- 14 | 当我们更新Buffer Pool中的数据时,flush链表有什么用
- 15 | 当Buffer Pool中的缓存页不够的时候,如何基于LRU算法淘汰部分缓存?
- 16 | 简单的LRU链表在Buffer Pool实际运行中,可能导致哪些问题
- 17 | MySQL是如何基于冷热数据分离的方案,来优化LRU算法的
- 18 | 基于冷热数据分离方案优化后的LRU链表,是如何解决之前的问题的
- 19 | MySQL是如何将LRU链表的使用性能优化到极致的
- 20 | 对于LRU链表中尾部的缓存页,是如何淘汰他们刷入磁盘的
- 21 | 生产经验:如何通过多个Buffer Pool来优化数据库的并发性能
- 22 | 生产经验:如何通过chunk来支持数据库运行期间的Buffer Pool动态调整?
- 23 | 生产经验:在生产环境中,如何基于机器配置来合理设置Buffer Pool
- 24| 我们写入数据库的一行数据,在磁盘上是怎么存储的?
- 25 | (变长字段的长度列表)对于VARCHAR这种变长字段,在磁盘上到底是如何存储的
- 26 | (null值列表)一行数据中的多个NULL字段值在磁盘上怎么存储
14 | 当我们更新Buffer Pool中的数据时,flush链表有什么用
1、buffer pool是否会有内存碎片?
2、脏数据页
进行增删改时,操作缓存页,缓存页的数据跟磁盘上的数据页数据不一致,生成脏页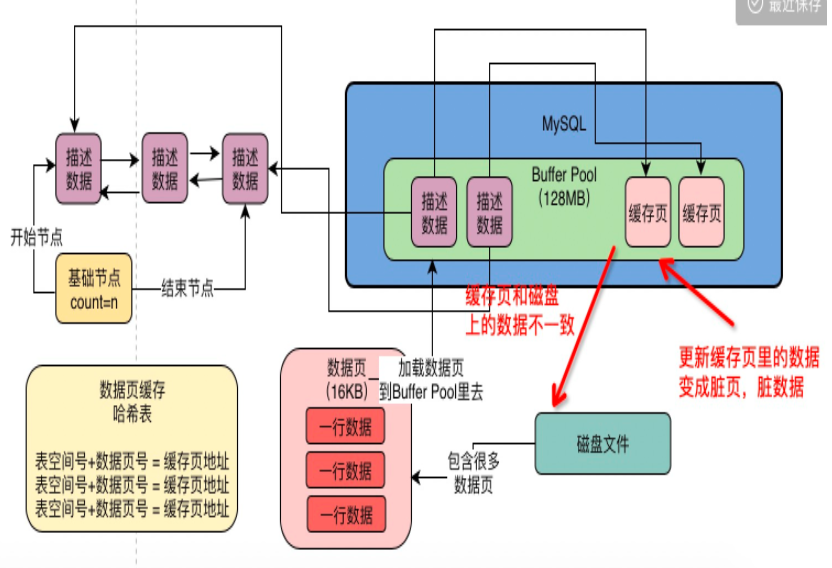
3、哪些缓存页是脏页
1)不可能所有的缓存页都刷回磁盘,比如查询的时候读到buffer pool里面去,但是根本没修改过,导致一直没往磁盘里写入。
问题1:如果我读取到 buffer pool里,根本没修改过,那跟磁盘上的数据页数据一致啊,会是脏数据吗
答:不是脏数据
问题2:如果我没修改过,就不往磁盘里回写入了吗
答:是的
2)flush链表
- 数据结构:双向链表
- 凡是被修改过的缓存页,都把描述数据的地址加入到flush链表中去
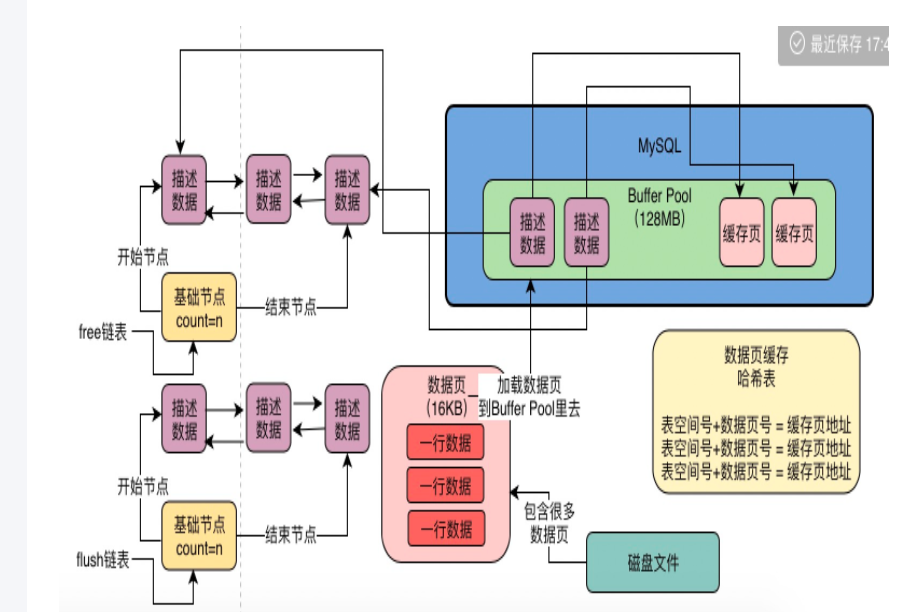
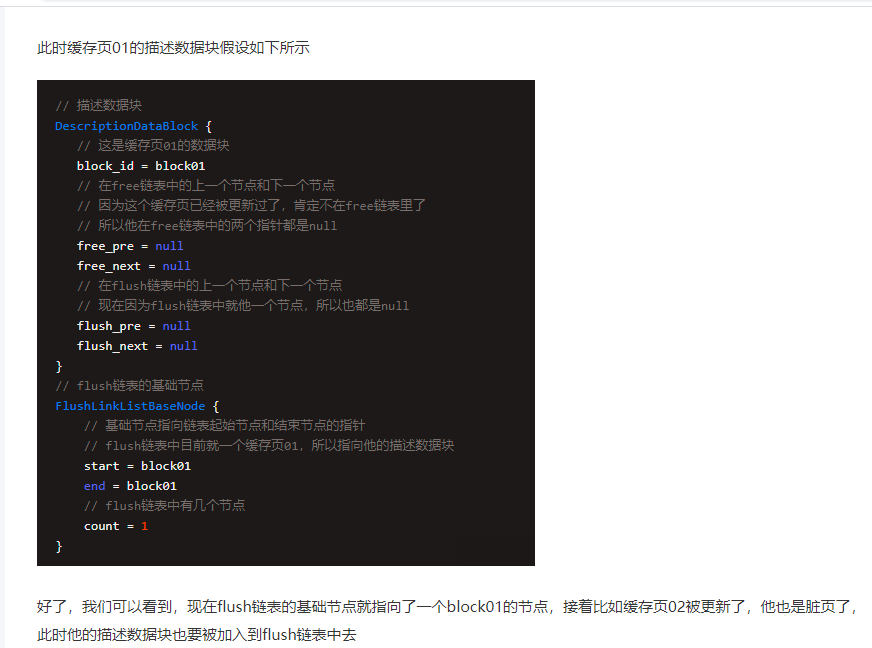
15 | 当Buffer Pool中的缓存页不够的时候,如何基于LRU算法淘汰部分缓存?
1、把一个数据页加载到空闲缓存中去,free链表中就减少一个空闲缓存
2、淘汰一些缓存数据,淘汰谁
淘汰缓存页:把一个缓存页里被修改过的数据,刷回到磁盘数据页里去,然后这个缓存页就可以清空了。
问题:应该把哪个被修改过数据的缓存页给刷回去?第3点解答
3、缓存命中率的引入
缓存页A:100次请求,有30次在查询和修改。缓存命中率高
缓存页B:100次请求,有1次在查询。缓存命中率低
如果要刷回磁盘,肯定选命中率低的
问题:如果算命中率?第4点解答
4、引入LRU链表来判断哪些缓存页是不常用的
LRU:Least Recently Used
最近被加载数据的缓存页,都会被放到LRU链表的头部
5、表空间和数据页关系
逻辑概念:表、列、行
物理概念:表空间、数据页
16 | 简单的LRU链表在Buffer Pool实际运行中,可能导致哪些问题
1、Mysql的预读机制
当你从磁盘上加载一个数据页的时候,可能会连带着把这个数据页的相邻数据页,也加载到缓存中去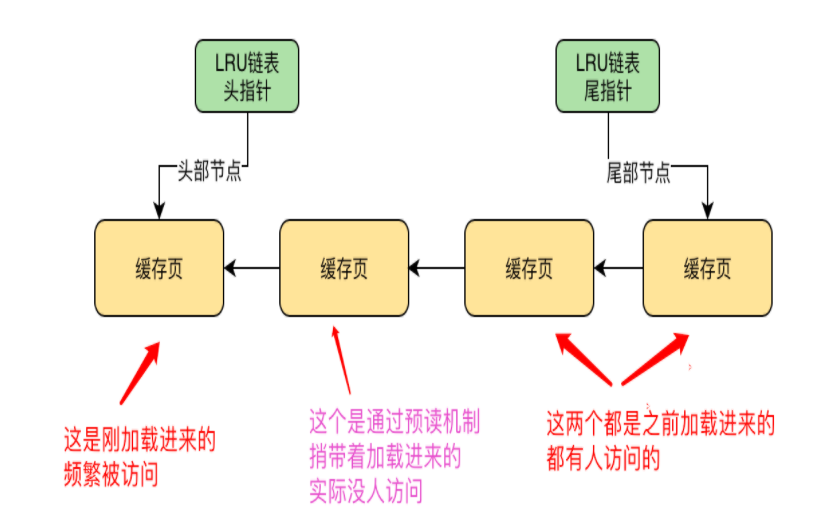
2、哪些情况会触发预读机制
1)参数:innodb_read_ahead_threshold,默认值56
顺序访问了一个区里的多个数据页,访问数量超过这个阈值,会触发机制,把相邻的数据页也加载到缓存中去
2)参数:innodb_random_read_ahead,默认OFF
buffer pool 里缓存了一个区里13个连续的数据页,且被频繁访问,会直接触发机制…
3、全表扫描
1)sql :select * from users;
2)执行上面的sql会导致把表里所有的数据页,全部从磁盘加载到buffer pool里去
那么LRU链表里是所有的数据页,表尾的数据页有可能是被频繁访问的,这样子可能会出现频繁访问的数据页被淘汰掉了。
4、总结
17 | MySQL是如何基于冷热数据分离的方案,来优化LRU算法的
1、mysql为什么设定预读机制
2、基于冷热分离的思想设计LRU链表
1)16中的所有问题都是因为所有的缓存页都混在一个LRU链表里导致的
2)真正的LRU链表,会被拆成两部分:一部分是热数据,一部分是冷数据
3)冷热数据比例:innodb_old_blocks_pct 参数控制的,默认37(冷数据占37%)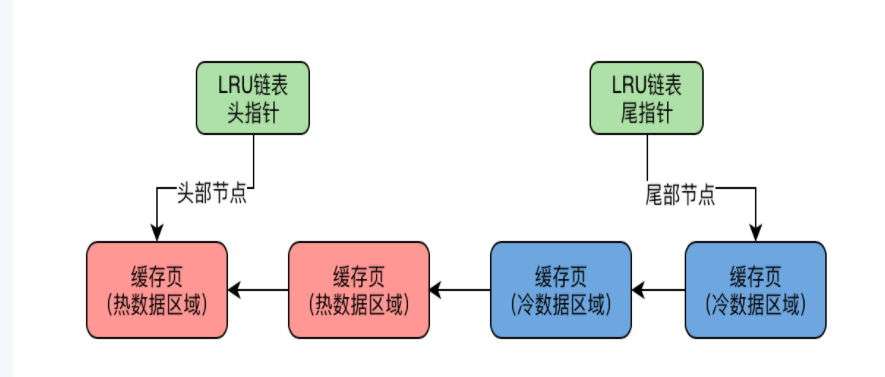
3、数据页第一次被加载到内存的时候,被放在LRU链表冷数据的链表头部
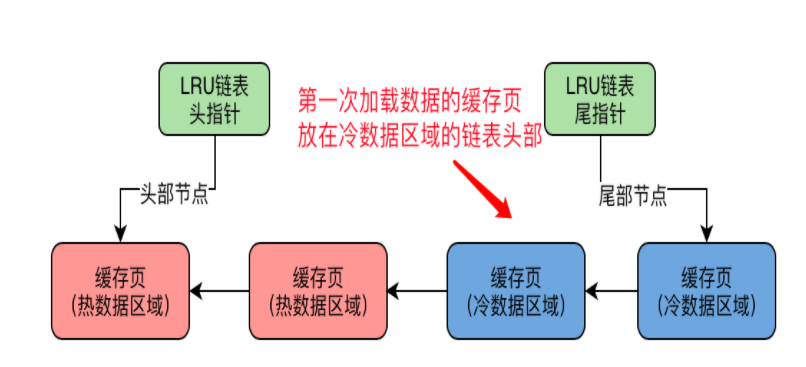
4、冷数据区的缓存页什么时候会被放到热数据区域
1)一个数据页被加载到缓存页之后,在1s后,你又去访问了这个缓存页,此时这个缓存页就被会挪动到热数据区域的链表头部
2)时间1s的设定:innodb_old_blocks_time 参数,默认值1000(毫秒)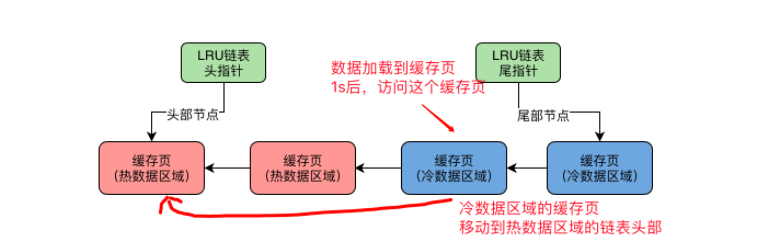
问题:那热数据区域的数据会移动到冷区里吗
自我猜测:是通过那个冷热比例?热的占到7成,如果再来往热的移动一个,热区的最后一个就变成冷的?
18 | 基于冷热数据分离方案优化后的LRU链表,是如何解决之前的问题的
1、预读和全表扫描加载进来的一大堆缓存页,放在LRU链表冷区域前面
2、缓存页不够,淘汰缓存页方案
直接淘汰冷区尾部的缓存页
19 | MySQL是如何将LRU链表的使用性能优化到极致的
1、java系统,redis里存放的应该是经常访问的热数据缓存
2、设计缓存机制时,需要考虑热数据的缓存预加载
3、LRU热数据区域,如何进行优化的
问题:在热数据区域,如果访问了一个缓存页,是否会立马移动到热区域的头部
答:只有在热数据区域的3/4部分的缓存页被访问了,才会被移动到链表头部
前1/4不会移动,如问题所问,会频繁移动,性能不好
20 | 对于LRU链表中尾部的缓存页,是如何淘汰他们刷入磁盘的
1、定时把LRU尾部的部分缓存页刷入磁盘
后台线程,运行一个定时任务,每隔一段时间就会把LRU链表的冷数据区域尾部缓存页,刷入磁盘里,
清空这几个缓存页,加入到free链表里去
2、把flush链表的缓存页定时刷入磁盘(被修改的数据迟早刷入磁盘)
21 | 生产经验:如何通过多个Buffer Pool来优化数据库的并发性能
1、buffer pool 在访问时需要加锁
mysql同时收到了多个请求,多个线程处理多个请求,每个线程负责一个。
多线程并发访问一个buffer pool ,加锁,让一个线程先完成一系列操作,然后释放锁,接着下一个线程接着再操作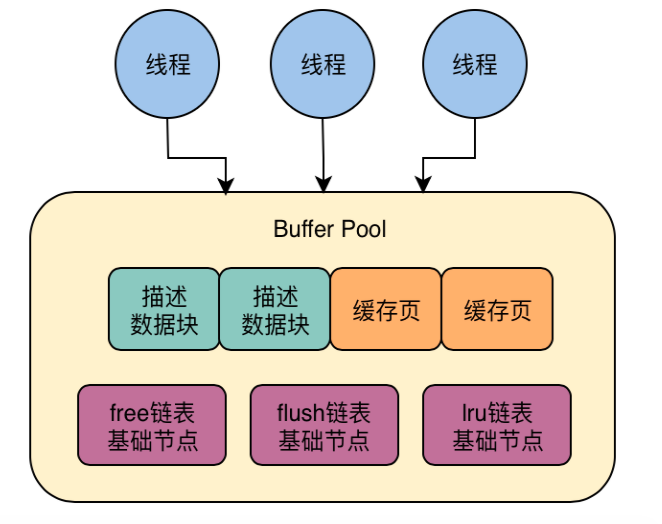
2、多线程并发访问,数据库的性能如何
一个buffer pool 即使多个线程加锁串行着排队执行,性能也ok
3、如何提高性能:多个buffer pool 优化并发能力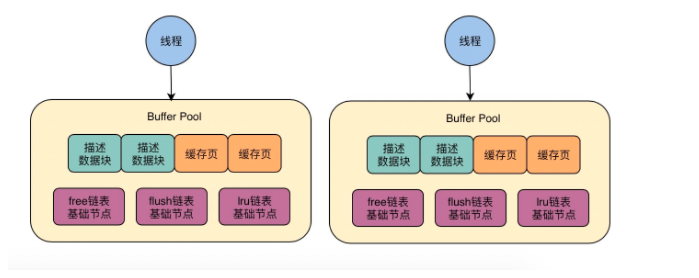
22 | 生产经验:如何通过chunk来支持数据库运行期间的Buffer Pool动态调整?
1、buffer pool 能在运行期间动态调整大小吗
以上的理论不能。但是后面可以用chunk来支持动态
比如,buffer pool本来是8G,调整为16G,此时需要向操作系统申请一块16G的连续内存,然后把buffer pool中的缓存页、描述数据、各种链表 ,都拷贝到新的内存中去,极为耗时
2、如何基于chunk机制把buffer pool给拆小
1)buffer pool 是由很多chunk组成的
2)chunk大小是innodb_buffer_pool_chunk_size参数控制的,默认128MB
3)chunk里面就是一系列的描述数据块和缓存页,每个buffer pool 里的多个chunk共享一套free\flush\lru链表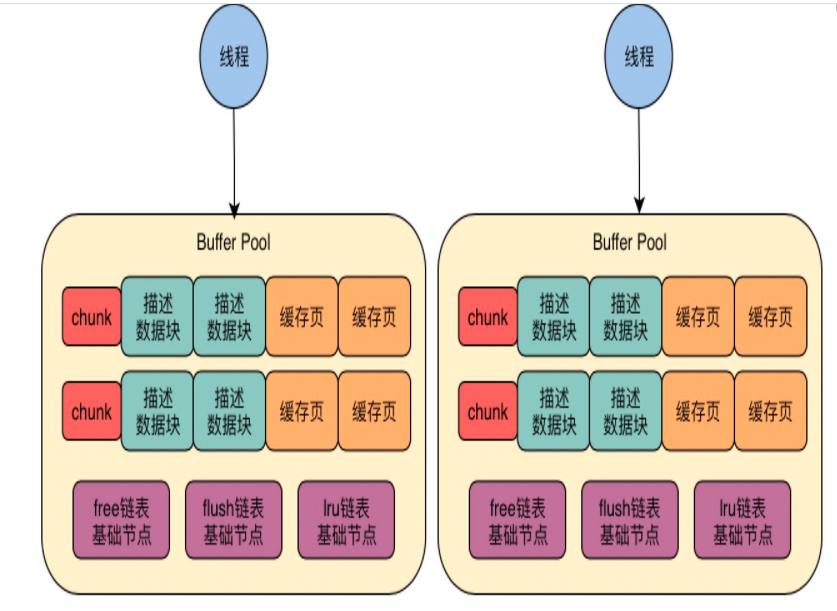
3、基于chunk机制,动态调整buffer pool大小
buffer pool 8G,动态加到16GB,申请一系列128MB的chunk就可以。每个chunk是连续的128内存。然后把这些chunk分配给buffer pool
23 | 生产经验:在生产环境中,如何基于机器配置来合理设置Buffer Pool
1、生产环境应该给buffer pool 多少内存
2、设置多少个buffer pool,以及chunk大小
buffer pool总大小=(chunk大小*buffer pool数量)的倍数
24| 我们写入数据库的一行数据,在磁盘上是怎么存储的?
1、行格式
可以对这个表指定行存储的格式是什么样的,比如COMPACT格式、
例如:CREATE TABLE table_name(columns) ROW_FORMAT= COMPACT
25 | (变长字段的长度列表)对于VARCHAR这种变长字段,在磁盘上到底是如何存储的
1、一行数据在磁盘上存储时,都包含哪些数据
变长字段的长度列表,null值列表,数据头,column01的值,column02的值,column0N的值
2、变长字段在磁盘中怎么存储的
假设
| COL_A | VARCHAR(10) | COL_B | CHAR(1) | COL_C | CHAR(1) |
|---|---|---|
| hello | a | a |
| hi | b | b |
把上述两行数据写入一个磁盘文件,两行数据是挨在一起的,有可能是:
hello a a hi b b
3、存储在磁盘文件里的变长字段,为什么难以读取
hello a a hi b b 哪些是第一行数据,难以判断
4、引入变长字段的长度列表,解决一行数据的读取问题
在存储 hello a a 这行数据的时候,带上附加信息:
比如 hello 长度是5,16进制:0x05。
所以这行数据在磁盘文件里存储的时候,格式是 :
0x05 null值列表 数据头 hello a a 0x02 null值列表 数据头 hi b b
5、多个变长字段,如何存放他们的长度
逆序存放
0x03 0x02 0x05 null值列表 数据头 hello hi hao a a
26 | (null值列表)一行数据中的多个NULL字段值在磁盘上怎么存储
假设 列B 列C 列 D允许为空
| COL_A | VARCHAR(10) NOT NULL | COL_B | CHAR(1) NULL | COL_C | CHAR(1) NULL | COL_D | VARCHAR(2) NULL |
|---|---|---|---|
| hello | a | cc | |
| hi | b | b |
1)每个定义可以为空的字段,都有一个二进制bit位的值,
2)bit = 1,为NULL
bit = 0,不是NULL
3)例子中的bit位应该是 :100
4)bit实际存放在null值列表时,是逆序存放 : 001
整体一行数据:
0x02 0x05 001 数据头 hello NULL a cc

若有收获,就点个赞吧
0 人点赞
