按:
转了一圈,发现目前搭配 puppeteer-record 是最省心的。那就重新收拾一下。2020-8-11
初次更新 2019-11-15
Puppeteer Recorder 近期用过 puppeteer 可以记录操作
再次更新 2020-12-23:
看了文章 《效率提高十倍,Puppeteer 如何启动交互模式?》,说是 node.js v14 可以 node -i 进入交互环境,然后再chrome的控制台找到链接入口,选择 connect
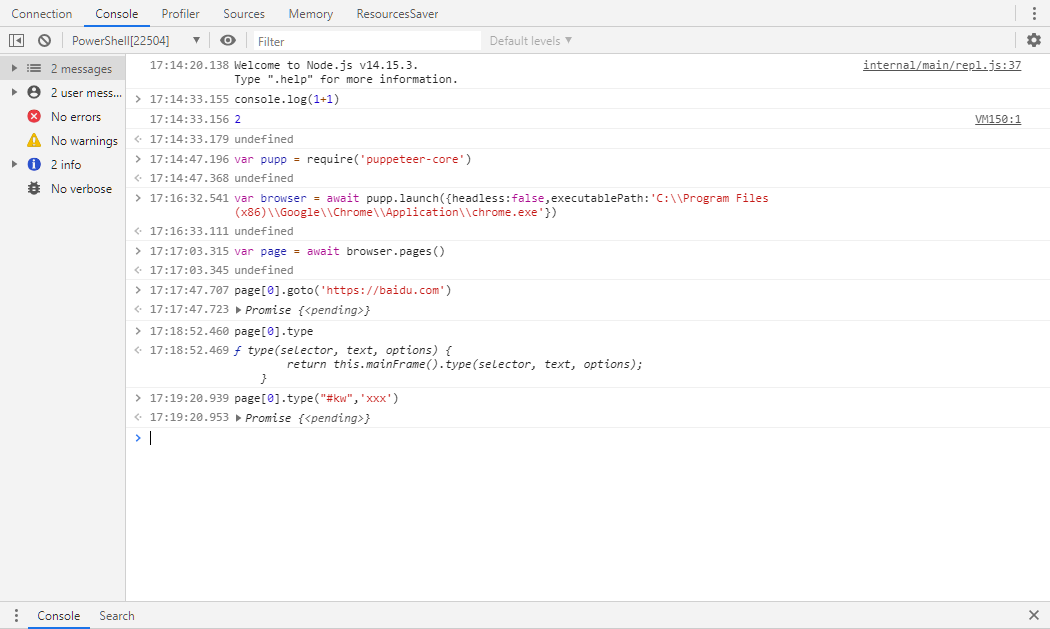
然后可以进行交互环境了,可以写一行看一行代码了,这挺方便的。
import puppeteer from 'puppeteer-core'const getDefaultOsPath = () => {if (process.platform === 'win32') {return 'C:\\Program Files (x86)\\Google\\Chrome\\Application\\chrome.exe'} else {return '/Applications/Google Chrome.app/Contents/MacOS/Google Chrome'}}let browser = await puppeteer.launch({executablePath: getDefaultOsPath()}))
相关资源
文档和工具:
- 官方文档,现在免翻墙了 https://pptr.dev/
- 一个官方认可的第三方中文文档 中文文档
- 可以在线使用puppeteer 需要翻墙
- 强烈推荐的 辅助工具 record https://checklyhq.com/docs/puppeteer-recorder/
辅助阅读材料:
- 一篇不错的入门文章,学到了很多 http://csbun.github.io/blog/2017/09/puppeteer/
- 一篇不错的文章 https://juejin.im/post/5af6876b518825426726218f
- 一个封装工具 可暂时忽略 https://sdk.apify.com/
前置概念
Puppeteer 是一个 Node 库,它提供了一个高级 API 来通过 DevTools 协议控制 Chromium 或 Chrome。Puppeteer 默认以 headless 模式运行,但是可以通过修改配置文件运行“有头”模式。
- 生成页面 PDF。
- 抓取 SPA(单页应用)并生成预渲染内容(即“SSR”(服务器端渲染))。
- 自动提交表单,进行 UI 测试,键盘输入等。
- 创建一个时时更新的自动化测试环境。 使用最新的 JavaScript 和浏览器功能直接在最新版本的Chrome中执行测试。
- 捕获网站的 timeline trace,用来帮助分析性能问题。
- 测试浏览器扩展。
下载会失败 。在安装 puppeteer的时候会自动下载一个 Chromium,但网址被墙没办法下载,需要先安装中国镜像源,具体见下方。后来推出了 puppeteer-core 包,不在捆绑下载浏览器,可以使用电脑自带的chrome,这样只要保证本机的chrome版本不要太低就可以。
安装
刚才提到需要配置国内源,补充:核心是修改 项目中 .npmrc puppeteer-download-host=https://npm.taobao.org/mirrors
使用 cnpm :
# npm i -g mirror-config-china --registry=https://registry.npm.taobao.org# 检查是否安装成功npm config listnpm i puppeteer# puppeteer-download-host=https://npm.taobao.org/mirrors# 如果始终安装失败,使用 cnpm inpm i puppeteercnpm i puppeteer
也可以考虑 puppeteer-core ,这样没有自带浏览器,那就需要在项目启动的时候设置chrome路径:
npm i puppeteer-core
代码如下:
const getDefaultOsPath = () => {if (process.platform === 'win32') {return 'C:\\Program Files (x86)\\Google\\Chrome\\Application\\chrome.exe'} else {return '/Applications/Google Chrome.app/Contents/MacOS/Google Chrome'}}const getDefaultOsPath = require('./getDefalutOsPath')module.exports = {executablePath: getDefaultOsPath(),userDataDir: 'test-profile-dir',headless: false,defaultViewport: {width: 1600,height: 900},args: ['–disable-gpu','–disable-dev-shm-usage','–disable-setuid-sandbox','–no-first-run','–no-sandbox','–no-zygote','–single-process']}
跑一个demo
创建个 demo1.js 来试跑一下。
// demo1.jsconst puppeteer = require('puppeteer-core');(async () => {const browser = await puppeteer.launch(launchOptions);const page = await browser.newPage();await page.goto("http://www.baidu.com");await page.screenshot({ path: "baidu.png" });browser.close();})();
bash页面执行:
node demo1.js
如果没有报错的话,就是打开了浏览器,并截图。这样就安装成功了。
代码文件命名为 demo1.js 可以在目录里查找。
如果下载有问题,就可以考虑使用本地的chrome,参考上面。
这样就掌握基本的用法了。
经验技巧
recored插件
利用 puppeteer-record 插件,可以快速生成一些基础代码,必备。
sleep函数
// 延时器let timeout = function (delay) {console.log('延迟函数:', `延迟 ${delay} 毫秒`)return new Promise((resolve, reject) => {setTimeout(() => {try {resolve(1)} catch (error) {reject(error)}}, delay);})}
Linux下缺少依赖
有可能在Linux下因为缺少依赖,安装不上,考虑安装下面的依赖文件:
gconf-service libasound2 libatk1.0-0 libatk-bridge2.0-0 libc6 libcairo2 libcups2 libdbus-1-3 libexpat1 libfontconfig1 libgcc1 libgconf-2-4 libgdk-pixbuf2.0-0 libglib2.0-0 libgtk-3-0 libnspr4 libpango-1.0-0 libpangocairo-1.0-0 libstdc++6 libx11-6 libx11-xcb1 libxcb1 libxcomposite1 libxcursor1 libxdamage1 libxext6 libxfixes3 libxi6 libxrandr2 libxrender1 libxss1 libxtst6 ca-certificates fonts-liberation libappindicator1 libnss3 lsb-release xdg-utils wget
Linux 下中文不支持
考虑安装以下依赖,来支持中文,避免乱码:
sudo apt-get install -y --force-yes --no-install-recommends fonts-wqy-microhei ttf-wqy-zenhei
模拟手机
模拟手机打开页面
const puppeteer = require("puppeteer");const devices = require("puppeteer/DeviceDescriptors");const iPhone6 = devices["iPhone 6"];const browser = await puppeteer.launch();const page = await browser.newPage();await page.emulate(iPhone6);await page.goto("http://baidu.com");
await page.setViewport({ width: 1280, height: 800 });
拦截请求
不想加载图片和js,想让页面打开更快。可以考虑拦截
// 页面设置拦截await page.setRequestInterception(true);// 过滤拦截page.on("request", interceptedRequest => {// 符合匹配就 abort ,其他 continue// 这里是操作的 url 字符串if (interceptedRequest.url().endsWith(".png") ||interceptedRequest.url().endsWith(".jpg") ||interceptedRequest.url().endsWith(".js") ||["image", "script"].indexOf(interceptedRequest.resourceType()) !== -1) {interceptedRequest.abort();} else {interceptedRequest.continue();}await page.goto("http://www.wangxiao.cn/cfe/dt_bm/");//demo2const browser = await puppeteer.launch();const page = await browser.newPage();const resList = []await page.setRequestInterception(true);page.on('request', request => {if (request.resourceType() === 'image')// request.abort();resList.push(request.url())request.continue();// else// request.continue();});await page.goto('https://news.google.com/news/');// await page.screenshot({ path: 'news.png', fullPage: true });await browser.close();
获取页面源代码
await page.goto("https://www.youtube.com", { waitUntil: "networkidle0" });const html = await page.content();
屏幕滚动
解决懒加载和数据滚动加载,这就是我认为 puppeteer 最有魅力的地方了。
以往只能去慢慢分析页面结构、研究接口api ,来获取异步加载的数据,现在直接无脑模拟浏览器,滚动页面来获取页面内容。
await page.goto("https://www.jd.com/", {waitUntil: "networkidle2"});await autoScroll(page);async function autoScroll(page) {await page.evaluate(async () => {await newPromise((resolve, reject) => {var totalHeight = 0;var distance = 200;var timer = setInterval(() => {var scrollHeight = document.body.scrollHeight;window.scrollBy(0, distance);totalHeight += distance;if (totalHeight >= scrollHeight) {clearInterval(timer);resolve();}}, 200);});});}
操作页面
在浏览器中使用自己的js 这里好像没办法传入自己的function
const result = await page.$eval("#hotwords", el => {return el.innerText;});// 或者const result = await page.evaluate(() => {let element = document.querySelector("#hotwords");return element.innerText;});
键盘方法
await page.type("#search input", "macbook pro", {delay: 300});await page.keyboard.press("Enter");// 或者const inputEle = await page.$("#search input");await inputEle.type("macbook pro", {delay: 300});
键盘大写、快捷键
await page.focus("input");await page.keyboard.down("Shift");await page.keyboard.press("KeyM");await page.keyboard.up("Shift");
等待节点
想等到某个元素出现
await page.waitForSelector('div.title > a'); //等待节点出现
launch 选项
headless: false
slowMo: 200 减速显示,有时候为了模拟人会特意减速
devtools: true 显示dev工具
页面中的iframe
如果网页内有用iframe等标签,这时page对象是无法读取 iframe 里面的内容的,需要用到page.frames()。返回一个Frame对象数组。 通常iframe会有name属性,判断name属性可以快速获取单个Frame对象的内容。
let iframe = await page.frames();iframe.find(f => f.name() === 'name')
监听 console的输出
想看页面里的console,可以监听
page.on('console',msg => console.log(msg.text());await page.evaluate(() =>{console.log()})
使用 coverage trace
可以使用 chrome自带的分析工具来分析页面
const puppeteer = require("puppeteer");puppeteer.launch().then(async browser => {const page = await browser.newPage();//start coverage traceawait Promise.all([page.coverage.startJSCoverage(),page.coverage.startCSSCoverage()]);await page.goto("https://www.cnn.com");//stop coverage traceconst [jsCoverage, cssCoverage] = await Promise.all([page.coverage.stopJSCoverage(),page.coverage.stopCSSCoverage()]);let totalBytes = 0;let usedBytes = 0;const coverage = [...jsCoverage, ...cssCoverage];for (const entry of coverage) {totalBytes += entry.text.length;for (const range of entry.ranges)usedBytes += range.end - range.start - 1;}const usedCode = ((usedBytes / totalBytes) * 100).toFixed(2);console.log("Code used by only", usedCode, "%");await browser.close();})}
const puppeteer = require("puppeteer");const devices = require("puppeteer/DeviceDescriptors");const iPhonex = devices["iPhone X"];(async () => {const browser = await puppeteer.launch();const page = await browser.newPage();await page.emulate(iPhonex);//start the tracingawait page.tracing.start({ path: "trace.json", screenshots: true });await page.goto("https://www.bmw.com");//stop the tracingawait page.tracing.stop();await browser.close();})();
简言之,在goto页面之前,打开特定的功能
监控页面
监控页面。写一个app.js setInerval 每隔5分钟运行一次,截图页面,如果有问题可以存下来,再说其他task
也可以使用 node-cron 来制作定时任务
关于新开页面
如果a链接,新开了页面。
如果a标签target属性为_blank,新开了页面,可以使用let pages = await browser.pages(),它返回当前的页面的page类数组集合,想要哪个页面数组中拿就行,不过原来的page还是一直指向原来的页面。
wsl 使用
Hi! Here is how I got it running under WSL:
install chromium browser through apt-get
$ sudo apt-get install chromium-browser
then:
const browser = await puppeteer.launch({executablePath:’/usr/bin/chromium-browser’});

若有收获,就点个赞吧
0 人点赞
