1 数据导入
打开SPSS,按照“文件—打开—数据”的操作顺序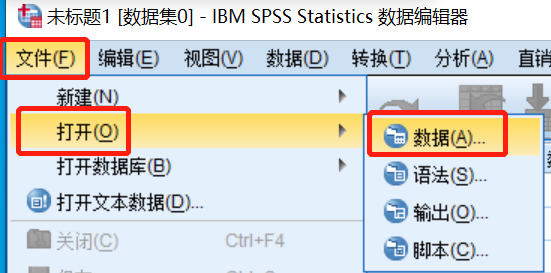
出现以下界面,选择数据所在的文件夹
在文件类型中选择“excel”,选中目标文件,点击“打开”
数据就成功导入SPSS了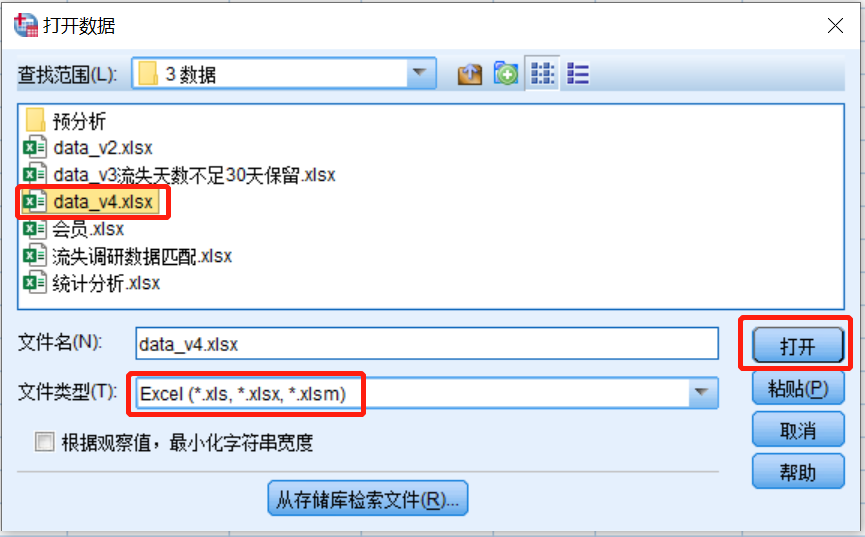
2 数据调整
2.1 单变量重新编码为单变量
反向数据调整:问卷中出现反向题,分析的时候,需要先转化过来 数据选项合并:如将年龄合并,15岁及以下、16-18岁、19-22岁、23-25岁、26-30岁的分类保持不变;将31-34岁,35-39岁,40岁及以上的用户合并为31岁及以上
按照“转换—重新编码为不同变量”的操作顺序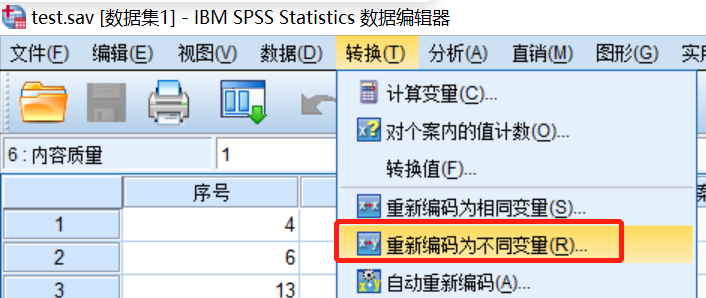
出现下图,将需要合并的变量放在右边的对话框中,
填写需生成的变量名“age1”,
点击“更改”,
点击“旧值和新值”
出现下图,
在左边的“旧值”中输入原始数值,在右边的“新值”中输入更改的数值
点击“添加”,一直到将所有的数据都添加进来,如下图
点击“继续”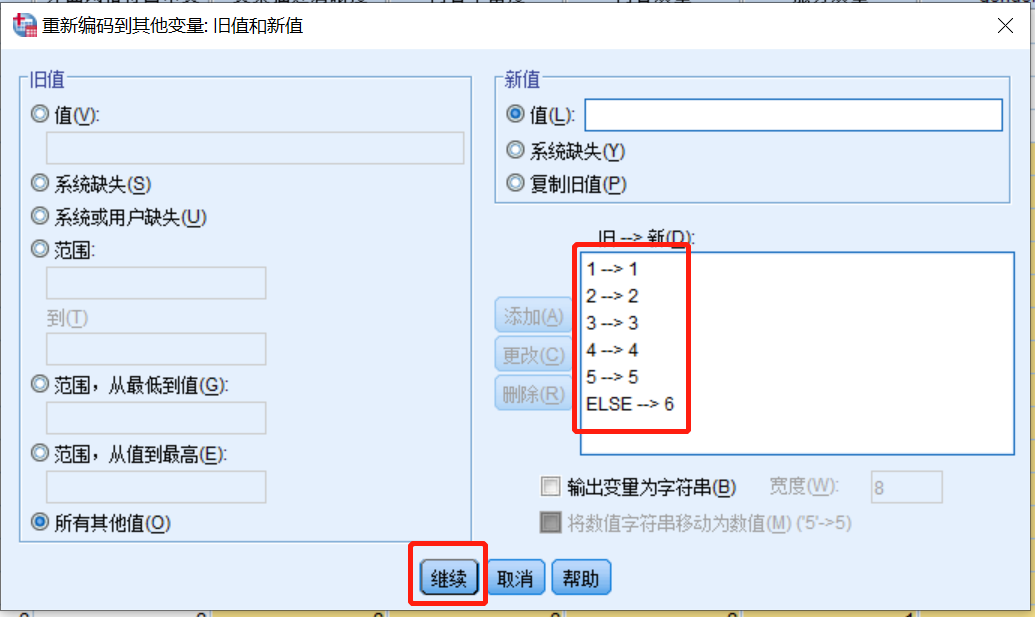
出现下图,
点击“确定”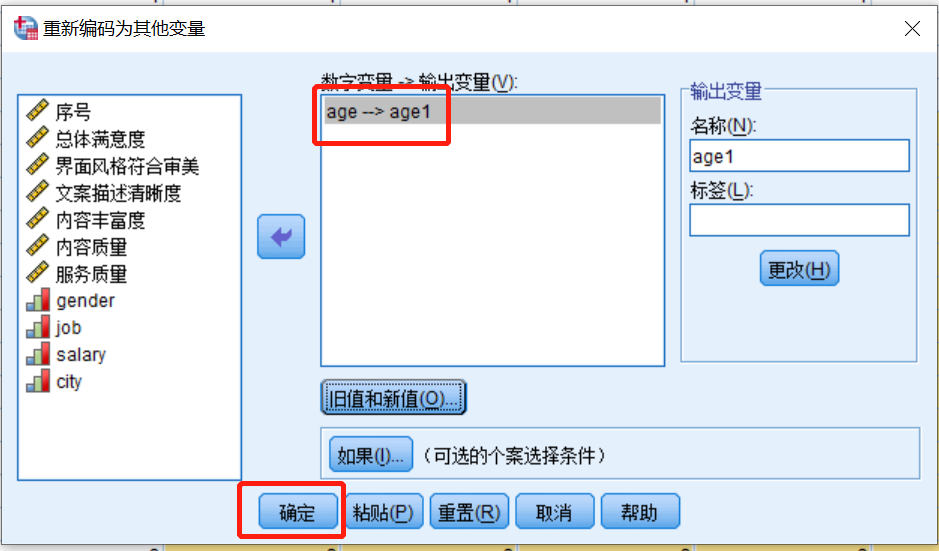
语法操作:
按照“文件—新建—语法”的操作顺序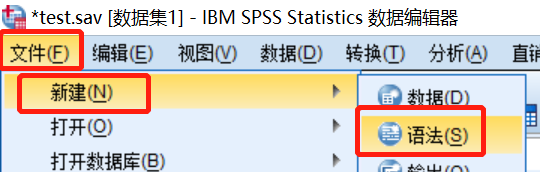
出现以下页面,在页面中输入语法,然后点击绿色的按钮,运行代码
语法如下:
RECODE city1 ('一线城市'=0) ('新一线城市'=1) ('二线城市'=2) ('三线城市'=3) ('四线城市'=4) ('五线城市'=5) ('其他'=5) INTO city.EXECUTE.RECODE age1 (1=1) (2=1) (3=2) (4=3) (5=4)(6=4)(7=5) INTO age.EXECUTE.RECODE job1 (1=1) (2=1) (3=2) (4=3) (5=3)(6=4)(7=4)(8=4)(9=4)(10=4)(11=4)(12=4)(13=4)(14=4)(15=4)(16=4)(17=4)(18=4) INTO job.EXECUTE.RECODE salary1 (1=1) (2=2) (3=3) (4=4) (5=5)(6=5)(7=5)(8=5)(9=5)(10=5)(11=5)(12=6) INTO salary.EXECUTE.
2.1 多变量重新编码为单变量
需要根据两道题,用户的选择,生成一个新的变量 比如题目1:用户是否使用竞品jp(0:没有使用竞品,1:使用竞品) 题目2:用户是否为竞品付费pay(0:没有为竞品付费,1:为竞品付费) 需要生成新的变量,用户类型type(1:没有使用竞品,1:使用竞品,但没为竞品付费,3:使用竞品,且为竞品付费)
if(jp=0) type=1 .if(jp=1 & pay=0) type=2.if(jp=1 & pay=1) type=3.
2.2 变量计算
变量计算:如需几个变量的和时,如总分等
按照“转换—计算变量”的操作顺序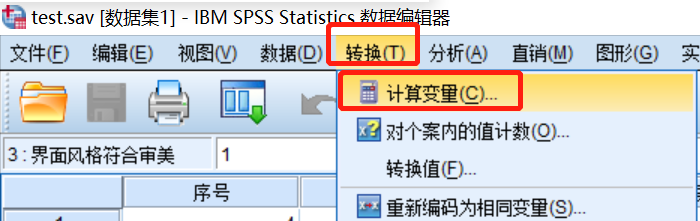
出现下图
在页面左上方“目标变量”写上新变量的名字,如“因子分”
在页面右上方将公式写出来,如加和等
点击确定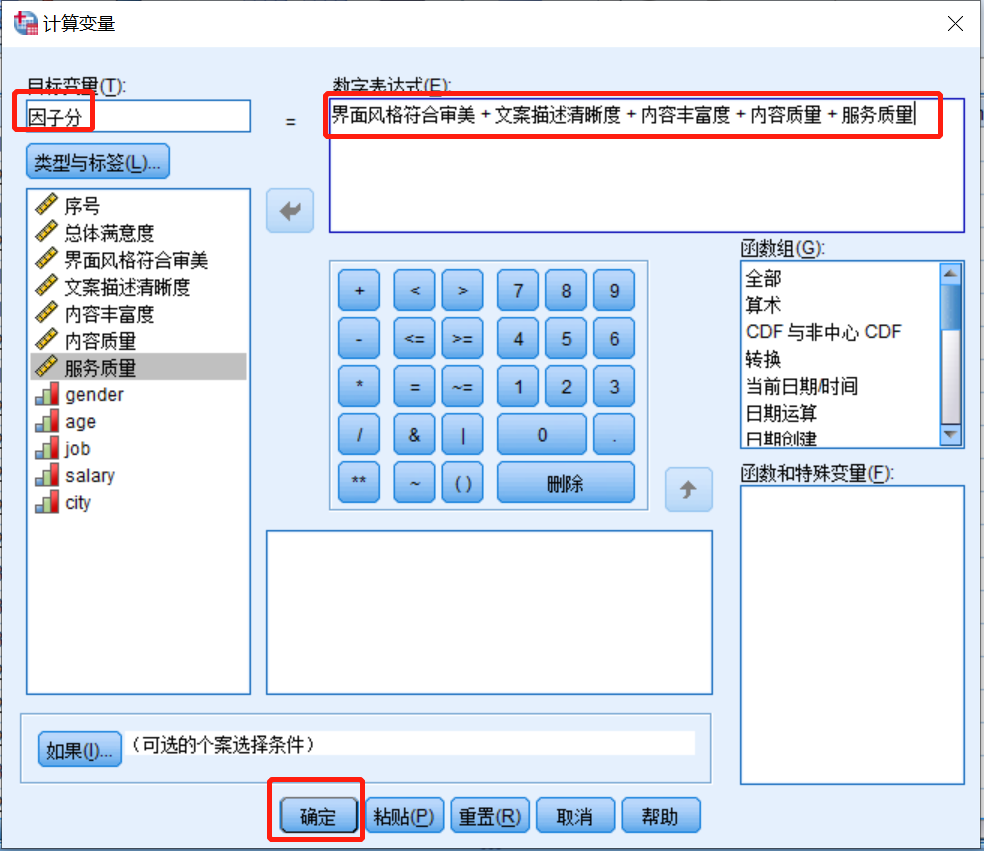
语法如下:
COMPUTE 因子分=界面风格符合审美 + 文案描述清晰度 + 内容丰富度 + 内容质量 + 服务质量.EXECUTE.
2.3 变量赋值
人口学变量的赋值、单选题的赋值等
点击SPSS页面左下角的“变量视图”
出现下图:
选中“gender”所在行,“值”所在列,点击交叉单元格的右边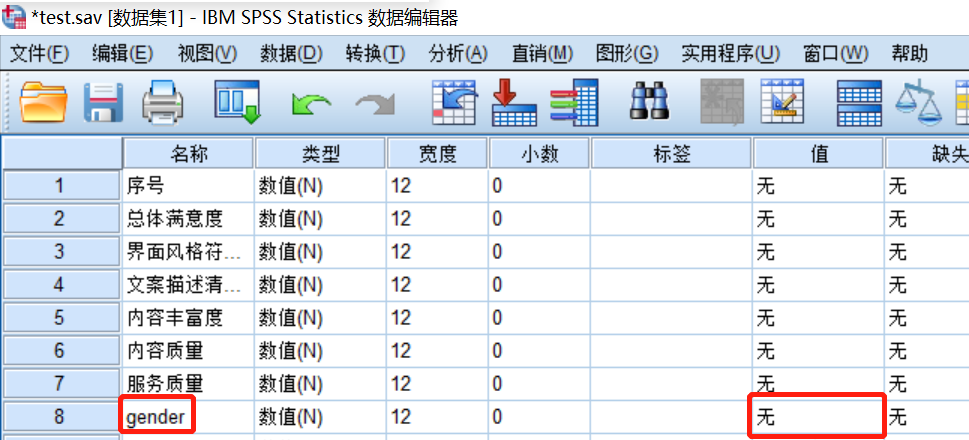
出现下图:
在“值”中输入问卷中的数字
在“标签”中输入数字代表的含义
然后点击“添加”
添加完成后,点击“确定”,即完成
赋值完成,如下图
语法如下:
*人口学选项赋值.value labels gender1 ‘男’2 ‘女’.value labels age1 '15岁及以下'2 '16-18岁'3 '19-22岁'4 '23-30岁'5 '31岁及以上'.value labels job1 '初中及以下在读'2 '高中在读'3 '大学在读'4 '工作人员'.value labels salary1 '无收入'2 '2000元以下'3 '2000-3999元'4 '4000-5999元'5 '6000元及以上'6 '我不想透露'.value labels city0 '一线城市'1 '新一线城市'2 '二线城市'3 '三线城市'4 '四线城市'5 '五线城市及以下'.
2.3 多列排序
对多列数据进行排序,优先年份排序,其次是id排序
年份升序,id降序
选中年份,在排列顺序中选择“升序”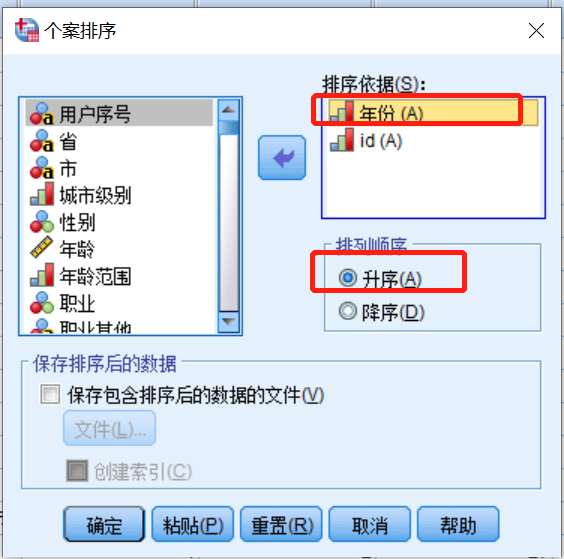
选中id,在排列顺序中选择“降序”,然后点击确定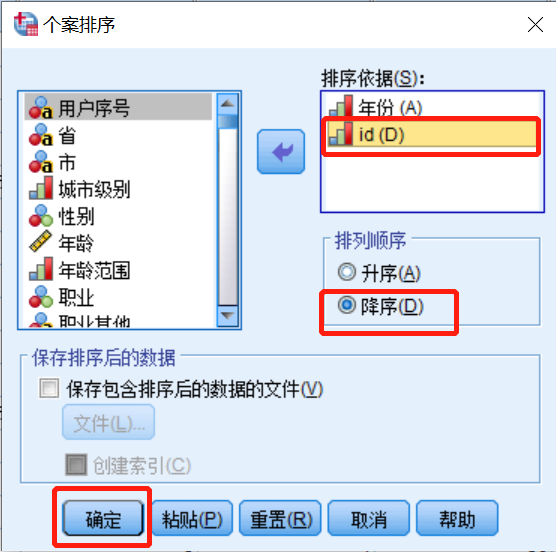
代码如下:
优先按年份排序,其次是id排序,年份和id均为升序SORT CASES BY 年份(A) id(A).优先按年份排序,其次是id排序,年份升序,id降序SORT CASES BY 年份(A) id(D).

若有收获,就点个赞吧
0 人点赞
