系统可能在任何两次写入之间崩溃或断点,因此磁盘上状态可能仅部分更新。如何确保文件系统将磁盘上的结构映像保持在合理的状态?
42.1 一个详细的例子
文件系统初始状态:只有一个文件,它大小为1,因为只有一个块
该文件信息如下,只有一个直接指针指向一块,其余直接指针都没用上:
向文件追加内容时,要给它添加一个新数据块,因此必须更新3个磁盘上的结构:inode(要让一个直接指针指向新分配的数据块)、新数据块和数据位图(表示新数据块已被分配:

文件系统要对磁盘进行3次单独写入。这些写操作不会立即发生,现在内存中缓存一下,再一起写入。然而可能会发生崩溃,从而干扰磁盘的更新。特别的,如果在三次中的一次或两次完成后发生崩溃,文件系统就会处于尴尬的状态。
42.2 解决方案1:文件系统检查程序
UNIX工具:fsck。查找不一致并修复它们。
- 超级块:fsck检查超级块是否合理。如果找到一个可疑的超级块,系统可以决定使用备用副本。
- 空闲块:fsck扫描inode、间接块、双重间接块等,以了解当前在文件系统中分配的块。利用这些信息生成正确版本的分配位图。因此如果位图和inode之间存在不一致,则通过信任inod内的信息来解决它。
- inode状态:检查每个inode是否存在损坏或其他问题。如果inode字段存在问题不易修复,那么被认为是可疑的,并被fsck清楚,inode位图相应的更新。
- inode链接:为验证inode链接数,fsck从根目录开始扫描整个目录树,为文件系统中的每个文件和目录构建自己的链接计数。如果新计算的计数与inode中的技术不匹配,覆写inode中的计数。
- 重复:检查是否有不同的inode引用同一个块。
- 坏块:如果指针显然指向超出其有效范围的某个值镇,就是“坏的”,fsck从inode或间接块中删除该指针。
- 目录检查:fsck不了解用户文件的内容。但是目录包含由文件系统本身创建的特定格式的信息。fsck对每个目录的内容执行额外的完整性检查。确保“.”和“..”是前面的条目,目录条目中引用的每个inode都已分配,整个层次结构中没有目录的引用超过一次。
fsck太慢了。
42.3 解决方案2: 日志(或预写日志)
基本思路:更新磁盘时,在覆写结构之前,首先写下一个小注记(在磁盘上一个众所周知的位置),描述将要做的事。通过将注释写入磁盘,可以保证在更新磁盘发生崩溃时,能够返回并查看之前做的注记,然后重试。
在崩溃之后准确知道要修复的内容(以及修复方式),而不必扫描整个磁盘。
带有日志的文件系统如下:
数据日志
此处再次想将inode、位图、数据块写入磁盘。再将它们写入最终磁盘位置前,先将它们写入日志,日志:
日志中写了五个块:
事务开始(TxB)告知有关此更新的信息,包括对文件系统即将进行的更新的相关信息(如块 I[v2]、B[v2]和 Db 的最终地址),以及某种事务标识符(TID)。
中间三个块只包含块本身的确切内容,即物理日志,因为将更新的确切物理内容放在日志中。
最后一个块(TxE)是记录该事务结束的标记,也会包含TID。
如果在写入日志期间发生崩溃,简单做法是将事务中的块一次发出一个,等待每个完成再发出下一个。但是太慢了。
如果采用一次将所有块写入日志,那么不可避免的会遇到写入一部分的时候发生崩溃。磁盘内部可以执行调度并以任何顺序完成大批写入的小块。
为避免该问题,文件系统分两步发出事务写入:
- 将TxE块之外的所有块写入日志,同时发出这些写入。
- 当写入完成时,文件系统会发出TxE的写入。
此过程的重要方面是磁盘提供的原子性保证。
由于磁盘保证任何512字节的操作都是原子的。因此为了确保TxE的写入是原子的,应该使它成为一个512字节的块。
1.日志写入:将事务的内容(包括 TxB、元数据和数据)写入日志,等待这些写入完成。
2.日志提交:将事务提交块(包括 TxE)写入日志,等待写完成,事务被认为已提交 (committed)。
3.加检查点:将更新内容(元数据和数据)写入其最终的磁盘位置。
恢复
如果崩溃发生在事务被安全写入日志之前:跳过待执行的更新
如果在事务已提交到日志之,但在加检查点之前崩溃:系统引导时文件系统扫描日志,并查找已提交到磁盘的事务。然后这些事务被重放(按顺序),文件系统再次尝试将事务中的块写入最终的磁盘位置。重做日志。
在加检查点期间任何时刻崩溃都没问题。
批处理日志更新
如果在同一个目录下同时创建两个文件,那么在写入磁盘的时候,由于同一个inode块中都有inode,可能会一遍又一遍地写入这些相同的块。
解决:文件系统不会一次一个地向磁盘提交每个更新。可以将所有更新缓冲到全局事务中。到最后一块写入磁盘。避免了对磁盘的过多的写入流量。
使日志有限
日志太大的问题:
- 日志越大,恢复时间越长,因为恢复过程必须重放日志中的所有事物。
- 当日志已满(或接近满)时,不能向磁盘提交进一步的事务,从而是文件系统无用。
所以一旦事务被加检查点,文件系统就应释放它在日志中占用的空间,允许重用日志空间。
只需要在日志超级块中标记日志中最旧和最新的事务,这个是不断更新的:
元数据日志
基于日志的协议,导致每一个块需要写入磁盘两次(一次是在日志中作为事务,防止崩溃;一次是真正写入)。
一种更简单的日志:有序日志,也叫元数据日志。与数据日志的唯一差别在于:它没有将用户数据写入日志。
只有inode和bitmap信息,没有具体的用户数据。 在写入元数据之前,先将用户数据写入磁盘。
元数据日志的具体执行顺序:
1.数据写入:将数据写入最终位置,等待完成(等待是可选的,详见下文)。
2.日志元数据写入:将开始块和元数据写入日志,等待写入完成。
3.日志提交:将事务提交块(包括 TxE)写入日志,等待写完成,现在认为事务(包括数据)已提交。
4.加检查点元数据:将元数据更新的内容写入文件系统中的最终位置。
5.释放:稍后,在日志超级块中将事务标记为空闲。
通过强制先写入数据,文件系统可以保证inode块的指针永远不会指向垃圾。
数据日志的时间线: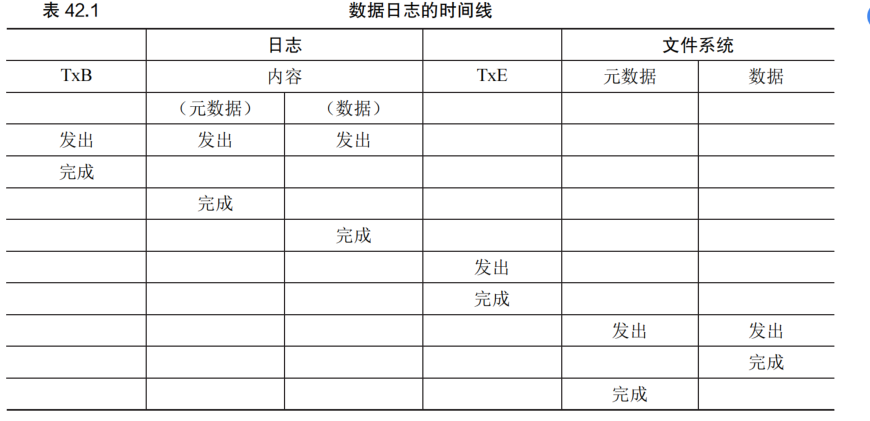
元数据日志的时间线: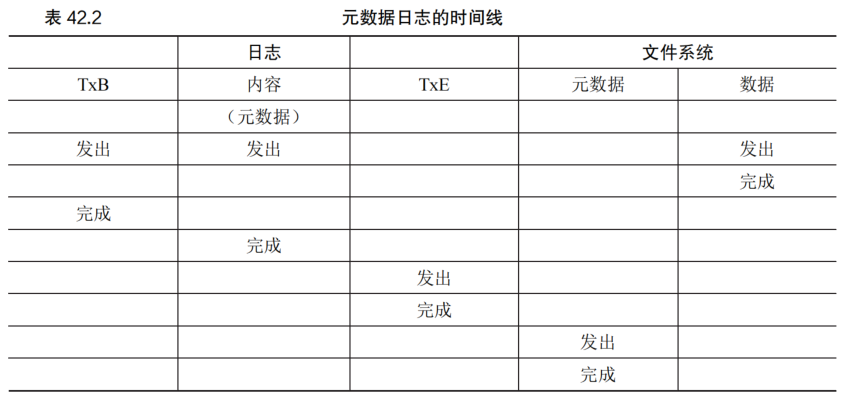
HINT:在逻辑上,数据写入可以与对事务开始的写入和日志的内容一起发出。但是,必须在事务结束发出之前发出并完成。

若有收获,就点个赞吧
0 人点赞
