118 | 我们为什么要搭建一套MySQL的主从复制架构?(1)
1)mysql在生产环境,必须搭建一套主从复制的架构。高可用架构
2)部署两台服务器,每台都有一个mysql,一个是master(主节点),一个是slave(从节点)
3)系统平时连接到master节点写入数据,会把写入的数据自动复制到slave节点去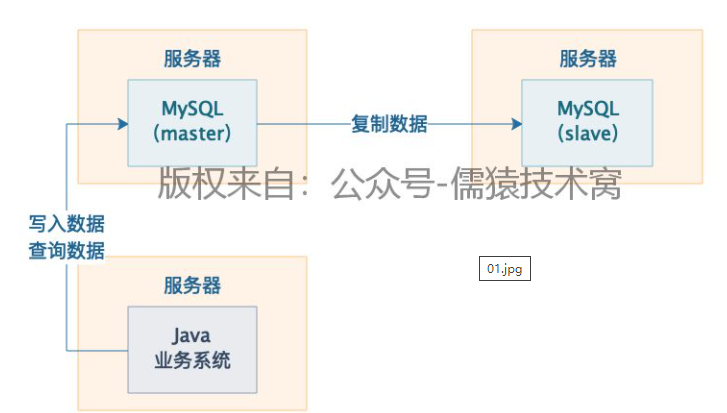
119 | 我们为什么要搭建一套MySQL的主从复制架构?(2)
1、读写分离架构
1)JAVA业务系统往master写入数据,但是从slave节点查询数据
2)每秒有2500写请求+2500读请求,可以放两台服务器,2500写请求落在master服务器,2500读请求落在slave服务器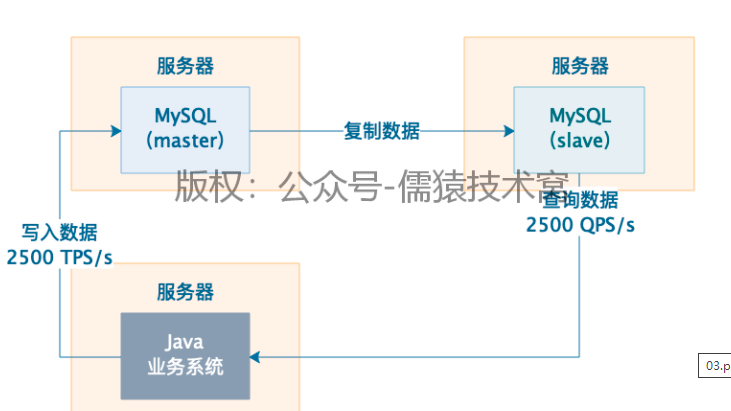
3)应对 读请求多于写请求,主从复制架构,支持一主多从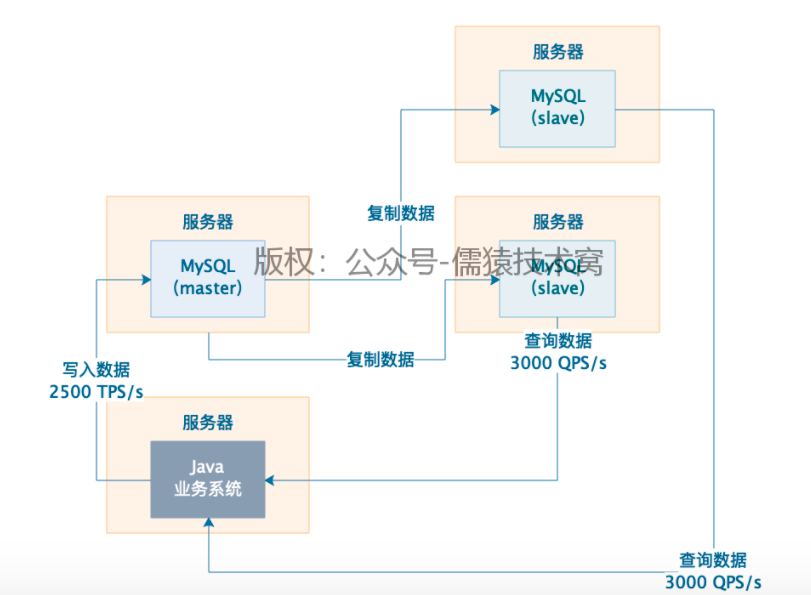
2、主从复制架构的基本工作原理
1)mysql增删改,会记录 binlog日志
2)slave库上有一个IO线程,IO线程会负责跟主库建立TCP连接,请求主库传输 binlog日志给自己
3)master库上 IO dump线程,负责通过这个TCP连接,把binlog日志传输到 从库IO线程
4)IO线程把读取到的binlog日志,写入到自己本库的relay日志文件中
5)从库上的另一SQL线程会读取relay日志,进行日志重做,把所有主库上执行的操作在从库上在做一遍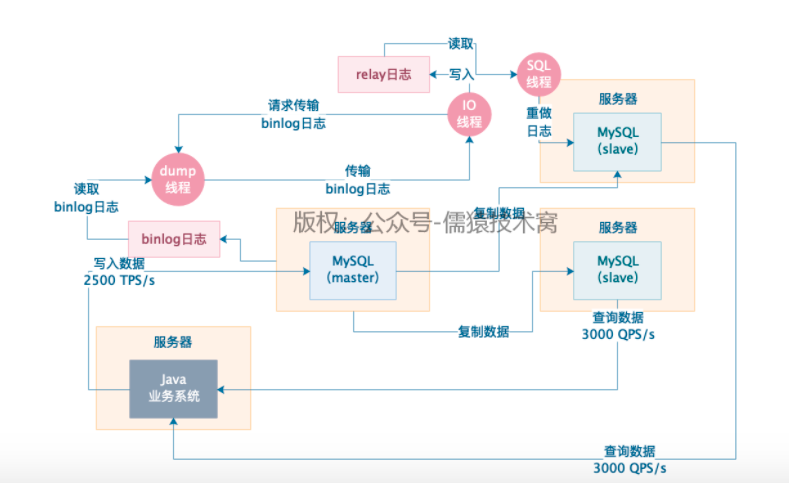
120 | 案例实战:千万级数据删除导致的慢查询优化实践(3)
1)永远不要在业务高峰期,去做删除大量数据的语句,因为可能导致一些正常的sql查询变慢,那些sql也许会不断扫描那些标记为删除的大量数据,扫描到一批,结果发现标记删除了,继续扫描下去,导致慢查询
2)对于大量数据的清理,尽量凌晨去执行
121 | 如何为MySQL搭建一套主从复制架构?(1)
1)首先确保主从库的server-id 是不同的
2)主库必须打开 binlog功能
3)在主库上创建一个用于主从复制的账号: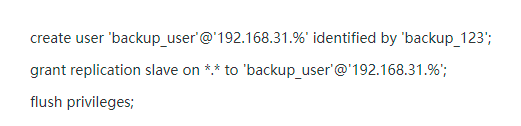
4)凌晨,系统维护状态,然后对主库和从库做一个数据备份和导入,可用mysqldump工具对主库数据做一个全量备份
5)scp命令把 backup.sql文件拷贝到从库服务器上
6)在从库上执行下面的命令去指定从主库复制
122 | 如何为MySQL搭建一套主从复制架构?(2)
1、半同步复制
主库写入数据,日志进入到binlog之后,binlog从主库复制到从库,这样主库突然崩了,数据页不会丢
2、半同步复制方式
1)AFTER_COMMIT : 日志进入到binlog,binlog从主库复制到从库,主库就提交自己本地的事务,等待从库返回给自己的一个成功的响应,主库事务提交成功响应给客户端
2)mysql5.7默认方式:主库把日志写入到binlog,复制给从库,开始等待从库的响应,从库成功,主库再提交事务,再把主库提交成功的响应给客户端
123 | 如何为MySQL搭建一套主从复制架构?(3)
1、GTID搭建方式
124 | 主从复制架构中的数据延迟问题,应该如何解决?
1、为什么会有延迟
主库是多线程并发写入的,主库写入数据很快,但是从库单个线程拉取数据很慢
2、延迟时间,监控工具:percona-toolkit工具集里的ptheartbeat
3、mysql5.7后支持并行复制
125 | 数据库高可用:基于主从复制实现故障转移(1)
1、MHA:数据库高可用架构管理工具
1)MHA分为两种节点:manager节点、node节点
2)manager节点单独部署一台机器,node节点部署再每台mysql机器上
3)manager节点通过探测集群里的 node节点,去判断node所在机器上的mysql是否正常允许,如果发现某个master故障,直接把他的一个slave升为master,其他slave都挂到新的master上去
126 | 数据库高可用:基于主从复制实现故障转移(2)
127 | 数据库高可用:基于主从复制实现故障转移(3)
128 | 案例实战:大型电商网站的上亿数据量的用户表如何进行水平拆分
129 | 案例实战:一线电商公司的订单系统是如何进行数据库设计的
130 | 案例实战:下一个难题,如果需要进行垮库的分页操作,应该怎么来做?
131 | 案例实战:当分库分表技术方案运行几年过后,再次进行扩容应该怎么做?

若有收获,就点个赞吧
0 人点赞
