三个模型不论是单帧的MaskFormer、还是Mask2Former、Mask2Former for video基本上都是采用了一样的架构。
MaskFormer
使用类似DETR的方式(transformer + binary match)进行语义分割以及全景分割。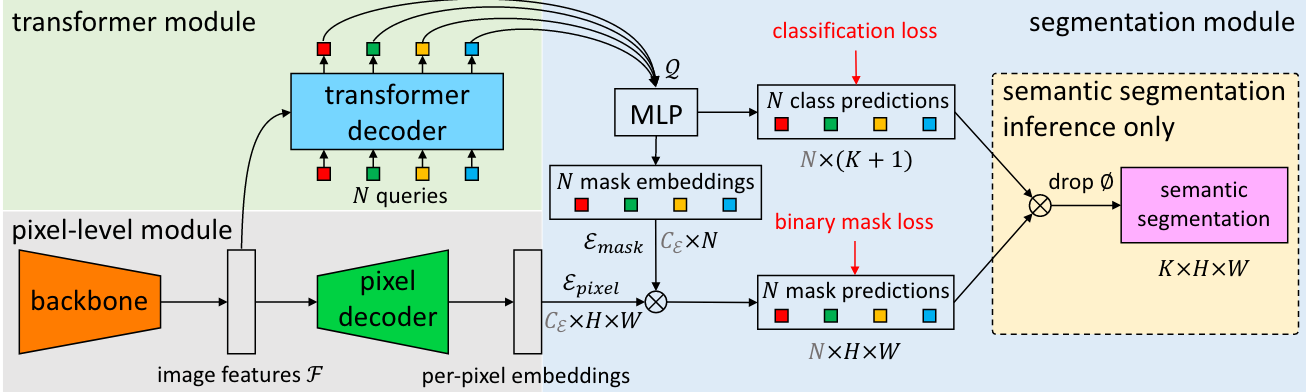
Pixel decoder
用于生成mask embedding。这部分经backbone 提取特征, 利用pixel decoder上采样得到per-pixel embedding。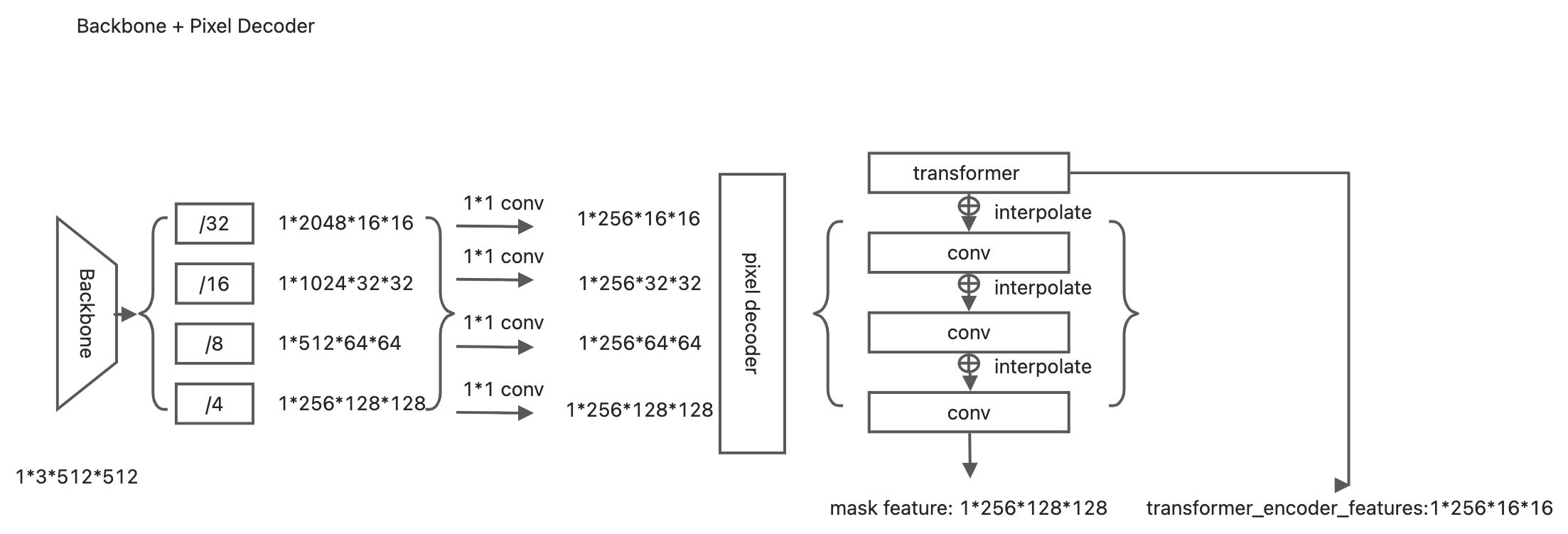
- maskformer支持swin,resnet 做backbone, pixel decoder 也支持多种,这里以源码中coco config的transformer encoder作为pixel decoder。
只有最小的feature map(/32)送入了transformer, 而且只有encoder模块。qk 分别为feat map + pos enc, v为feat map,然后类似fpn的操作进行multi scale的融合, 最后输出mask feature。同时保留transformer encoder的结果。
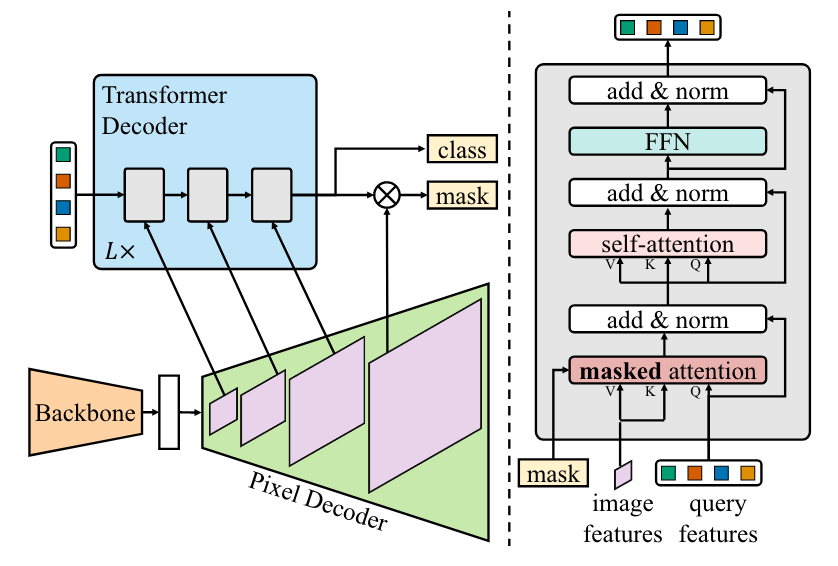
Transformer Decoder
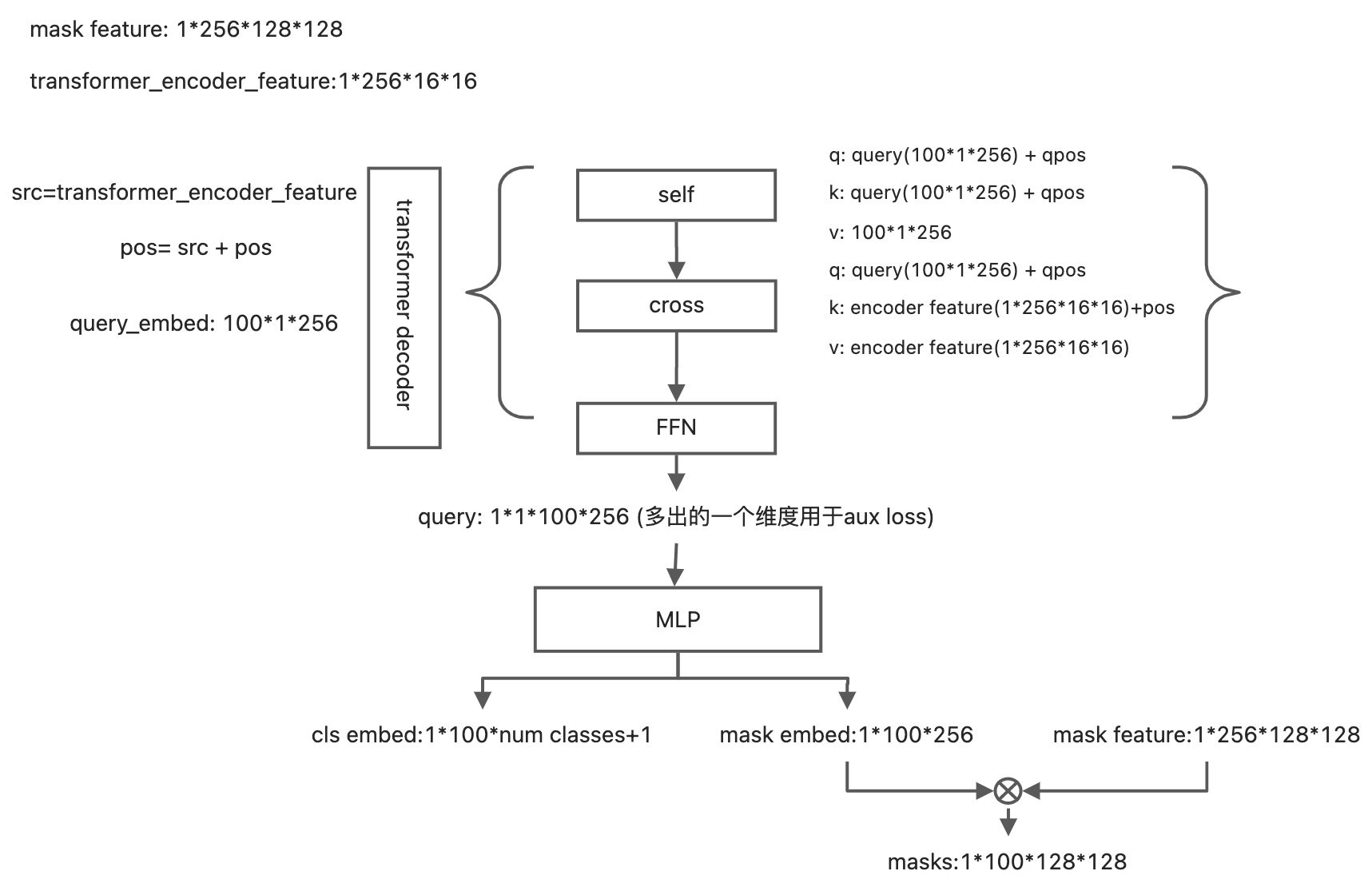
这里的输入为pixel decoder 部分产生的mask feature 以及transformer encoder产生的encoder feature。
- 这里qpos就是query embed, 而query= torch.zeros_like(query embed), 学习的目标就是更新query。虽然query每次都是0初始化,但是后面的五层decoder会将其不断的更新query,最终作为模型的输出。
- 因为使用了transformer encoder 作为pixel decoder 中的一部分, 所以在这里的transformer没有 encoder部分,仅有6层decoder。
最终的输出为cls embed :[bs, num queries,num classes +1],masks: [bs, num queries, h/4, w/4]
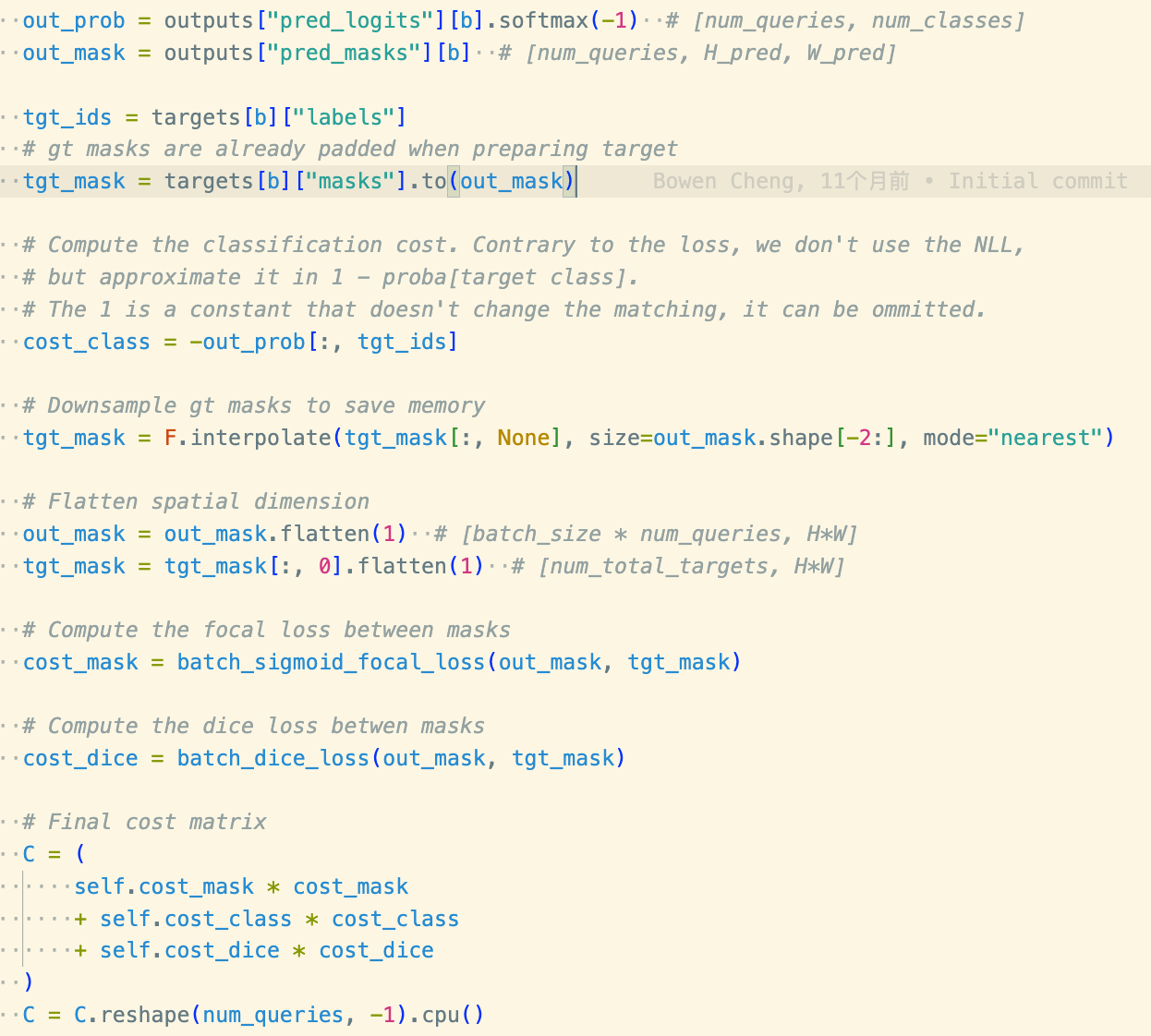
matcher + criterion
二分匹配,使用匈牙利算法计算,取出索引,然后根据索引计算取出正样本计算loss。其中涉及到cls 以及mask的匹配问题, 实际上在计算的时候可以理解为一一对应。
Mask2Former
由于maskformer训练一次需要300epcoh,因此提出了Mask2Former。加入Deformable transformr,同时交换self attn和corss attn的顺序加快收敛。
MSDformableAttnPixelDecoder
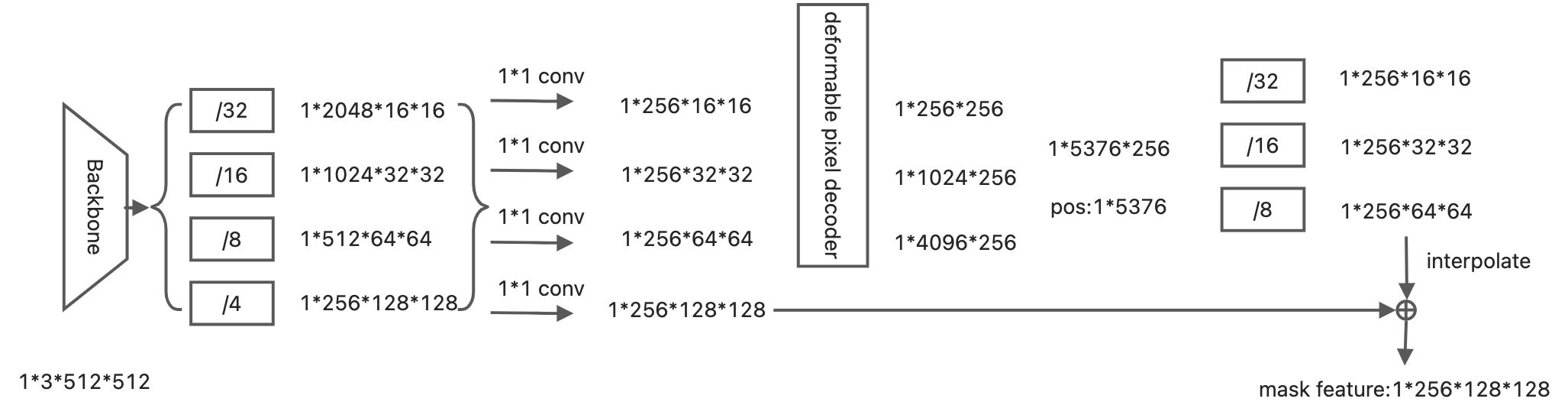
输入四个分辨率的特征图,采用Deformable DETR提出的Deformable Transformer进行多尺度特征交互,生成三个尺度(/8, /16, /32)的特征图。与maskformer的pixel decoder 一样,只用了transformer 的encoder。
- 将deformable产生的/8 feature map 上采样到/4(注意这里与maskformer有所不同,仅有/8的feature map 上采样与/4 feature map融合),与backbone的最大特征图sum产生mask feature
所以这个模块的最后的输出为mask feature, deformable部分产生的multi scale feature,以及deformabel 部分产生的/32 feature map(后面并没有用到)。
Transformer Decoder
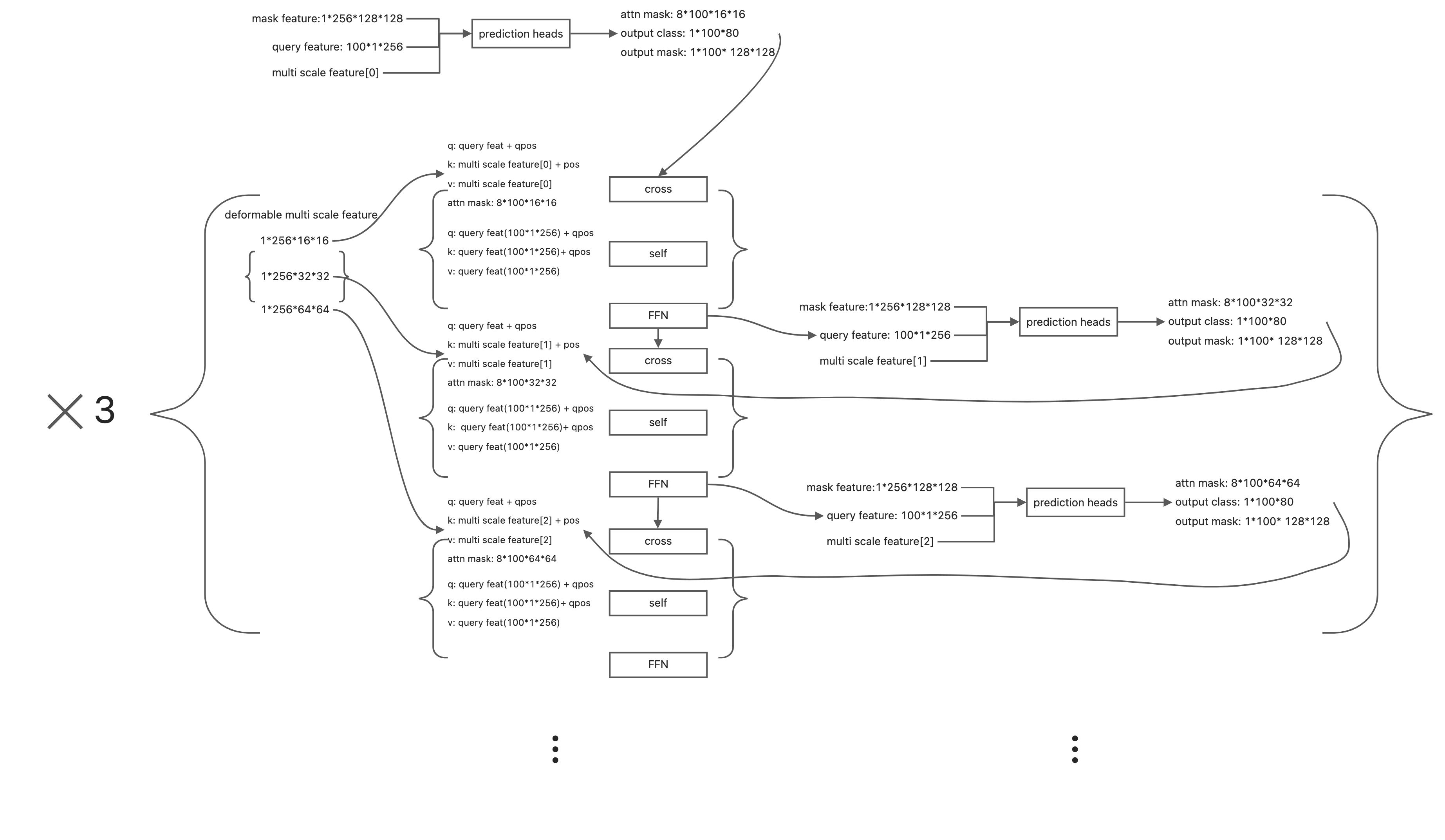
通过结构图可以看出 transformer decoder 的输入为pixel decoder产生的multi scale feature 以及 mask feature。
与之前不同的是,这里有query embed、query feature,self attn 以及cross attn的顺序也被更换了。
- query feature : 与 pixel decoder 产生的mask feature生成attn mask,可以让后面的decoder模块更专注于局部特征。
- query embed : qpos,与query feature相加作为q,k。
- transformer decoder部分一共使用了9层decoder=len(multi scale feature) * 3。三个尺度的feature map循环迭代更新query feature, 同时每层更新后的query feature会与mask feature点乘产生新的output mask、output class,同时output mask 会插值产生新的attn mask用于后续的cross attn。最终使用第9层的output class以及output mask作为模型最终的输出。
- self attn 以及cross attn被交换了,目的在于快速的帮decoder找到需要整张图中需要被关注的地方,
Mask2Former for video

若有收获,就点个赞吧
0 人点赞
