论文1 《Learning Normal Dynamics in Videos with Meta Prototype Network》
代码:https://github.com/ktr-hubrt/MPN/
论文:https://www.aminer.cn/pub/607832a991e011f5ecc9dc77/learning-normal-dynamics-in-videos-with-meta-prototype-network
这篇论文的整体思想与MemAE的模型大致一样,在Encoder与Decoder中间添加核心要素,本篇论文在中间添加了元模型。
1.motivation
由于深度网络的学习能力太强,深度网络也可以把异常情况重构或预测的特别好,导致“过度泛化”的问题。
1. 设计了一个动态原型学习的组件,来动态实时地建模和压缩视频中的正常模式为原型(prototype),以促进模型对正常视频帧的重建(或预测)和抑制对异常视频帧的重建(或预测)。
2.引入了元学习(mate)理论添加到DPU中形成MPU,赋予动态原型学习组件场景自适应能力,是的模型可以具有高效的场景自适应能力。
2.DPU(核心)
DPU的向前计算有三个子过程:Attention、Ensemble、Retrieving(注意力、集合、索引)
Attention:
Ensemble:推导出一个唯一的原型Pt,作为子过程集合中具有归一化规范权值的N个编码向量的集合,M个Pt构成一个原型池。
Retrieving:Xt利用AE编码映射作为查询,检索原型池中的相关项,重构规范化编码Xt’。
将得到的正常映射重构帧Xt’与原始编码X聚合作为DPU最终输出。
3.Loss
预测loss Lfre,重构loss Lc,原型loss Ld
Lfea = Lc + Ld
Loss = Lfre + Lc + Ld
代码:
model:
逻辑:帧序列 ——> Encoder ——> Decoder ——-> DPU(计算Lc和Ld) ——-> Head——->一个预测帧(计算预测损失)
Encoder 与Decoder部分为U-Net网络。
论文2 《Future Frame Prediction for Anomaly Detection – A New Baseline》
代码:https://github.com/stevenLiuWen/ano_pred_cvpr2018
论文:https://www.aminer.cn/pub/5a73cbc317c44a0b3035ed09/future-frame-prediction-for-anomaly-detection-a-new-baseline
这篇论文时视频帧预测中的重要作品,后面的好多论文也是在它基础上改进的。
论文3《Learning Memory-guided Normality for Anomaly Detection》
论文:Learning Memory-guided Normality for Anomaly Detection
代码: https://github.com/cvlab-yonsei/MNAD
这篇论文的代码是集合了上面两篇论文,而且代码很清晰,数据加载部分真的是太棒了,站在巨人的肩膀上。
代码
1.DataSet
采用的时将RGB图像在通道维上堆叠,已产生一个时间序列。采用5帧序列,tlength= 5.timestep = 4。
DataSet中把所有视频段中的每一帧路径入一个list中。在__getitem()中,获取同一个视频段中5个连续帧图像。
step()中实现把每一个视频段的信息保存都OrderedDict。其中的信息包括video_name, video_path, video_frames, video_length ,如图3-1所示。
def setup(self):videos = glob.glob(os.path.join(self.dir, '*'))for video in sorted(videos):video_name = video.split('/')[-1]self.videos[video_name] = {}self.videos[video_name]['path'] = videoself.videos[video_name]['frame'] = glob.glob(os.path.join(video, '*.jpg'))self.videos[video_name]['frame'].sort()self.videos[video_name]['length'] = len(self.videos[video_name]['frame'])
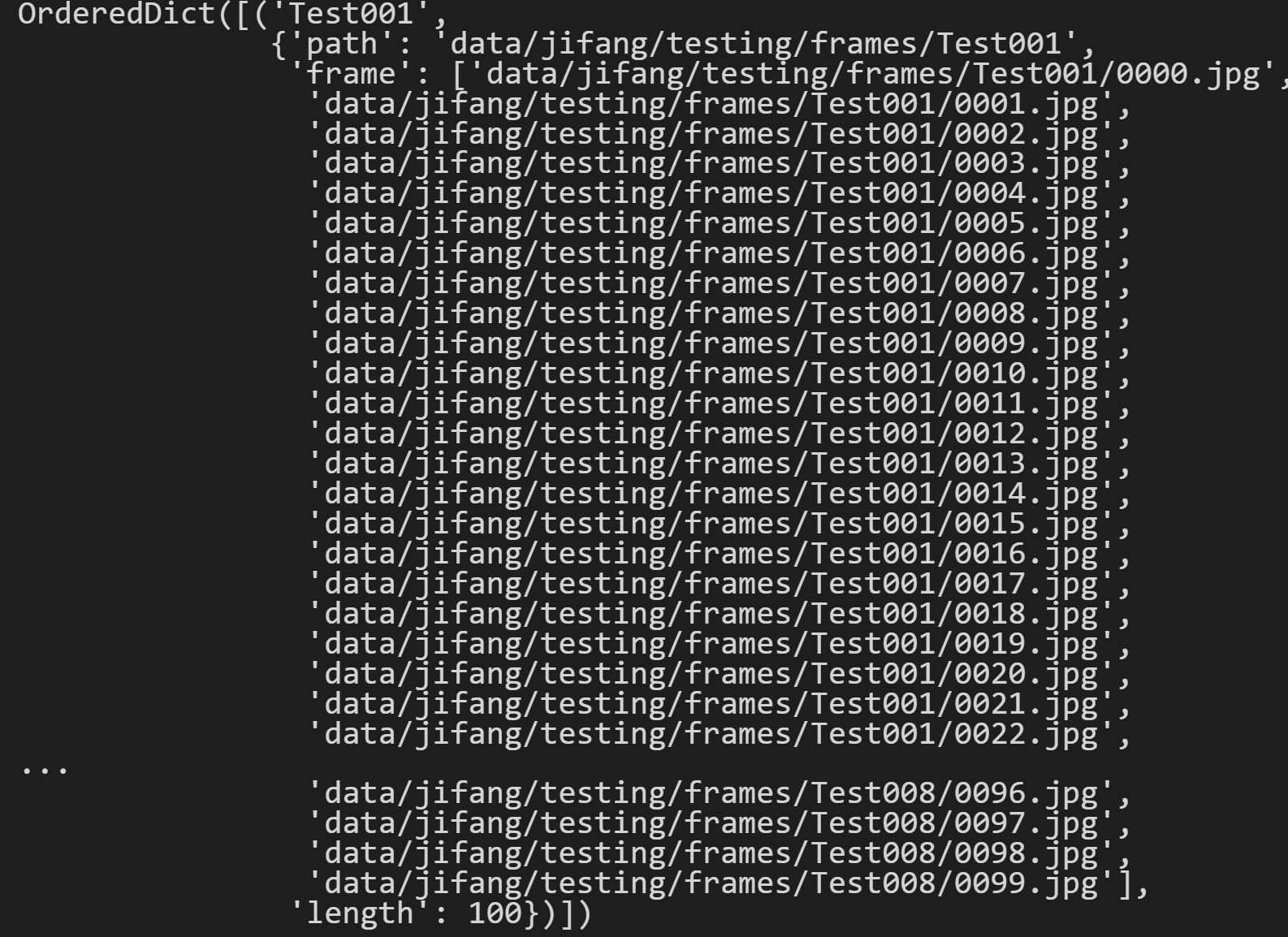
图3-1 step()的结果
get_all_samples()函数,把在step()中的所有帧放入一个list中,但是每一个视频段都会去掉最后4帧。代码中的第7行已经说明白了。
在图3-2中可以看到,最后一条数据是data/jifang/testing/frames/Test008/0095.jpg。比图3-1中的最后一条数据相比,就是删除了每一个视频的最后四帧数据。
# 将所有的视频帧全都放在一个list里def get_all_samples(self):frames = []videos = glob.glob(os.path.join(self.dir, '*'))for video in sorted(videos):video_name = video.split('/')[-1]Dfor i in range(len(self.videos[video_name]['frame'])-self._time_step): #self._time_step=4frames.append(self.videos[video_name]['frame'][i])return frames
的结果")
在这里有一个大坑,如果采用自己的数据,图片的命名一定要是从0开始。
2.Model
这篇论文是有两个method:predict和reconstruction,分别对应不同的model。
pred_model为U_Net的结构。recon_model就是一个Encoder和Decoder的,3D卷积的操作。Memory Module部分都是相同的。
模型结构如下图: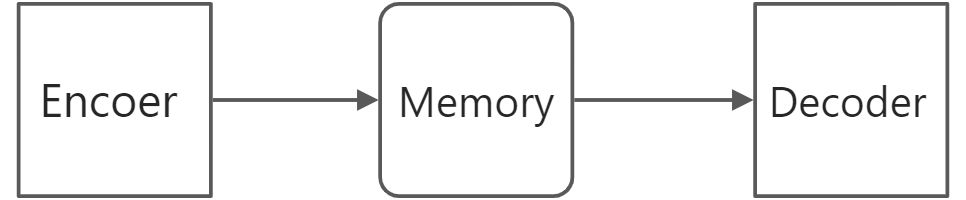
2.1 Pred_model
在Pred_model中的网络结构也是U_Net,与上面的两篇论文的预测方法一样。
2.2 Recon_model
说一下我在用Recon_model时遇到的bug。
原始的代码中,在Reconstruction.py中设置的t_length都是2,因为在DataSet部分设置的t_length为5,所以需要自己修改成5。或者在定义model的时候传入一个参数(t_length = args.t_length)。
Encoder部分第一层卷积时,修改为(n_channel*(t_length)),这里与Pred_model不同。
class Ecoder(torch.nn.Module):def __init__(self, t_length = 5, n_channel =3):...self.moduleConv1 = Basic(n_channel*(t_length), 64)
2.3 Memory Module*

若有收获,就点个赞吧
0 人点赞
