5.1 内存模型基础
5.1.2 对象、内存区域和并发
假设两个线程访问同一内存区域,却没有强制它们服从一定的访问次序,如果其中至少有一个是非原子化访问,并且至少有一个是写操作,就会出现数据竞争,导致未定义行为。
5.2 C++中的原子操作及其类别
原子操作是不可分割的操作。在系统的任一线程内,都不会观察到原子操作出于半完成状态,要么完全做好、要么完全没做。
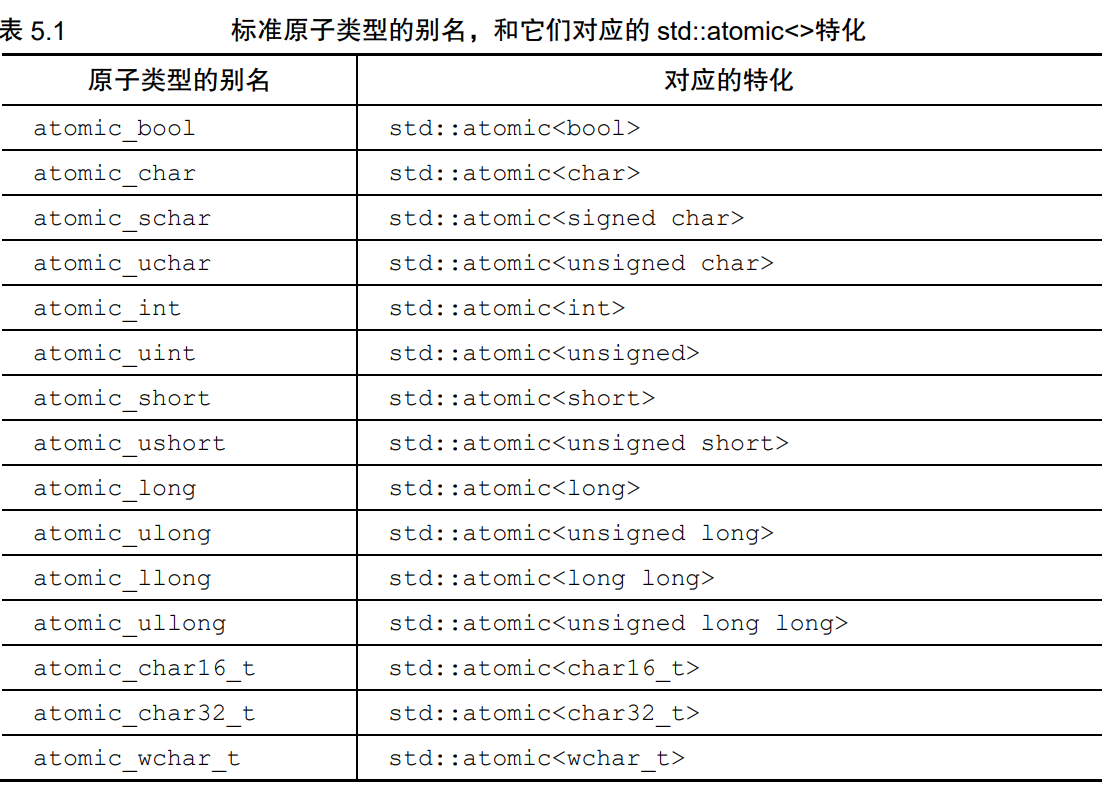
5.2.1 标准原子类型
原子操作的关键用途是取代需要互斥的同步方式。
只有一个原子类型不提供is_lock_free()成员函数:**std::atomic_flag**,是一个简单的布尔标志,所以必须采用无锁操作。只要利用这种无锁布尔标志,就可以实现一个简易的锁,进而基于该锁实现其他原子类型。std::atomic_flag的对象在初始化时清零,随后即可通过成员函数test_and_set()查值并设置成立,或者由clear()清零。
由于不具备拷贝构造和拷贝赋值,所以标准的原子类型对象无法复制和赋值。
类模板std::atomic<>并不局限于特化类型,也具有泛化模板,可依据用户自定义类型创建原子类型的变体。仅具有以下操作:
load():接受用户自定义类型的赋值。store():转化为用户自定义类型、exchange()、compare_exchange_weak()、compare_exchange_strong()。
对原子类型上的每一种操作都可以提供额外的参数,从枚举类型std::memory_order取值,用于设定所需的内存次序语意。
5.2.2 操作 std::atomic_flag
std::atomic_flag表示一个布尔标志,只有两种状态:成立或置零。唯一用途是充当构建单元,一般不会直接使用它。std::atomic_flag类型的对象必须由宏ATOMIC_FLAG_INIT初始化,它将标志初始化为置零状态:
std::atomid_flag = ATOMIC_FLAG_INIT;
所有原子类型中,只有std::atomic_flag必须采用这种特殊初始化处理,也是唯一保证无锁的原子类型。
完成std::atomic_flag的初始化后,只能执行 3 种操作:
- 销毁(析构函数);
- 置零(成员函数
clear()) - 读取原有的值并设置标志成立(成员函数
test_and_set())。

正因为std::atomic_flag功能有限,所以可以完美扩展成自旋锁互斥。最开始令原子标志置零表示互斥没有上锁。反复调用**test_and_set()**尝试锁住互斥,一旦读取的值变成false说明线程已将标志设置成立(新值为true)则循环终止。将标志置零即可解锁互斥。
//采用 std::atomic_flag 实现自旋锁互斥#include <atomic>#include <iostream>#include <mutex>#include <thread>#include <vector>using namespace std;class spinlock_mutex {std::atomic_flag flag;public:spinlock_mutex() : flag(ATOMIC_FLAG_INIT) {}void lock() {while (flag.test_and_set(std::memory_order_acquire));}void unlock() {flag.clear();}};int k = 0;auto main() -> int {spinlock_mutex m;std::vector<std::thread> vec{};for (int i = 0; i < 20; ++i)vec.emplace_back([&] {std::lock_guard lk(m);++k;});for (auto& p : vec)p.join();std::cout << k << endl;}
5.2.3 操作 std::atomic
std::atomic<bool>无法拷贝构造或拷贝赋值,但是还是可以根据非原子布尔量创建其对象: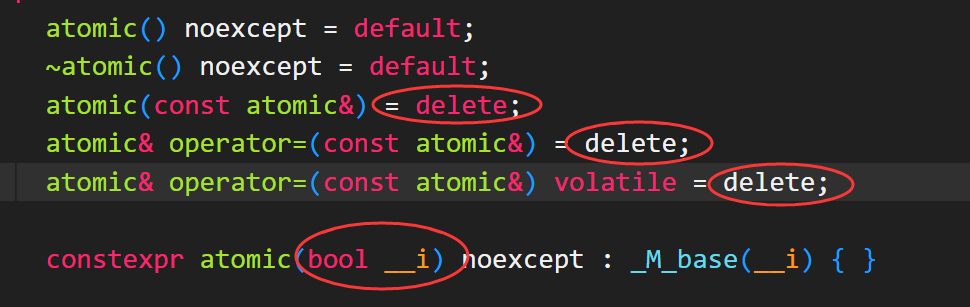
HINT:按照C++惯例,赋值操作符通常返回一个引用,指向接受赋值的目标对象(登号左侧的对象)。但是std::atomic<bool>赋值不返回引用,直接返回赋予的布尔值。
假设返回的是指向原子变量的引用,若有代码依赖赋值操作的结果,那它必须随之显式地加载该结果的值,而此时另一线程可能在返回和加载间改动其值。所以按值返回可以避开多余的加载动作,从而保证获取的值正确。
std::atomic<bool>的写操作通过调用**store()**,也可以设定内存次序语义。此外std::atomic<bool>提供了更通用的成员函数**exchange()**以代替**test_and_set()**,它获取原有的值,还可以自行选定新值作为替换。 std::atomic<bool>还支持单纯的读取(没有伴随的修改行为):隐式做法是将实例转换为普通布尔值,显式做法是调用**load()**。
#include <atomic>#include <iostream>using namespace std;auto main() -> int {std::atomic_bool b;bool x = b.load();std::cout << std::boolalpha << "x = " << x << std::endl;b.store(true);x = b.exchange(false, std::memory_order_acq_rel);std::cout << "x = " << x << std::endl;}//resultflasetrue
5.2.4 操作 std::atomic:算数形式的指针运算
与atomic<bool>大致相同。
std::atomic<T*>提供的新操作是算数形式的指针运算。成员函数fetch_add()和fetch_sub()给出最基本的操作,分别就对象中存储的地址进行原子化加减,但是返回的是运算之前的地址。
#include <atomic>#include <cassert>#include <iostream>using namespace std;class Foo {};auto main() -> int {Foo some_array[5];std::atomic<Foo*> p(some_array);Foo* x = p.fetch_add(2);assert(x == some_array);assert(p.load() == &some_array[2]);x = (p -= 1);assert(x == &some_array[1]);assert(p.load() == &some_array[1]);}
5.2.6 泛化的 std::atomic<>类模板
可以根据自定义类型创建其他原子类型,所提供的接口与**std::atomic<bool>**相同。
不能随意套用任何自定义类型,对于某个自定义类型UDT,要满足下列条件才能具现化出std::atomic<UDT>:
- 必须具备 trivial 拷贝赋值操作符(展现出 bitwise 逐位次拷贝);
- 不得含有任何虚函数,不可以派生自虚基类;
- 必须由编译器代其隐式生成拷贝赋值操作符;
- 另外,若具有基类或非静态数据成员,则必须同样具备 trivial 拷贝赋值运算符。
所以,根据以上要求,可以看出,赋值操作不涉及任何用户编写的代码,因此编译器可以借助**memcpy()**或采取与之等效的行为完成该操作。
如果采用锁保护数据,而代码又涉及使用者提供的函数,则不得将受保护数据的指针或引用传入该函数,会让它脱离锁的作用域。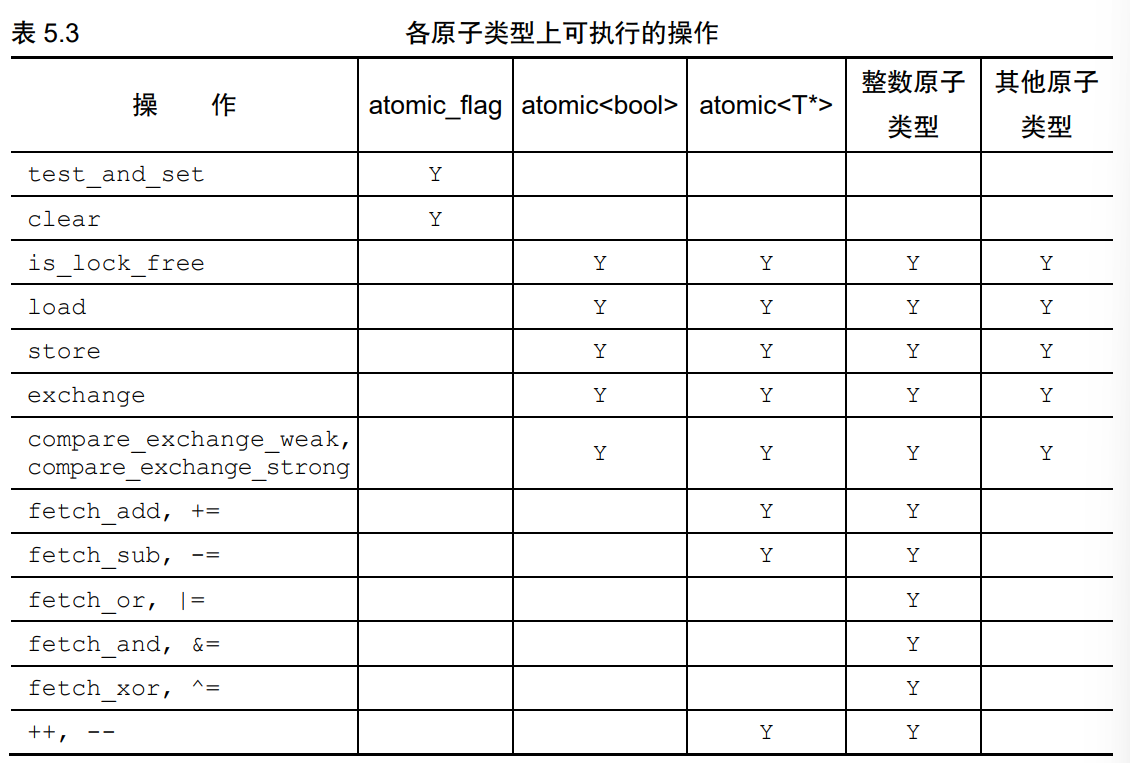
5.2.7 原子操作的非成员函数
C++提供非成员函数,按原子化形式访问**std::shared_ptr<>**的实例。但是这些操作的第一个参数都是std::shared_ptr<>*类型:
std::shared_ptr<int> p{};void process_global_data() {std::shared_ptr<int> local = std::atomic_load(&p);}void update_global_data() {std::shared_ptr<int> local(new int(3));std::atomic_store(&p, local);}
5.3 同步操作和强制次序
5.3.1 同步关系
同步关系只存在于原子类型的操作之间。
同步关系的基本思想是:对变量x执行原子写操作 W 和原子读操作 R,且两者都有适当的标记。只要满足下面其中一点,即彼此同步:
- R 读取了 W 直接存入的值;
- W 所属线程随后还执行了另一原子写操作, R 读取了后面存入的值;
- 任意线程执行一连串“读-改-写”操作,而其中第一个操作读取的值由 W 写出。
5.3.2 先行关系
先行关系和严格先行关系在程序中确立操作次序:清楚界定哪些操作产生的结果可以被哪些操作看到。
在线程间先行关系和先行关系中,各种操作时都被标记为memory_order_consume,而严格先行关系则无此标记。
5.3.3 原子操作的内存次序
原子类型服从六种内存次序:memory_order_relaxed、memory_order_consume、memory_order_acquire、memory_order_release、memory_order_acq_rel和memory_order_seq_cst。其中最后一个是最严格的内存次序。
代码中的内存次序因采用不同内存模型而异。
1、先后一致次序
先后一致次序为默认内存次序。如果采用先后一致次序,则针对多个线程的并发操作,可以写出他们全部可能的顺序组合,将操作不一致的剔除,从而验证代码是否符合预期。
虽然这种内存次序易于理解,但是会导致严重的性能损失,因为必须在多处理器之间维持全局操作次序。
若某项操作标记为memory_order_seq_cst,则编译器和 CPU 严格遵循源码逻辑流程的先后顺序。 在相同的线程上,以该项操作为界,其后方的任何操作不得重新编排到它前面,而前方的任何操作不得重新编排到它后面,其中“任何”是指带有任何内存标记的任何变量之上的任何操作。
//保持先后一致次序会形成一个全局总操作序列#include <atomic>#include <cassert>#include <iostream>#include <thread>using namespace std;std::atomic_bool x, y;std::atomic_int z;void write_x() {x.store(true, std::memory_order_seq_cst);}void write_y() {y.store(true, std::memory_order_seq_cst);}void read_x_then_y() {while (!x.load(std::memory_order_seq_cst));if (y.load(std::memory_order_seq_cst))++z;}void read_y_then_x() {while (!y.load(std::memory_order_seq_cst));if (x.load(std::memory_order_seq_cst))++z;}auto main() -> int {x = false;y = false;z = 0;std::thread a(write_x);std::thread b(write_y);std::thread c(read_x_then_y);std::thread d(read_y_then_x);a.join();b.join();c.join();d.join();assert(z.load() != 0);}
断言无论如何不会触发。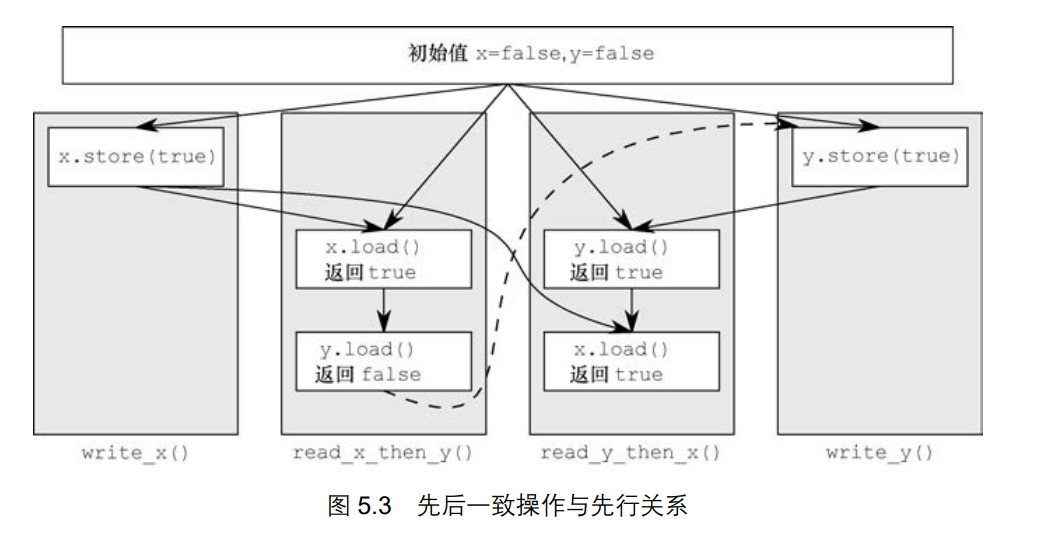
先后一致次序要求在所有线程间进行全局同步,因此也是代价最高的内存次序。
2、非先后一致次序
即使在多个线程上运行的代码相同,由于某些线程上的操作没有显式的次序约束,因此他它们有可能无法就多个事件的发生次序达成一致,而在不同的 CPU 缓存或内部缓冲中,同一份内存数据也可能具有不同的值。
即:线程之间不必就事件发生次序达成一致。
如果没有指定程序服从哪种内存次序,则采用默认内存次序。要求:全部线程在每个独立变量上都达成一致的修改序列。不同变量上的操作构成其特有的序列。
3、宽松次序memory_order_relaxed,若采用宽松次序,那么原子类型上的操作不存在同步关系。在单一线程内,同一个变量上的操作仍然服从先行关系,但几乎不要求线程之间存在任何次序关系。
#include <assert.h>#include <atomic>#include <thread>std::atomic<bool> x, y;std::atomic<int> z;void write_x_then_y() {x.store(true, std::memory_order_relaxed);y.store(true, std::memory_order_relaxed);}void read_y_then_x() {while (!y.load(std::memory_order_relaxed));if (x.load(std::memory_order_relaxed)) ++z;}int main() {x = false;y = false;z = 0;std::thread a(write_x_then_y);std::thread b(read_y_then_x);a.join();b.join();assert(z.load() != 0);}
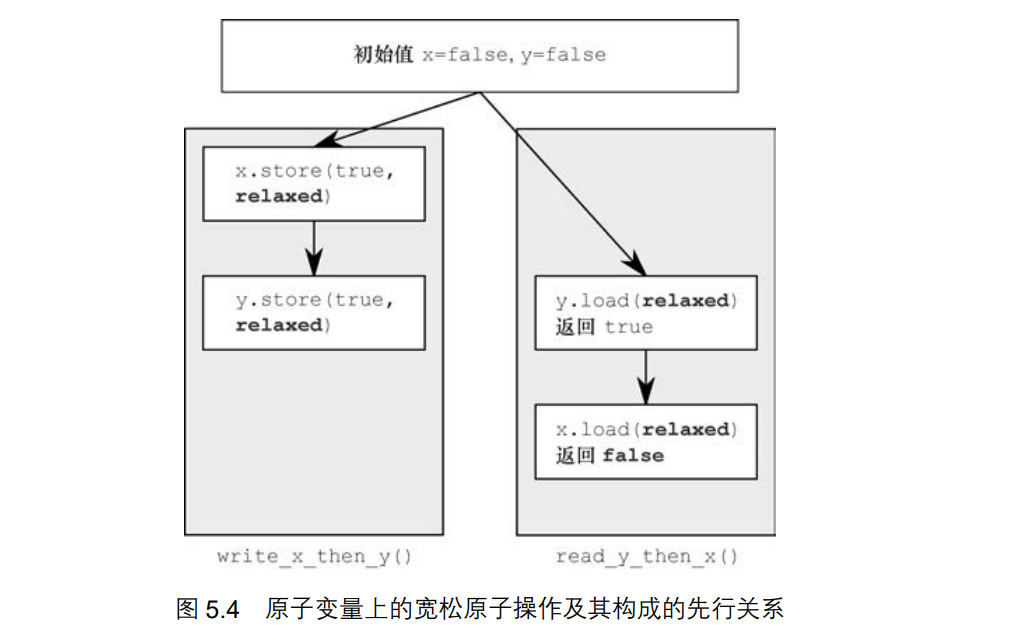
变量**x**的存储操作和载入操作分属不同线程,因为采用了宽松次序,所以后者不一定能见到前者执行产生的效果,即存储的新值 true 还停留在 CPU 缓存中,而读取的 false 值是来 自内存的旧值。
#include <atomic>#include <iostream>#include <thread>std::atomic_int x(0), y(0), z(0); // 1std::atomic_bool go(false); // 2unsigned const loop_count = 10;struct read_values {int x, y, z;};read_values values1[loop_count];read_values values2[loop_count];read_values values3[loop_count];read_values values4[loop_count];read_values values5[loop_count];void increment(std::atomic_int* var_to_inc, read_values* values) {while (!go) // 3std::this_thread::yield();for (unsigned i = 0; i < loop_count; ++i) {values[i].x = x.load(std::memory_order_relaxed);values[i].y = y.load(std::memory_order_relaxed);values[i].z = z.load(std::memory_order_relaxed);var_to_inc->store(i + 1, std::memory_order_relaxed); // 4std::this_thread::yield();}}void read_vals(read_values* values) {while (!go) // 5std::this_thread::yield();for (unsigned i = 0; i < loop_count; ++i) {values[i].x = x.load(std::memory_order_relaxed);values[i].y = y.load(std::memory_order_relaxed);values[i].z = z.load(std::memory_order_relaxed);std::this_thread::yield();}}void print(read_values* v) {for (unsigned i = 0; i < loop_count; ++i) {if (i)std::cout << ",";std::cout << "{" << v[i].x << "," << v[i].y << "," << v[i].z << "}";}std::cout << std::endl;}auto main() -> int {std::thread t1(increment, &x, values1);std::thread t2(increment, &y, values2);std::thread t3(increment, &z, values3);std::thread t4(read_vals, values4);std::thread t5(read_vals, values5);go = true; // 6t5.join();t4.join();t3.join();t2.join();t1.join();print(values1); //7print(values2);print(values3);print(values4);print(values5);}
4、理解宽松次序
(看书…)
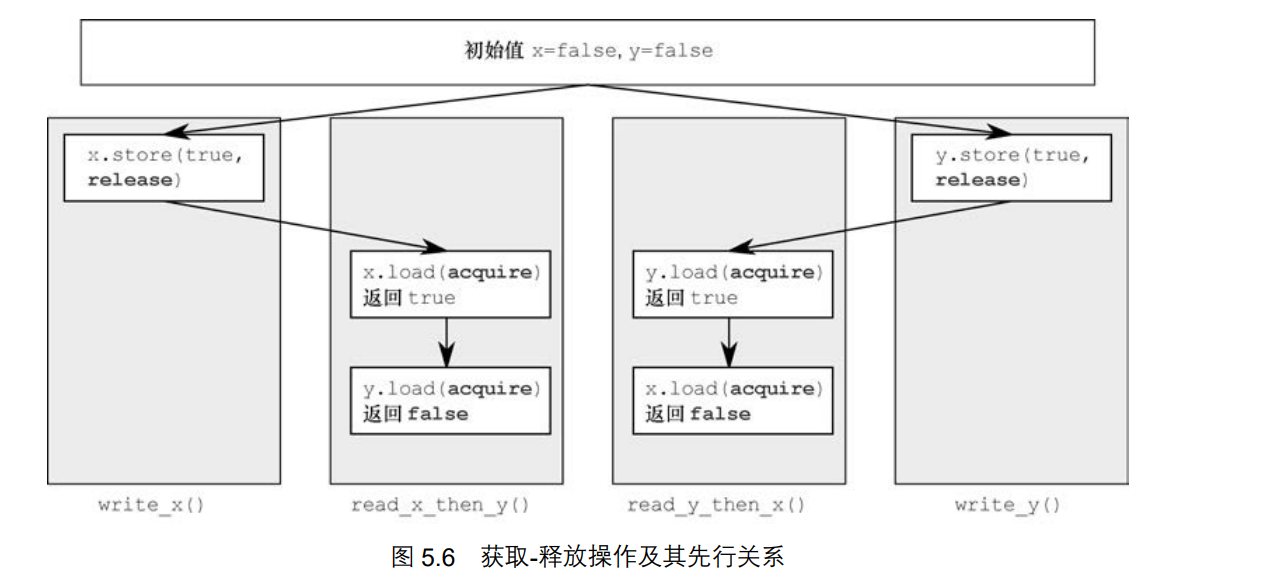
5、获取-释放次序
获取-释放次序比宽松次序严格一些,会产生一定程度的同步效果,而不会服从先后一致次序的全局总操作序列。在该内存模型中,原子化载入即为获取操作**memory_order_acquire**,原子化存储即为释放操作**memory_order_release**,而原子化“读-改-写”操作即为获取或释放操作,或二者都是memory_order_acq_rel。
这种内存次序在成对的读写线程之间起到同步作用,释放与获取操作构成同步关系,前者写出的值由后者读取。
#include <atomic>#include <cassert>#include <iostream>#include <thread>using namespace std;std::atomic_bool x, y;std::atomic_int z;void write_x() {x.store(true, std::memory_order_release);}void write_y() {y.store(true, std::memory_order_release);}void read_x_then_y() {while (!x.load(std::memory_order_acquire));if (y.load(std::memory_order_acquire))++z;}void read_y_then_x() {while (!y.load(std::memory_order_acquire));if (x.load(std::memory_order_acquire))++z;}auto main() -> int {x = false;y = false;z = 0;std::thread a(write_x);std::thread b(write_y);std::thread c(read_x_then_y);std::thread d(read_y_then_x);a.join();b.join();c.join();d.join();assert(z.load() != 0);}
#include <atomic>#include <cassert>#include <thread>using namespace std;std::atomic_bool x, y;std::atomic_int z;void write_x_then_y() {x.store(true, std::memory_order_relaxed); // 1y.store(true, std::memory_order_release); // 2}void read_y_then_x() {while (!y.load(std::memory_order_acquire)) // 3;if (x.load(std::memory_order_relaxed)) // 4++z;}auto main() -> int {x = false;y = false;z = 0;std::thread a(write_x_then_y);std::thread b(read_y_then_x);a.join();b.join();assert(z.load() != 0); // 5}

获取-释放次序可用于多线程之间数据的同步,即使“过渡线程”的操作不涉及目标数据,也照样可行。
再看原书P163附近。
std::atomic<int> data[5];std::atomic<bool> sync1(false),sync2(false);void thread_1(){data[0].store(42,std::memory_order_relaxed);data[1].store(97,std::memory_order_relaxed);data[2].store(17,std::memory_order_relaxed);data[3].store(-141,std::memory_order_relaxed);data[4].store(2003,std::memory_order_relaxed);sync1.store(true,std::memory_order_release); // 1.设置sync1}void thread_2(){while(!sync1.load(std::memory_order_acquire)); // 2.直到sync1设置后,循环结束sync2.store(true,std::memory_order_release); // 3.设置sync2}void thread_3(){while(!sync2.load(std::memory_order_acquire)); // 4.直到sync1设置后,循环结束assert(data[0].load(std::memory_order_relaxed)==42);assert(data[1].load(std::memory_order_relaxed)==97);assert(data[2].load(std::memory_order_relaxed)==17);assert(data[3].load(std::memory_order_relaxed)==-141);assert(data[4].load(std::memory_order_relaxed)==2003);}

5.3.4 释放序列和同步关系
对于同一个原子变量,可以在线程 A 上对其执行存储操作,在线程 B 上对其执行载入操作,从而构成同步关系。即使存储和读取之间还存在着多个“读-改-写”操作,同步关系依然成立,前提是所有操作都采取了合适的内存序。
如果存储操作的标记是memory_order_release、memory_acq_rel或memory_order_seq_cst标记,而载入操作以memory_order_consume、memory_order_acquire或memory_order_seq_cst标记,这些操作前后相扣,每次载入操作的值都源自前面的存储操作,那么该操作链由一个释放序列组成。
#include <atomic>#include <iostream>#include <thread>#include <vector>std::vector<int> queue_data;std::atomic<int> count;void populate_queue() {unsigned const number_of_items = 20;queue_data.clear();for (unsigned i = 0; i < number_of_items; ++i)queue_data.push_back(i);count.store(number_of_items, std::memory_order_release);//1.最初的存储操作}void consume_queue_items() {while (true) {int item_index;//2.一项“读-改-写”操作if ((item_index = count.fetch_sub(1, std::memory_order_acquire)) <= 0) {; //3.等待队列容器装入新数据continue;}//4.从内部容器读取数据项是安全的queue_data[item_index - 1];}}auto main() -> int {std::thread a(populate_queue);std::thread b(consume_queue_items);std::thread c(consume_queue_items);a.join();b.join();c.join();}
虚线表示释放序列,实线表示先行关系:
5.3.5栅栏
#include <iostream>#include <atomic>#include <cassert>#include<thread>using namespace std;std::atomic_bool x, y;std::atomic_int z;void write_x_then_y() {x.store(true, std::memory_order_relaxed);std::atomic_thread_fence(std::memory_order_release);y.store(true, std::memory_order_relaxed);}void read_y_then_x() {while (!y.load(std::memory_order_relaxed));std::atomic_thread_fence(std::memory_order_acquire);if(x.load(std::memory_order_relaxed))++z;}auto main()->int {x = false;y = false;z = 0;std::thread a(write_x_then_y);std::thread b(read_y_then_x);a.join();b.join();assert(z.load() != 0);}
5.3.6 对非原子变量的操作排序
#include <atomic>#include <thread>#include <assert.h>#include<iostream>using namespace std;bool x=false; // x现在是一个非原子变量std::atomic<bool> y;std::atomic<int> z;void write_x_then_y() {x=true; // 1 在栅栏前存储xstd::atomic_thread_fence(std::memory_order_release);y.store(true,std::memory_order_relaxed); // 2 在栅栏后存储y}void read_y_then_x() {while(!y.load(std::memory_order_relaxed)); // 3 在#2写入前,持续等待std::atomic_thread_fence(std::memory_order_acquire);if(x) // 4 这里读取到的值,是#1中写入++z;}auto main()->int {x=false;y=false;z=0;std::thread a(write_x_then_y);std::thread b(read_y_then_x);a.join();b.join();assert(z.load()!=0); // 5 断言将不会触发}
推荐博客链接

若有收获,就点个赞吧
0 人点赞
