要的tensor.shape一致。
拼接Memory
mem_dim = 2000feature_num = 128feature_num_2 = 96feature_num_x2 = 256feature_num_x4 = 512chnum_in = 1mem_rep = MemModule(mem_dim=mem_dim, fea_dim=feature_num_x4, shrink_thres=0.0025)
Mem_rep的结果为dict,key为['output', 'att']<br /> ['output'].size()为torch.Size([1, 256, 2, 8, 8])<br /> ['att'].size()为torch.Size([1, 2000, 2, 8, 8]])<br />拼接Decoder
decoder = nn.Sequential(
nn.ConvTranspose3d(feature_num_x4, feature_num_x4, (3, 3, 3), stride=(2, 2, 2), padding=(1, 1, 1),
output_padding=(1, 1, 1)),
nn.BatchNorm3d(feature_num_x2),
nn.LeakyReLU(0.2, inplace=True),
nn.ConvTranspose3d(feature_num_x2, feature_num, (3, 3, 3), stride=(2, 2, 2), padding=(1, 1, 1),
output_padding=(1, 1, 1)),
nn.BatchNorm3d(feature_num),
nn.LeakyReLU(0.2, inplace=True),
nn.ConvTranspose3d(feature_num, feature_num_2, (3, 3, 3), stride=(2, 2, 2), padding=(1, 1, 1),
output_padding=(1, 1, 1)),
nn.BatchNorm3d(feature_num_2),
nn.LeakyReLU(0.2, inplace=True),
nn.ConvTranspose3d(feature_num_2, feature_num_2, (3, 3, 3), stride=(1, 2, 2), padding=(1, 1, 1),
output_padding=(0, 1, 1)),
nn.BatchNorm3d(feature_num_2),
nn.LeakyReLU(0.2, inplace=True),
nn.ConvTranspose3d(feature_num_2, chnum_in, (3, 3, 3), stride=(1, 2, 2), padding=(1, 1, 1),
output_padding=(0, 1, 1))
)
在原MemAE的解码器中,修改了最后两层
输出结果:torch.Size([1, 1, 16, 128, 128])
PlanB:ResNet3d_CSN
模型调用方法与数据加载同PlanA 中。
跳到最后一步,测试模型
for item, frames in enumerate(tr_data_loader):
test_x = torch.unsqueeze(frames.data, dim=0).type(torch.FloatTensor)[:1]
print(test_x.shape)
f = CSNbackbone(test_x)
print(f.size())
torch.Size([1, 1, 15, 256, 256]) # test_x.shape
torch.Size([1, 2048, 2, 8, 8]) # f.shape
*Resnet3d_CSN模型的output.shape与Memory需要的tensor.shape一致。
拼接Mem部分
mem_dim = 2000
feature_num = 128
feature_num_2 = 96
feature_num_x2 = 256
feature_num_x4 = 512
feature_num_x6 = 1024
feature_num_x8 = 2048
chnum_in = 1
mem_rep = MemModule(mem_dim=mem_dim, fea_dim=feature_num_x8, shrink_thres=0.0025)
mem_rep的结果为dict,key为[‘output’, ‘att’]
[‘output’].size()为torch.Size([1,2048, 2, 8, 8])
[‘att’].size()为torch.Size([1, 2000, 2, 8, 8]])
拼接Decoder
decoder = nn.Sequential(
nn.ConvTranspose3d(feature_num_x8, feature_num_x6, (3, 3, 3), stride=(2, 2, 2), padding=(1, 1, 1),
output_padding=(1, 1, 1)),
nn.BatchNorm3d(feature_num_x6),
nn.LeakyReLU(0.2, inplace=True),
nn.ConvTranspose3d(feature_num_x6, feature_num_x4, (3, 3, 3), stride=(2, 2, 2), padding=(1, 1, 1),
output_padding=(1, 1, 1)),
nn.BatchNorm3d(feature_num_x4),
nn.LeakyReLU(0.2, inplace=True),
nn.ConvTranspose3d(feature_num_x4, feature_num_x2, (3, 3, 3), stride=(2, 2, 2), padding=(1, 1, 1),
output_padding=(1, 1, 1)),
nn.BatchNorm3d(feature_num_x2),
nn.LeakyReLU(0.2, inplace=True),
nn.ConvTranspose3d(feature_num_x2, feature_num, (3, 3, 3), stride=(1, 2, 2), padding=(1, 1, 1),
output_padding=(0, 1, 1)),# (1, 128, 16, 128, 128)
nn.BatchNorm3d(feature_num),
nn.LeakyReLU(0.2, inplace=True),
nn.ConvTranspose3d(feature_num, feature_num_2, (3, 3, 3), stride=(1, 2, 2), padding=(1, 1, 1),
output_padding=(0, 1, 1)),# (1, 96, 16, 256, 256)
nn.BatchNorm3d(feature_num_2),
nn.LeakyReLU(0.2, inplace=True),
nn.LeakyReLU(0.2, inplace=True),
nn.ConvTranspose3d(feature_num_2, chnum_in, (3, 3, 3), stride=(1, 1, 1), padding=(1, 1, 1),
output_padding=(0, 0, 0))# (1, 1, 16, 256, 256)
)
修改最后三层,从倒数第三层开始T不再变化。
做后结果[1, 1, 16, 256, 256]
PlanC:ResNet3d
模型调用方法与数据加载同PlanA 。
跳到最后一步,测试模型
for item, frames in enumerate(tr_data_loader):
test_x = torch.unsqueeze(frames.data, dim=0).type(torch.FloatTensor)[:1]
print(test_x.shape)
f = R3Dbackbone(test_x)
print(f.size())
torch.Size([1, 1, 15, 256, 256]) # test_x.shape
torch.Size([1, 512, 2, 8, 8]) #f.size
*Resnet3d模型的output.shape与Memory需要的tensor.shape一致。
拼接Memory
mem_dim = 2000
feature_num = 128
feature_num_2 = 96
feature_num_x2 = 256
feature_num_x4 = 512
chnum_in = 1
mem_rep = MemModule(mem_dim=mem_dim, fea_dim=feature_num_x4, shrink_thres=0.0025)
mem_rep的结果为dict,key为[‘output’, ‘att’]
mem_rep[‘output’].size()为torch.Size([1, 512, 2, 8, 8])
mem_rep[‘att’].size()为torch.Size([1, 2000, 2, 8, 8]])
拼接Decoder
decoder = nn.Sequential(
nn.ConvTranspose3d(feature_num_x4, feature_num_x2, (3, 3, 3), stride=(2, 2, 2), padding=(1, 1, 1),
output_padding=(1, 1, 1)),
nn.BatchNorm3d(feature_num_x2),
nn.LeakyReLU(0.2, inplace=True),
nn.ConvTranspose3d(feature_num_x2, feature_num, (3, 3, 3), stride=(2, 2, 2), padding=(1, 1, 1),
output_padding=(1, 1, 1)),
nn.BatchNorm3d(feature_num),
nn.LeakyReLU(0.2, inplace=True),
nn.ConvTranspose3d(feature_num, feature_num_2, (3, 3, 3), stride=(2, 2, 2), padding=(1, 1, 1),
output_padding=(1, 1, 1)),
nn.BatchNorm3d(feature_num_2),
nn.LeakyReLU(0.2, inplace=True),
nn.ConvTranspose3d(feature_num_2, feature_num_2, (3, 3, 3), stride=(1, 2, 2), padding=(1, 1, 1),
output_padding=(0, 1, 1)),
nn.BatchNorm3d(feature_num_2),
nn.LeakyReLU(0.2, inplace=True),
nn.ConvTranspose3d(feature_num_2, chnum_in, (3, 3, 3), stride=(1, 2, 2), padding=(1, 1, 1),
output_padding=(0, 1, 1))
)
在原MemAE的解码器中,修改了最后两层
输出结果:torch.Size([1, 1, 16, 256, 256])

若有收获,就点个赞吧
0 人点赞
