在webkit,资源最初的标识就是字节流,这些字节流可以是网络传输来的,也可以是本地文件,那么字节流在接下来需要经过怎么的处理呢?处理后变成了什么呢?研究W3C的DOM模型之后,深入WebKit的核心部分,剖析WebKit的HTML解释器是如何降重网络或者本地文件火气的字节流转成内部表仕结构—DOM树。
DOM模型
DOM标准
DOM(Document Object Model)的全称是文档对象模型,它可以以一种独立于平台和语言的方式访问和修改一个文档的内容和结构。这里的文档可以是HTML文档、XML文档或者XHTML文档。DOM以面向对象的方式来描述文档,在HTML文档中,Web开发者可以使用JavaScript语言来访问、创建、删除或者修改DOM结构,其主要目的是动态改变HTML文档的结构。
DOM定义的是一组与平台、语言无关的接口,该接口允许编程语言动态访问和更改结构化文档。使用DOM表示的文档被描述成一个树形结构,使用DOM的接口可以对DOM树结构进行操作。W3C标准化组织定义一系列DOM接口,随着时间的推移,目前已经形成了三个演进的标准,包括DOM Level1、DOM Level2和DOM Level3,每个新的“Level”都是在原有基础上增加新的接口以加强功能。每一级的版本都对以前的版本进行了补充并伴随这新功能的加入,每个版本都对DOM的不同部分进行了定义。
DOMLevel1
- Core:一组底层的接口,其接口可以表示任何结构化文档,同时也允许对接口进行扩展,例如对XML文档的支持。
HTML:在Core定义的接口之上,W3C定义了一组上层接口,主要是为了对HTML文档进行访问。它吧HTML中的内容定义为文档(Document)、节点(Node)、属性(Attribute)、元素(Element)、文本(Text)等。
DDMLevel2
Core:对DOM level 1中1Core部分扩展。如getElementById,namespace的接口。
- Views: 描述跟踪一个文档的各种视图的接口。
- Events:引入对DOM事件的处理,主要有EventTarget、Mouse等事件接口。
- Style:一种新接口。
- Traversal and range : 遍历树(NodeTterator 和 TreeWalker)加上对制定范围的文档修改、删除等。
HTML:扩充DOMLevel1 的HTML部分,允许动态访问和修改HTML文档。
DOM level3
Core 加入了adoptNode textContent
- Load and Save 允许程序动态加载XML文件并解释成DOM表示的文档结构。
- Validation: 允许程序验证文档的有效性。
- Events: 主要加入了对键盘的支持。随着移动平台的星期。触屏技术的到广泛应,所以触控(Touch)时间的草案。
- XPath:使用Xpath1.0来访问DOM树,Xpath是一种简单直观的检索DOM树节点的方式。
DOM树
结构模型
DOM结构构成的基本要素是“节点”提供的接口,使用IDL语言来描述。IDL是一种跟语言无关的接口语言。从这个定语可以看出文档继承自几点类型,所以可以使用Dode的接口。“文档”节点表示是正个文档,所以Web开发者可以从中创建很多其他类型的节点,这些节点都属于该文档。DOM树
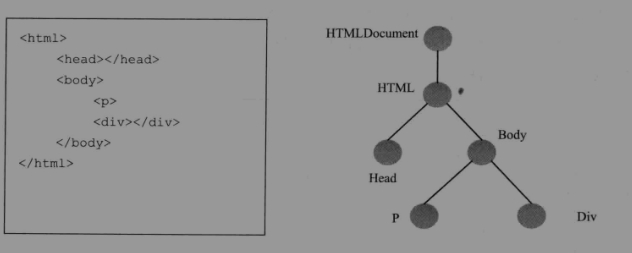
HTML解释器
解释过程
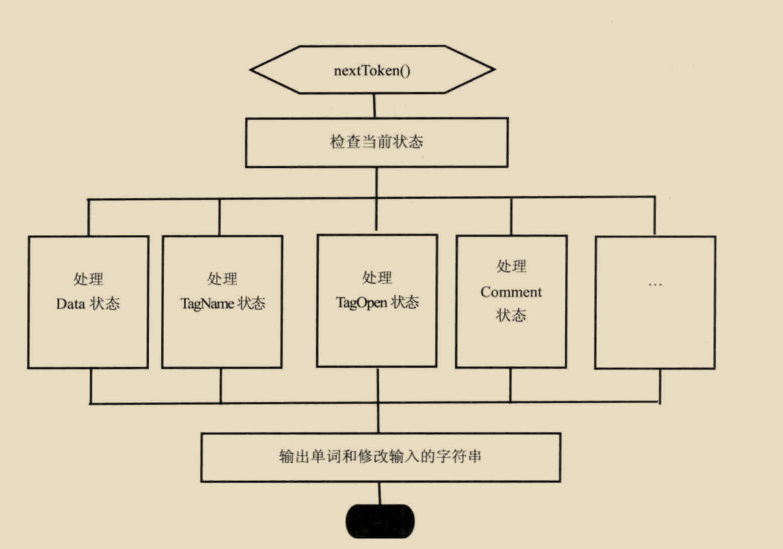
HTML解释器的工作就是讲网络或者本地磁盘获取的HTML网页和资源从字节流解释成DOM树结构。这一过程大致可以理解成
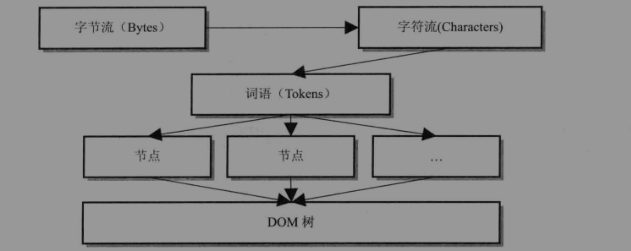
webkit内部对网页内容在各个节点的结构表示。WebKit这一过程在图中被描述的很清晰:首先是字节流,经过解码之后是字符流,然后通过词法分析器会让解释成词语(tokens),之后经过词法分析器构建成节点,最后这些节点被组件成一颗DOM树。
WebKit为王城这过程,引入了比较复杂的基础设施类。
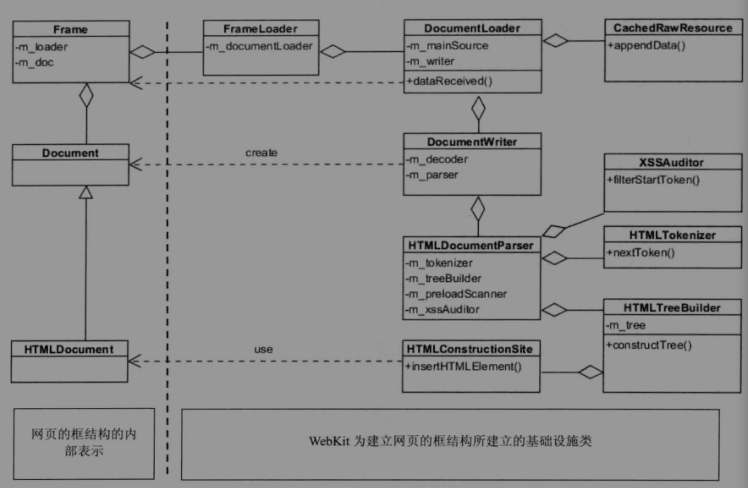
右边部分是webkit为建立网页的框结构所建立的设施。先看FrameLoader类,踏实框中内容的加载器,类似于资源和资源的加载器。因为Frame对象中包含Document对象,所以WebKit同样需要DocumentLader类帮助加载HTML文档并从自家刘到构建的DOM树。DocumentWriter类是一个辅助类,它会创建DOM树的根节点HTMLDocument对象,同样该类包括两个成员变量,一个是用于文档的字符解码的类,两外一个就是HTML解释器HTMLDocumentParser类。
HTMLDocumentParser类是一个管理类,包括了用各种工作的其他类,例如字符串到词语需要用到词法分析器HTMLTokenizer类。该管理类读入字符串,输出一个词语。这些词语经过XSSAuditor做完安全检查之后,就会输出到HTMLTreeBuilder类。
HtmlTreeBuilder类负责DOM树的简历,他本是能够通过词语创建一个个的节点对象。然后后,皆有HTMLConsturctionSite类将这些节点对象构建成一颗DOM树。
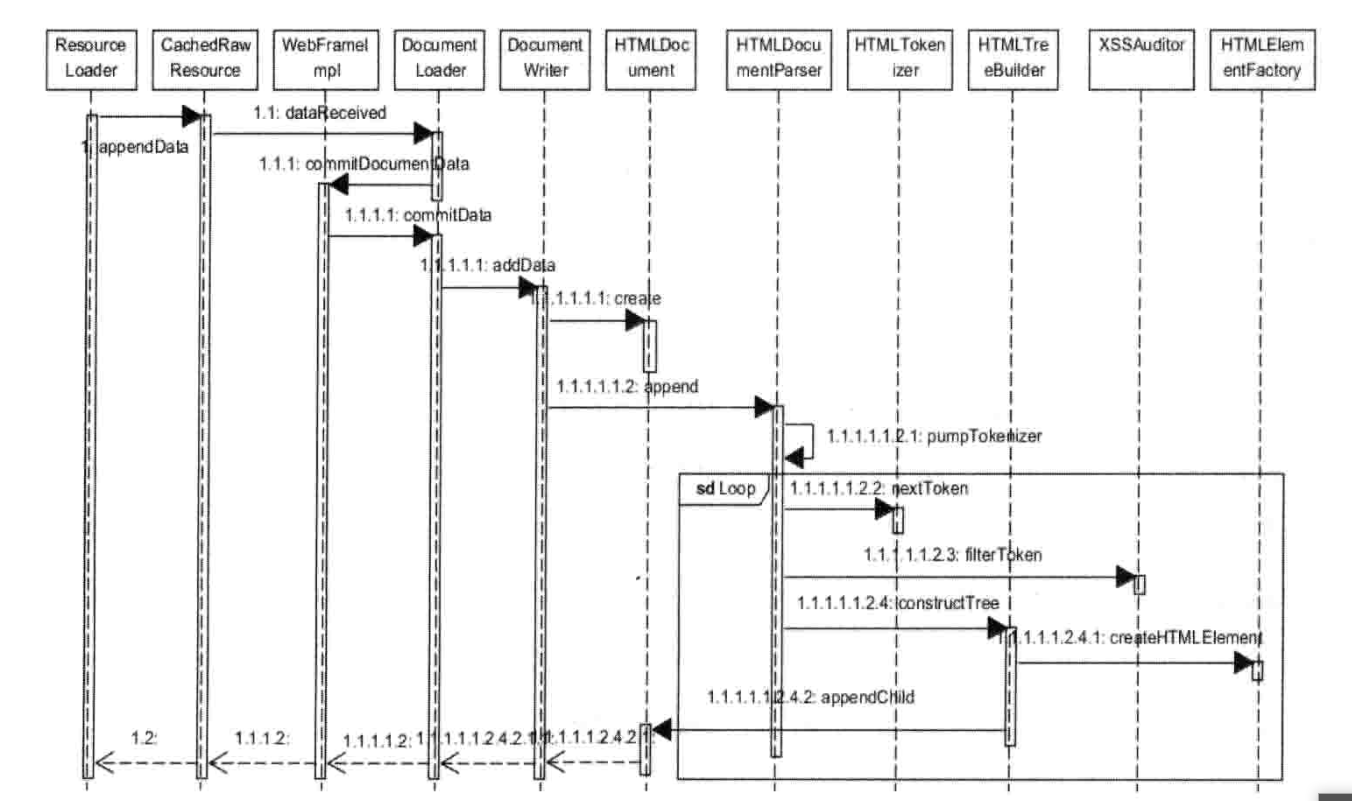
词法分析
在进行词法分析之前,解释器首先要做的事情就是检查该网页内容使用的蝙蝠格式,以便后面使用合适的解码器。如果解释器在HTML网页中找到了设置的编码格式,WebKit会使用相拥的解码器来讲字节流转换成特定格式的字符串。如果没有特殊的格式,词法分析器HTMLTokenizer类可以直接1进行词法分析。
词法分析的工作都是由HTMLTokenizer类完成,简单来说,他就是一个状态机—输入的字符串,输出的是一个个的词语。以为字节流可能是分段的,所以输入的字符串可能也是分段的,但是这对词法分析器来书没有什么特别之处,他会自己维护内部的状态信息。
词法分析器主要接口是“nextToken”函数,调用者主需要将字符串传入,然后就会得到一个词语,并对传入的字符串设置相应的信息,表示当前处理玩的位置,如此循环。如果词法分析器遇到错误,则报告状态码。
对于“nextToken”函数的调用者而言,他首先设置输入需要解释的字符串,软后寻循环调用NextToken函数,直到处理结束。“nextToken”方法每次输出一个词语,同时会标记输入的字符串,表明那些字符已经被处理过了。因此,每次词法分析器都会根据上次设置的内部状态和上次处理之后的字符串来成成一个新的词语。“nextToken”函数内部使用超过70中状态。
而对于词语的类别,WebKit只定义了很少,HTMLToken类定义了6中词语类别,包括DOCTYPE、StartTag、EndTag、Comment、Character和EndOfFile。这里不涉及HTML标签类型等信息,那是后面词法分析的工作。
XSSAuditor
当词语生成之后,WebKit需要使用XSSAuditor来验证此路流(TokenStream)。XSS指的是Cross Site Security,主要是针对安全方面的考虑。
词语到节点
经过词法分析器解释之后的词语随之被XSSAuditor过滤并且在没有被组织之后,将被WebKit用来构建DOM节点。
节点到DOM树
从节点到构建DOM树,包括为书中的元素节点创建属性节点等工作有HTMLConstructionSite类来完成。正如前面介绍的,该类包含一个DOM树的根节点—HTMLDocument对象,其他的元素节点都是他的后代。
因为HTML文档的Tag标签是有开始和结束标记的,所有构建这一过程可以使用栈结构来帮忙。HTMLConstructionSite类包含一个“HTMLElementStack”变量,踏实一个保存元素节点的栈,其中的元素节点是当前有开始标记但是还没有结束标记的元素节点。
根据DOM标准中的定义,节点有很多类型,例如元素节点、属性节点等。那么,WebKit用来表示DOM结构的相关类是什么呢?
用DOM标准一样,一切的基础都是Node类。在Webkit中,DOM中的接口Interface对应于C++类,Node类是其它类的基类。Node类实际上继承自EventTarget类它表明Node类能够接受事件,这个会在DOM事件处理中介绍。Node类还继承自另外一个基类—ScriptWrappable,这个跟JavaScript引擎相关。
Node的子类就是DOM中定义的同名接口,元素类、文档类和属性类均集成自一个抽象出来的ContainerNode类,表明他们能都包含其他的节点对象。回到HTML文档来说,元素和文档对应的类就是HTMLElement类和HTMLDocument类。实际上HTML规范还包括众多HTMLElement子类,用于表示HTML语法众多的标签。这些类比较容易理解。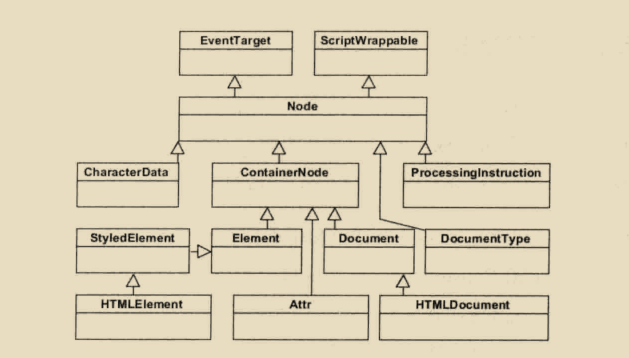
网页基础设施
上面介绍了Frame、Document等WebKit中的基础类,这些都是网页内部概念,实际上,WebKit提供了跟高层次的设施用于表示网页的一些类,WebKit中的接口部分就是基于他们来提供的。表示网页的类既提供了构建DOM树等这些操作,同时也提供了接口、布局。渲染等操作。
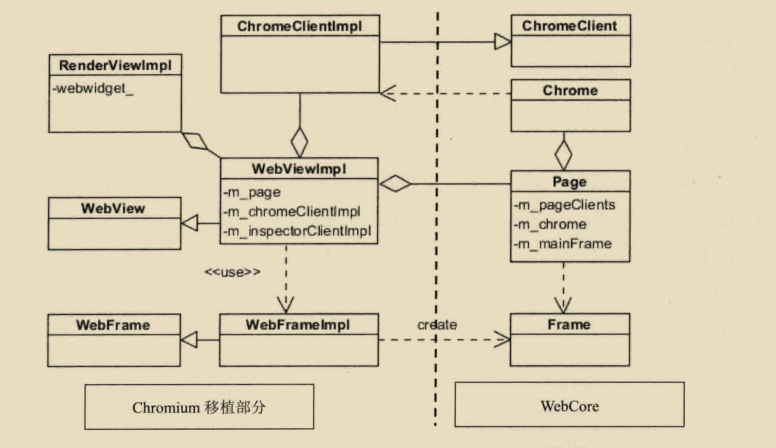
WebView类和Page类是一一对应的,Page是WebKit内部用来表示网页的类,WebView是WebKit对外表示网页的类。Page类对于WebKit所有一直都是一个实现,这里的WebView类是WebKit的Chromium一直定义的接口类,其实,在其他不同的移植中,WebView类可能有不同的实现和一些差异。一个公共的内部表示和一个外部接口的组合,图中类似的组合类例如WebFrame和Frame类。
图中右上角是Chrome和ChromeClient类,这两个类非常重要,他们使用一个WebKit普通使用的设计模式。此Chrome非彼Chrome,这里的Chrome是WebKit的一个类,表示的是网页缩回这的与实现先关的一个窗口,而不是Google的浏览器产品Chrome。Chrome类必须满足下面两种需求。
- Chrome类需要剧本获取各个平台资源的能力,例如WebKit可以盗用Chrome类来创建一个新窗口。
- Chrome类需要把WebKit的状态和进度等信息排放给外部的调用者或者说是WebKit的使用者。
WebKit内部同这两类需求相关的要求都是通过Chrome类的接口来完成的,这时候有个问题,那就是如何让WebKit和外部调用者几部紧密耦合,又能方便的支持不同平台呢?Webkit使用ChromeClient抽象类来解决这些问题,Chrome类市一些公共的操作流程,而ChromeClient类是Chrome类需要用到的一些接口,这些接口在不同的移植上必须有不同的实现,所有从图中读者可以看到,WebKit的Chromium移植中有ChromeClientImpl实现类。ChromeClient类可有有两类接口,第一类用来监听Webkit的内部状态信息,这其实是回调函数:第二类永泰实现Chrome类所需要的跟一只相关的工作。
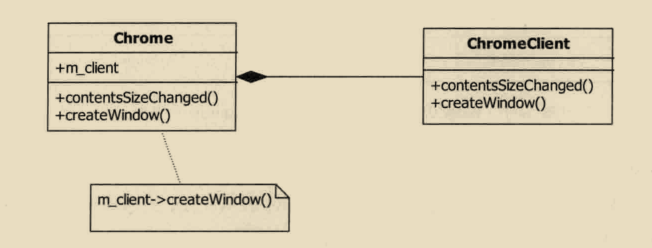
比如ChromeClient类用法。当Chrome类接受到网页的大小发生改变的消息2时,他就会调用ChromeClient类的contentsSizeChanged函数来通知Chromium浏览器。
Chrome类,是WebKit与他的使用者之前的桥梁,主要扶着用户界面和渲染先关的需求。
- 跟用户界面和渲染显示相关的需要各个一直实现的接口集合类。
- 继承自HostWindow类,该类包含一些列接口,用来通知重绘或者更新整个窗口、滚动窗口等。
- 窗口相关操作,例如显示、隐藏窗口等。
- 显示和隐藏窗口中的工具栏、滚动条、状态栏等。
- 显示JavaScript相关的窗口,如JavaScript的alert、confirm、prompt窗口等。
线程化的解释器
顾名思义,线程化的解释器就是利用单独的线程来解释HTML文档。因为在WebKit,网络资源的字节流自IO线程传递给渲染线程之后,后面的解释、布局和渲染等工作基本上都是工作在该线程,也就是渲染线程完成的。因为DOM树的过程只能渲染线程中进行。但是,从字符串到词语这个阶段也可交给单独的线程来做,Chromium浏览器使用的就是这个思想。
当字符串传递到HTMLDocumentParser类的时候,该类不是自己处理,而是创建一个新的对象BackgroundHTMLParser来负责处理,然后将这些数据交给对象。WebKit会检查是否需要创建用于解释字符串的线程HTMLParserThread。如果该线程已存在,WebKit就将刚刚的任务传递给这一新线程。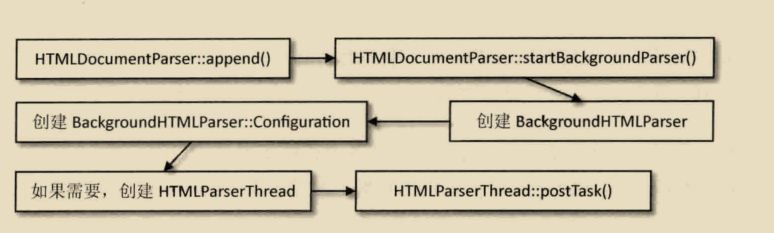
在HTMLOarserThread线程中,WebKit所做的事情包括字符串解释成一个个词语,然后使用之前提到XSSAuditor进行安全检查,这些任务跟之前介绍之前介绍的没有什么大的区别,只是在一个新的线程中执行而已。主要的区别在与解释成词语之后,WebKit会分批次的将结果词语传递给渲染线程。

JavaScript 的执行
在HTML解释器的工作过程中,可能会有JavaScript代码需要执行,它发生在字符串解释称词语之后、创建各种节点的时候。这也是为什么全局执行的JavaScript代码不能访问DOM树的原因—因为DOM树还没有被创建完成呢。
WebKit将DOM树创建过程中需要执行的JavaScript引擎来执行Node节点包含的代码,具体可以参考“HTMLScriptRunner::executeParsingBlockingScript”方法。
因为JavaScript代码可能会调用例如:document.write()来修改文档结构,所以JavaScript代码的执行会阻碍后面节点的创建,同事当然也会阻碍后面的资源下载,者死后WebKit对需要的什么资源一无所知,这导致了资源不能够并发的下载这一严重影响性能的问题。
- 将“script”元素加上“async”属性,表明这是一个可以异步执行的JavaScript代码。
- 另外一种方法将“script”元素放在“body”最后。
DOM的事件机制
在介绍了DOM中关于“core”部分的内容后,下面还有一个很重要的部分,那就是事件的处理机制。事件的工作过程
事件在工作过程中使用两个主体,第一个是事件(event),第二个是事件目标(EventTarget)。WebKit中用EventTarget类来表示DOM规范中Events部分定义的事件目标,
每个事件都有属性来标记该事件的事件目标。当事件到达事件目标(如一个元素节点)的时候。在这个目标上注册的监听者(Event Listeners)都会被触发调用,当然这些监听者的调用顺序是不固定的,所以不能依赖监听者注册的顺序来决定你的代码逻辑。
让我们看看DOM标准是如何定义EventTarget接口的,
事件处理最重要的部分就是事件捕获(Event capture)和事件冒泡(Event bubbling)这两种机制。
当渲染引擎接收到一个事件的时候,他会通过HitTest检查那个元素是直接的事件目标。以“img”为例,假设它是事件的直接目标,这样,事件会经过自顶向下和字底向上过程。
事件的捕获是自定向下,这也就是说,之间先到document节点,然后一路到达目标节点。document=》html=》body->img这样一个顺序。事件可以在这一传递过程中被捕获,只需要在注册监听者的时候设置相应的参数即可。
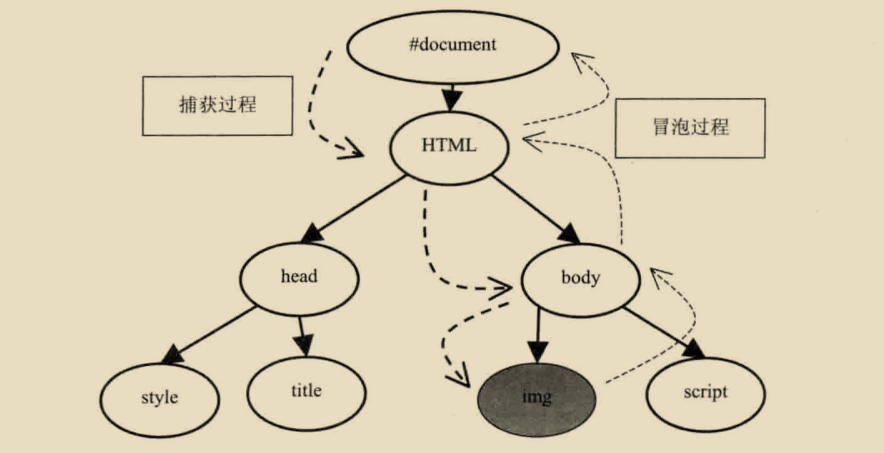
事件的冒泡过程是从下向上的顺序买他的默认行为是不冒泡,但是事件包含一个是否冒泡的属性。这一属性为真的时候,渲染引擎会将改时间首先传递给事件目标节点的父亲,然后是父亲的父亲。同捕获动作一样。可以使用“stopPropagation”阻止事件向上传递。
WebKit的事件处理机制
DOM的事件分为很多种,与用户相关的指示其中的一直,成为UIEvent,其它的包括CustomEvent、MutationEvent等。UIEvent有可以分为很多种,包括但是不限于FocusEvent、MouseEvent、keyboardEvent、CompoisitionEvent等。
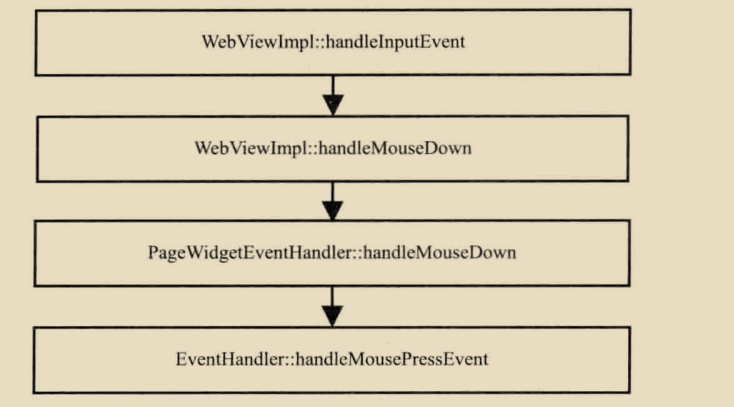
基于WebKit的浏览器事件处理过程,首先是做HitTest,查找事件元素发生处的元素,检测该元素有无监听者,如果网页的相关节点注册了事件的监听者,那么浏览器会把事件派发给WebKit内核来处理。同时,浏览器也可能需要理解和处理这样的事件。这主要是因为,有些事件浏览器必须响应从而对网页默认处理。
EventHandler类是处理事件的核心类,他除了需要将各种事件出给JavaScript引擎以调用想用的监听者之外,它还会是被鼠标事件,来触发盗用右键菜单、拖放效果等与事件密切相关的工作,而且EventHandler类还支持网页多框结构。
影子(Shadow)DOM
影子DOM是一个新东西,它主要解决了一个文档中可能需要大量交互的多个DOM输建立和维护各自功能边界问题。
什么是影子DOM
想象一下网页的基础库开发者这样一个用户界面的控件—这个控件可能由一些HTML的标签元素组成,这些元素可以组成一颗DOM树,这样一个HTML控件可以被到处使用,但是问题随之而来,那就是每个使用控件的地方都会知道这个子树的结构。当网页的开发者余姚访问页面DOM数的时候,这些控件内部的DOM子树都会暴露出来,这些暴露的节点不仅可能给DOM树的遍历带来很多麻烦,而且也可能给CSS的央视选择带来问题,因为选择其无意中可能会改变这些内部节点样式,从而导致很奇怪的控件界面。
这的确是一个巨大的挑战,如何将内部的节点信息封装起来,就像C++语言的类一样,同时又能够将这些节点渲染出来呢?这就是W3C工作组提出的影子DOM概念。影子DOM的规范草案能够使得一些DOM节点在特定范围内可见,而在网页的DOM树中却不可见,但是网页渲染的结果包含了这些节点,这就是的封装变得容易很多。
HTML5支持很多新的特性,例如音频、视频的支持,这些元素其实室友很复杂的控制界面组成,但是无法找到相应的节点。

若有收获,就点个赞吧
0 人点赞
