对于操作系统来讲,它面对的 CPU 的数量是有限的,干活儿都是它们,但是进程数目远远超过 CPU 的数目,因而就需要进行进程的调度,有效地分配 CPU 的时间,既要保证进程的最快响应,也要保证进程之间的公平。这也是一个非常复杂的、需要平衡的事情。
调度策略与调度类
在 Linux 里面,进程大概可以分成两种。
一种称为实时进程,也就是需要尽快执行返回结果的那种。这就好比我们是一家公司,接到的客户项目需求就会有很多种。有些客户的项目需求比较急,比如一定要在一两个月内完成的这种,客户会加急加钱,那这种客户的优先级就会比较高。
另一种是普通进程,大部分的进程其实都是这种。这就好比,大部分客户的项目都是普通的需求,可以按照正常流程完成,优先级就没实时进程这么高,但是人家肯定也有确定的交付日期。
显然,对于这两种进程,我们的调度策略肯定是不同的。
在 task_struct 中,有一个成员变量,我们叫调度策略。
unsigned int policy;//包括如下定义#define SCHED_NORMAL 0#define SCHED_FIFO 1#define SCHED_RR 2#define SCHED_BATCH 3#define SCHED_IDLE 5#define SCHED_DEADLINE 6
配合调度策略的,还有我们刚才说的优先级,也在 task_struct 中。
int prio, static_prio, normal_prio;
unsigned int rt_priority;
优先级其实就是一个数值,对于实时进程,优先级的范围是 0~99;对于普通进程,优先级的范围是 100~139。数值越小,优先级越高。从这里可以看出,所有的实时进程都比普通进程优先级要高。
实时调度策略
SCHED_FIFO、SCHED_RR、SCHED_DEADLINE 是实时进程的调度策略。
SCHED_FIFO:高优先级的进程可以抢占低优先级的进程,而相同优先级的进程,我们遵循先来先得。
SCHED_RR 轮流调度算法:采用时间片,相同优先级的任务当用完时间片会被放到队列尾部,以保证公平性,而高优先级的任务也是可以抢占低优先级的任务。
SCHED_DEADLINE:按照任务的 deadline 进行调度的。当产生一个调度点的时候,DL 调度器总是选择其 deadline 距离当前时间点最近的那个任务,并调度它执行。
普通调度策略
SCHED_NORMAL、SCHED_BATCH、SCHED_IDLE 是普通调度策略。
SCHED_NORMAL:普通的进程。
SCHED_BATCH 是后台进程,几乎不需要和前端进行交互。
SCHED_IDLE 是空闲的时候才跑的进程。
调度执行逻辑
上面无论是 policy 还是 priority,都设置了一个变量,变量仅仅表示了应该这样这样干,但事情总要有人去干,谁呢?在 task_struct 里面,还有这样的成员变量:
const struct sched_class *sched_class;
调度策略的执行逻辑,就封装在这里面,它是真正干活的那个。sched_class 有几种实现:
▶ stop_sched_class 优先级最高的任务会使用这种策略,会中断所有其他线程,且不会被其他任务打断;
▶ dl_sched_class 就对应上面的 deadline 调度策略;
▶ rt_sched_class 就对应 RR 算法或者 FIFO 算法的调度策略,具体调度策略由进程的 task_struct->policy 指定;
▶ fair_sched_class 就是普通进程的调度策略;idle_sched_class 就是空闲进程的调度策略。
完全公平调度算法
在 Linux 里面,实现了一个基于 CFS 的调度算法。CFS 全称 Completely Fair Scheduling,叫完全公平调度。听起来很“公平”。
首先,你需要记录下进程的运行时间。CPU 会提供一个时钟,过一段时间就触发一个时钟中断。就像咱们的表滴答一下,这个我们叫 Tick。
CFS 会为每一个进程安排一个虚拟运行时间 vruntime。如果一个进程在运行,随着时间的增长,也就是一个个 tick 的到来,进程的 vruntime 将不断增大。没有得到执行的进程 vruntime 不变。
显然,那些 vruntime 少的,原来受到了不公平的对待,需要给它补上,所以会优先运行这样的进程。
关于优先级,就好比 N 个口袋,优先级高的袋子大,优先级低的袋子小。这样球就不能按照个数分配了,要按照比例来,大口袋的放了一半和小口袋放了一半,里面的球数目虽然差很多,也认为是公平的。
/*
* Update the current task's runtime statistics.
*/
static void update_curr(struct cfs_rq *cfs_rq)
{
struct sched_entity *curr = cfs_rq->curr;
u64 now = rq_clock_task(rq_of(cfs_rq));
u64 delta_exec;
......
delta_exec = now - curr->exec_start;
......
curr->exec_start = now;
......
curr->sum_exec_runtime += delta_exec;
......
curr->vruntime += calc_delta_fair(delta_exec, curr);
update_min_vruntime(cfs_rq);
......
}
/*
* delta /= w
*/
static inline u64 calc_delta_fair(u64 delta, struct sched_entity *se)
{
if (unlikely(se->load.weight != NICE_0_LOAD))
/* delta_exec * weight / lw.weight */
delta = __calc_delta(delta, NICE_0_LOAD, &se->load);
return delta;
}
在这里得到当前的时间,以及这次的时间片开始的时间,两者相减就是这次运行的时间 delta_exec ,但是得到的这个时间其实是实际运行的时间,需要做一定的转化才作为虚拟运行时间 vruntime。转化方法如下:
虚拟运行时间 vruntime += 实际运行时间 delta_exec * NICE_0_LOAD/ 权重
也就是说相同的实际时间下,对于虚拟时间,权重大高的算少了,低权重的算多了,但是当选取下一个运行进程的时候,还是按照最小的 vruntime 来的,这样高权重的获得的实际运行时间自然就多了。
调度队列与调度实体
CFS 需要一个数据结构来对 vruntime 进行排序,找出最小的那个。这个能够排序的数据结构不但需要查询的时候,能够快速找到最小的,更新的时候也需要能够快速地调整排序,要知道 vruntime 可是经常在变的,变了再插入这个数据结构,就需要重新排序。
能够平衡查询和更新速度的是树,在这里使用的是红黑树。红黑树的的节点是应该包括 vruntime 的,称为调度实体。
在 task_struct 中有这样的成员变量:实时调度实体 sched_rt_entity,Deadline 调度实体 sched_dl_entity,以及完全公平算法调度实体 sched_entity。
看来不光 CFS 调度策略需要有这样一个数据结构进行排序,其他的调度策略也同样有自己的数据结构进行排序,因为任何一个策略做调度的时候,都是要区分谁先运行谁后运行。
而进程根据自己是实时的,还是普通的类型,通过这个成员变量,将自己挂在某一个数据结构里面,和其他的进程排序,等待被调度。如果这个进程是个普通进程,则通过 sched_entity,将自己挂在这棵红黑树上。
对于普通进程的调度实体定义如下,这里面包含了 vruntime 和权重 load_weight,以及对于运行时间的统计。
struct sched_entity {
struct load_weight load;
struct rb_node run_node;
struct list_head group_node;
unsigned int on_rq;
u64 exec_start;
u64 sum_exec_runtime;
u64 vruntime;
u64 prev_sum_exec_runtime;
u64 nr_migrations;
struct sched_statistics statistics;
......
};

所有可运行的进程通过不断地插入操作最终都存储在以时间为顺序的红黑树中,vruntime 最小的在树的左侧,vruntime 最多的在树的右侧。 CFS 调度策略会选择红黑树最左边的叶子节点作为下一个将获得 CPU 的任务。
每个 CPU 都有自己的 struct rq 结构,其用于描述在此 CPU 上所运行的所有进程,其包括一个实时进程队列 rt_rq 和一个 CFS 运行队列 cfs_rq,在调度时,调度器首先会先去实时进程队列找是否有实时进程需要运行,如果没有才会去 CFS 运行队列找是否有进程需要运行。
struct rq {
/* runqueue lock: */
raw_spinlock_t lock;
unsigned int nr_running;
unsigned long cpu_load[CPU_LOAD_IDX_MAX];
......
struct load_weight load;
unsigned long nr_load_updates;
u64 nr_switches;
struct cfs_rq cfs;
struct rt_rq rt;
struct dl_rq dl;
......
struct task_struct *curr, *idle, *stop;
......
};
对于普通进程公平队列 cfs_rq,定义如下:
/* CFS-related fields in a runqueue */
struct cfs_rq {
struct load_weight load;
unsigned int nr_running, h_nr_running;
u64 exec_clock;
u64 min_vruntime;
#ifndef CONFIG_64BIT
u64 min_vruntime_copy;
#endif
struct rb_root tasks_timeline;
struct rb_node *rb_leftmost;
struct sched_entity *curr, *next, *last, *skip;
......
};
这里面 rb_root 指向的就是红黑树的根节点,这个红黑树在 CPU 看起来就是一个队列,不断地取下一个应该运行的进程。rb_leftmost 指向的是最左面的节点。

调度类如何工作
struct sched_class {
const struct sched_class *next;
void (*enqueue_task) (struct rq *rq, struct task_struct *p, int flags);
void (*dequeue_task) (struct rq *rq, struct task_struct *p, int flags);
void (*yield_task) (struct rq *rq);
bool (*yield_to_task) (struct rq *rq, struct task_struct *p, bool preempt);
void (*check_preempt_curr) (struct rq *rq, struct task_struct *p, int flags);
struct task_struct * (*pick_next_task) (struct rq *rq,
struct task_struct *prev,
struct rq_flags *rf);
void (*put_prev_task) (struct rq *rq, struct task_struct *p);
void (*set_curr_task) (struct rq *rq);
void (*task_tick) (struct rq *rq, struct task_struct *p, int queued);
void (*task_fork) (struct task_struct *p);
void (*task_dead) (struct task_struct *p);
void (*switched_from) (struct rq *this_rq, struct task_struct *task);
void (*switched_to) (struct rq *this_rq, struct task_struct *task);
void (*prio_changed) (struct rq *this_rq, struct task_struct *task, int oldprio);
unsigned int (*get_rr_interval) (struct rq *rq,
struct task_struct *task);
void (*update_curr) (struct rq *rq);
}
第一个成员变量,是一个指针,指向下一个调度类。
下面我们仔细看一下 sched_class 定义的与调度有关的函数。
▶ enqueue_task 向就绪队列中添加一个进程,当某个进程进入可运行状态时,调用这个函数;
▶ dequeue_task 将一个进程从就绪队列中删除;
▶ pick_next_task 选择接下来要运行的进程;
▶ put_prev_task 用另一个进程代替当前运行的进程(把上一个进程放回树中);
▶ set_curr_task 用于修改调度策略;task_tick 每次周期性时钟到的时候,这个函数被调用,可能触发调度。
在这里面,我们重点看 fair_sched_class 对于 pick_next_task 的实现 pick_next_task_fair,获取下一个进程。调用路径如下:pick_next_task_fair->pick_next_entity->__pick_first_entity。
struct sched_entity *__pick_first_entity(struct cfs_rq *cfs_rq)
{
struct rb_node *left = rb_first_cached(&cfs_rq->tasks_timeline);
if (!left)
return NULL;
return rb_entry(left, struct sched_entity, run_node);
从这个函数的实现可以看出,就是从红黑树里面取最左面的节点。
已知调度类分为以下几种:
extern const struct sched_class stop_sched_class;
extern const struct sched_class dl_sched_class;
extern const struct sched_class rt_sched_class;
extern const struct sched_class fair_sched_class;
extern const struct sched_class idle_sched_class;
它们其实是放在一个链表上的。这里我们以调度最常见的操作,**取下一个任务**为例,来解析一下。可以看到,这里面有一个 for_each_class 循环,沿着上面的顺序,依次调用每个调度类的方法。这样也就实现了先处理实时进程再处理普通功能的功能。
/*
* Pick up the highest-prio task:
*/
static inline struct task_struct *
pick_next_task(struct rq *rq, struct task_struct *prev, struct rq_flags *rf)
{
const struct sched_class *class;
struct task_struct *p;
......
for_each_class(class) {
p = class->pick_next_task(rq, prev, rf);
if (p) {
if (unlikely(p == RETRY_TASK))
goto again;
return p;
}
}
}
这就说明,调度的时候是从优先级最高的调度类到优先级低的调度类,依次执行。而对于每种调度类,有自己的实现,例如,CFS 就有 fair_sched_class。
const struct sched_class fair_sched_class = {
.next = &idle_sched_class,
.enqueue_task = enqueue_task_fair,
.dequeue_task = dequeue_task_fair,
.yield_task = yield_task_fair,
.yield_to_task = yield_to_task_fair,
.check_preempt_curr = check_preempt_wakeup,
.pick_next_task = pick_next_task_fair,
.put_prev_task = put_prev_task_fair,
.set_curr_task = set_curr_task_fair,
.task_tick = task_tick_fair,
.task_fork = task_fork_fair,
.prio_changed = prio_changed_fair,
.switched_from = switched_from_fair,
.switched_to = switched_to_fair,
.get_rr_interval = get_rr_interval_fair,
.update_curr = update_curr_fair,
};
对于同样的 pick_next_task 选取下一个要运行的任务这个动作,不同的调度类有自己的实现。fair_sched_class 的实现是 pick_next_task_fair,rt_sched_class 的实现是 pick_next_task_rt。
我们会发现这两个函数是操作不同的队列,pick_next_task_rt 操作的是 rt_rq,pick_next_task_fair 操作的是 cfs_rq。
static struct task_struct *
pick_next_task_rt(struct rq *rq, struct task_struct *prev, struct rq_flags *rf)
{
struct task_struct *p;
struct rt_rq *rt_rq = &rq->rt;
......
}
static struct task_struct *
pick_next_task_fair(struct rq *rq, struct task_struct *prev, struct rq_flags *rf)
{
struct cfs_rq *cfs_rq = &rq->cfs;
struct sched_entity *se;
struct task_struct *p;
......
}
这样整个运行的场景就串起来了,在每个 CPU 上都有一个队列 rq,这个队列里面包含多个子队列,例如 rt_rq 和 cfs_rq,不同的队列有不同的实现方式,cfs_rq 就是用红黑树实现的。
当某个 CPU 需要找下一个任务执行的时候,会按照优先级依次调用调度类,不同的调度类操作不同的队列。当然 rt_sched_class 先被调用,它会在 rt_rq 上找下一个任务,只有找不到的时候,才轮到 fair_sched_class 被调用,它会在 cfs_rq 上找下一个任务。这样保证了实时任务的优先级永远大于普通任务。
总结
一个 CPU 上有一个队列,CFS 的队列是一棵红黑树,树的每一个节点都是一个 sched_entity,每个 sched_entity 都属于一个 task_struct,task_struct 里面有指针指向这个进程属于哪个调度类。在调度的时候,依次调用调度类的函数,从 CPU 的队列中取出下一个进程。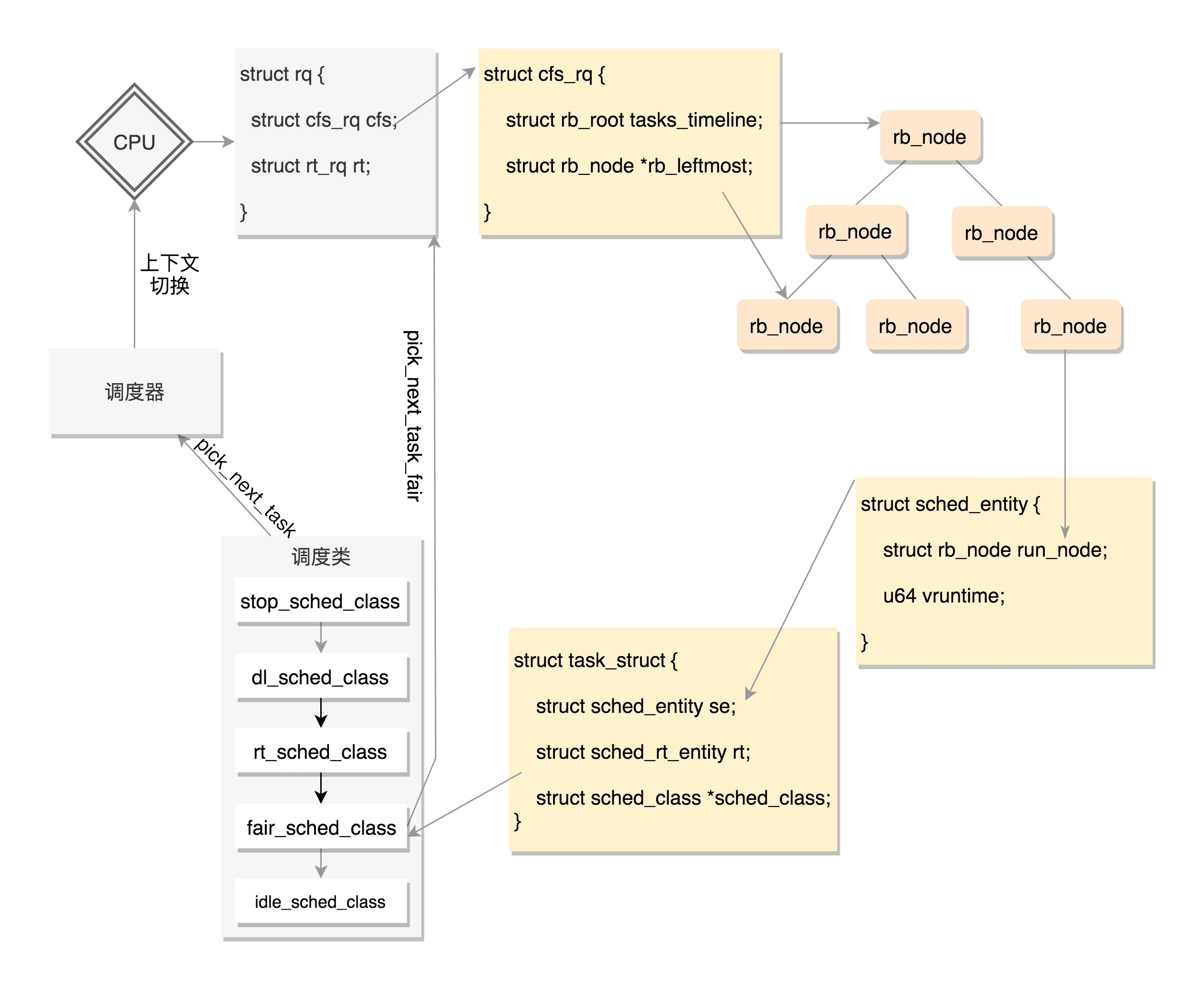
- 调度策略与调度类
- 进程包括两类: 实时进程(优先级高); 普通进程
- 两种进程调度策略不同: task_struct->policy 指明采用哪种调度策略(有6种策略)
- 优先级配合调度策略, 实时进程(0-99); 普通进程(100-139)
- 实时调度策略, 高优先级可抢占低优先级进程
- FIFO: 相同优先级进程先来先得
- RR: 轮流调度策略, 采用时间片轮流调度相同优先级进程
- Deadline: 在调度时, 选择 deadline 最近的进程
- 普通调度策略
- normal: 普通进程
- batch: 后台进程, 可以降低优先级
- idle: 空闲时才运行
- 调度类: task_struct 中 * sched_class 指向封装了调度策略执行逻辑的类(有5种)
- stop: 优先级最高. 将中断其他所有进程, 且不能被打断
- dl: 实现 deadline 调度策略
- rt: RR 或 FIFO, 具体策略由 task_struct->policy 指定
- fair: 普通进程调度
- idle: 空闲进程调度
- 普通进程的 fair 完全公平调度算法 CFS(Linux 实现)
- 记录进程运行时间( vruntime 虚拟运行时间)
- 优先调度 vruntime 小的进程
- 按照比例累计 vruntime, 使之考虑进优先级关系
- 调度队列和调度实体
- CFS 中需要对 vruntime 排序找最小, 不断查询更新, 因此利用红黑树实现调度队列
- task_struct 中有 实时, deadline 和 cfs 三个调度实体, cfs 调度实体即红黑树节点
- 每个 CPU 都有 rq 结构体, 里面有 dl_rq, rt_rq 和 cfs_rq 三个调度队列以及其他信息; 队列描述该 CPU 所运行的所有进程
- 先在 rt_rq 中找进程运行, 若没有再到 cfs_rq 中找; cfs_rq 中 rb_root 指向红黑树根节点, rb_leftmost指向最左节点
- 调度类如何工作
- 调度类中有一个成员指向下一个调度类(按优先级顺序串起来)
- 找下一个运行任务时, 按 stop-dl-rt-fair-idle 依次调用调度类, 不同调度类操作不同调度队列

若有收获,就点个赞吧
0 人点赞
