数组
概述
数组:相同类型元素的集合,存储在一块连续的内存中,go 在编译期间确定是否能在堆中初始化。
初始化
两种方式
两种方式:显式指定数组大小,使用 [...]T 声明数组,编译期间通过源码推导数组大小。后一种声明方式在编译期间会转换成前一种,即编译器对数组大小进行推导。
arr1 := [3]int{1,2,3}arr2 := [...]int{1,2,3}
编译器推导方式
上限推导
使用第一种方式的话,编译器在类型检查的时候就会提取出变量类型。随后创建包含数组大小的结构体。使用第二种方式会调用函数,通过遍历元素的方式计算数组中元素的数量。
语句转换
对于字面量组成的数组,根据数组元素数量的不同,编译器会在负责初始化字面量的函数中进行优化。
● 元素个数少于或等于四个,直接将数组中的元素放到栈上
● 调用函数将原有的初始化语句[3]int{1,2,3}拆分成一个声明语句和几个赋值语句var a [3]int ; arr[0] = 1 ;
● 元素多于四个,在静态存储区初始化然后复制到栈上,这些转换后的代码才会继续进入中间代码生成和机器码生成两个阶段,最后生成可执行的二进制文件。
访问与赋值
无论是在栈上还是在静态存储区,数组在内存中都是一连串连续的内存空间,所以通过数组开头的指针,元素的数量**,以及元素类型所占的空间大小(一次取出多少字节)来表示数组**。
避免访问越界:go 语言中,如果索引为整数或常量,编译期间的静态类型检查可以判断是否越界;如果是变量,则通过运行期间插入的函数保障数组不会越界。
赋值过程会先确定数组的地址,依靠索引得到元素的地址,最后使用 Store 指令将数据存入地址中,无论是数组的寻址还是赋值,都是在编译阶段完成的,没有运行时的参与。
总结
数组的访问和赋值需要同时依赖编译器和运行时,它的大多数操作在编译期间会转换成直接读取内存。在中间代码生成期间,编译器还会插入运行时方法runtime.panicIndex防止内存越界。
切片
概述
切片的声明与数组类似,但是由于长度是动态的,所以声明时只需要指明元素类型。
[]int
[]interface{}
编译期间能且只能确定切片类型,运行时才会确定切片内容。
数据结构
编译期间只能确定切片的类型,而运行时切片的数据结构可以由一下结构体表示
type SliceHeader struct {
Data uintptr //指向底层数组的指针
Len int //当前切片的大小
Cap int //当前切片的容量,即 Data 数组的大小
}
Data 是一块连续的内存空间,用于存储切片中的全部元素,数组中的元素只是逻辑上的概念,底层存储都是连续的,所以可以将切片理解为一片连续的内存空间加上长度与容量的标识。
切片引入了一个抽象层,提供了对数组中部分元素的引用,而作为数组的引用,我们可以在运行时修改它的长度和范围。当底层数组的长度不足时会发生扩容,切片指向的数组可能会发生变化,而对于上层来说,这些操作都被隐藏起来。
初始化
Go 语言包含三种初始化的方式
arr[0:3] //通过下标获取数组或者切片的一部分
slice := []int{1,2,3} //使用字面量初始化新的切片
slice := make([]int,10} //使用关键字 make 创建切片
使用下标
是所有方法中最接近汇编,最底层的一种,调用函数,通过提供元素类型,数组指针,切片大小和容量四个参数创建新的切片。
要注意使用下标初始化切片不会复制原数组或切片中的数据,只会创建一个指向原数组的结构体,所以修改新的切片数据也会修改原来的数据。还要知道 append() 函数对原数组的影响
func main() {
a := [3]int{1, 2, 3}
b := a[0:3]
b = append(b, 9) //b 在数组 a 上新建,使用 append 后修改元素
b[0] = 7
fmt.Println(a, b)
c := b[0:4] //c 在切片 b 上新建,使用 append 后修改元素
c = append(c, 98)
c[0] = 98
fmt.Println(a, b, c)
}
//[1 2 3] [7 2 3 9] 数组 a 中的数据没有被更改
//[1 2 3] [98 2 3 9] [98 2 3 9 98] 切片 b 中的数据被修改
func main() {
a := [3]int{1, 2, 3}
b := a[0:3] //b 是在数组上使用下标创建
b[2] = 8
fmt.Println("b[2] = 8 , a = ", a)
c := b[0:2] //c 是在切片上使用下标创建
c[0] = 9
fmt.Println("a = ", a)
fmt.Println("b = ", b)
fmt.Println("c = ", c)
}
//b[2] = 8 , a = [1 2 8] 数组 a 中的数据被修改
//a = [9 2 8]
//b = [9 2 8]
//c = [9 2] 数据都被修改
字面量
使用字面量[]int{1,2,3}创建切片时,调用函数在编译期间将它转化为以下形式
var vstat [3]int //根据元素数量推断底层数组大小并创建一个数组
vstat[0] = 1
... //将这些字面量元素存储到初始化的数组中
var vauto *[3]int = new([3]int) //创建指针
*vauto = vstat //指向数组
slice := vauto[:] //通过[:]获取一个底层使用的切片
[:]即为下表创建切片的方法。
func main() {
a := [3]int{1, 2, 3}
var b *[3]int = new([3]int)
*b = a
fmt.Println(b)
slice := b[:]
fmt.Println(slice)
}
//&[1 2 3]
//[1 2 3]
关键字 make
字面量创建大部分时间花在编译期间,而使用关键字则更多在运行时,会调用函数检查长度是否传入,传入的长度是否小于等于容量。
存储位置由切片的大小确定,如果切片发生逃逸或者非常大,就在堆上初始化切片,如果切片未发生逃逸并且非常小,那么 make([]int,3,4) 就会被转换成 var arr [4]int ; n := arr[:3]。可见三种方式最后都要调用下标方式来初始化切片。
追加与扩容
追加
append 方法会根据返回值是否会覆盖原变量,选择进入两种流程之一,一种是追加之后,调用 makeSlice函数返回一个新的切片结构,之后对他的操作不影响原切片,一种是在根据原来的切片的地址,向其中加入数据元素。
扩容
为切片分配新的内存空间需要对原切片中的内容进行复制与删除操作,可见当切片过大时,复制与删除也会造成较大的资源消耗。
扩容规则:
● 期望容量大于当前容量的二倍,使用期望容量
● 切片容量小于 1024 ,将容量翻倍
● 切片容量大于 1024 ,每次增加 25% 的容量,直到新容量大于期望容量
复制
根据复制的调用是否在运行时,分为两种情况,但是两种方式都会通过 runtime.memmove将整块内存复制到目标区域。相较于依次复制元素,调用运行时方法会提高性能,但仍会消耗很大资源。
小结
切片的很多功能是由运行时实现的,无论是初始化切片还是对切片进行追加扩容,都要运行时的支持,大规模切片扩容或者复制时,可能会发生很大规模的内存复制,应尽量避免此类操作。
哈希表
概述
哈希表(字典,映射)表示键值对之间的关系。
设计原理
提供键值之间的映射,尽量使数据分布均匀,接近 O(1) 的读写性能,设计哈希表要注意哈希函数和冲突解决方法。
哈希函数
理想状况下,哈希函数将不同的键映射到不同的索引上,要求哈希函数的输出范围大于函数的输入范围,但是由于键的数量往往远大于映射的范围,所以实际使用时理想效果不可能实现。
哈希函数要尽量保障结果均匀,然后用工程手段解决冲突,否则会导致冲突增加,性能下降。均匀分布的话,增删查改的时间复杂度大概在 O(1),而不均匀的话可能会达到 O(n),性能严重下降。
解决冲突
一般使用开放寻址发,拉链法(1953年就已经实现)。
数据结构
Go 运行时会有多个数据结构组合表示数组,其中 runtime.hmap是最核心的结构体。
type hmap struct {
count int
flags int
B uint8
noverflow uint16
hash0 uint32
buckets unsafe.Pointer
oldbuckets unsafe.Pointer
nevacuate uintptr
extra *mapextra
}
type mapextra struct {
overflow *[]*bmap
oldoverflow *[]*bmap
nextOverflow *bmap
}
type bmap struct {
topbits [8]uint8
keys [8]keytype
elems [8]elemtype
pad uintptr
overflow uintptr
}
● count 当前表中元素的数量
● B表示当前哈希表持有的 buckets的数量,len(buckets) == 2^B
● hash0是哈希表的种子,为哈希函数的结果引入随机性,在哈希表创建时确定,在调用哈希函数是作为参数传入。
● oldbucket是哈希表在扩容时用于保存之前 bucket 的字段,其大小是当前 buckets 的一半。
● noverflow是 bucket溢出桶的数量,在函数 mapassign作为判断语句的一个条件,来决定是否对哈希表进行扩容。
● overflow 是 bmap结构中的溢出桶

初始化
字面量
hash := map[string]int {
"1":1,
"2":2,
}
编译器会根据键值对个数对其进行不同的处理,但使用字面量初始化过程最后都会使用 Go 语言中的关键字 make 来创建新的哈希表,并通过最原始的 []语法向哈希表中追加元素(即 hash[k] = v)
运行时
读写操作
访问
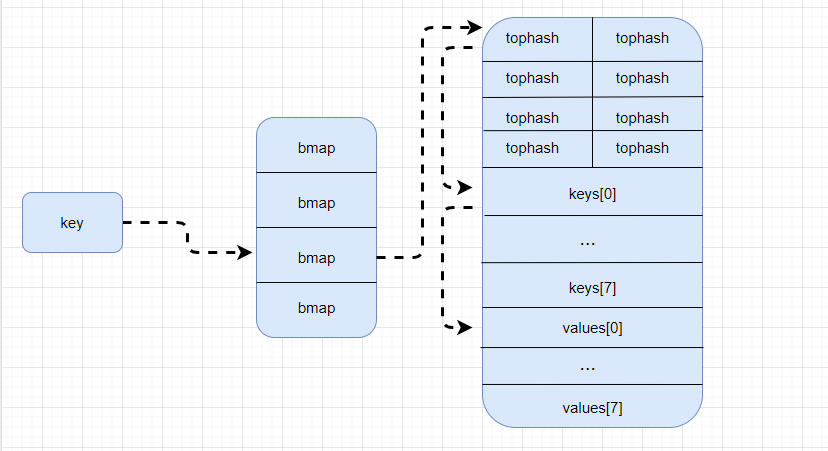
在访问过程中,哈希表会依次遍历正常的桶和溢出桶中的数据,它会先比较哈希的高八位和桶中存储的 tophash 后比较传入的值与桶中的值以加速数据读写。
每一个桶都是一整块内存空间,当发现桶中的 tophash与传入的 tophash匹配以后,会通过指针和偏移量获取哈希表存储的键 key[0]与 key 比较,如果两者相同,就会获取目标值得指针 value[7]并返回。
查找时,先确定桶,在根据 tophash 去找 k,v ,如果当前桶中没有匹配的 tophash,就去溢出桶中去找,由哈希遍历溢出桶的图可以看到,溢出桶的个数可能不止一个,此外这里的遍历指的是遍历的桶中的 tophash,不是遍历所有的桶。
写入
首先是根据拿到的键确定对应的哈希和桶,然后通过遍历比较桶中的 tophash 和键的哈希,如果找到相同结果,返回目标键的位置。
如果当前桶已满,哈希表会调用 runtime.hmap.newoverflow 创建新的桶或者使用,rumtime.hmap 预先在 noverflow 中创建好的桶来保存数据,新创建的桶不仅会被追加到哦已有桶的末尾,还会增加 noverflow 的计数器。
扩容
当哈希表中使用太多溢出桶,或者装载因子大于 6.5 时,会发生扩容。哈希表的扩容不是原子过程,所以调用运行时函数扩容时还要判断当前是否是扩容状态(!h.growing()),避免二次扩容造成混乱。
根据触发条件,扩容分为两种方式,如果溢出桶太多,则进行等量扩容,持续向表中插入数据并将他们全部删除时,如果哈希表中的数据没有超过阈值,那么溢出桶就会不断积累,造成缓慢的内存泄露,此时通过复用已有的哈希表扩容机制解决该问题。
一旦表中出现了过多的溢出桶,它们就会创建新桶以保存数据,垃圾收集器清除老的溢出桶并释放内存。调用函数 runtime.hasGrow 进行扩容,扩容后,原有的桶设置到 oldbuckets上,并将新的空桶设置到 buckets上,溢出桶使用了相应的逻辑更新,这其中并没有对数据进行复制和转移。
扩容方式分为两种,等量扩容:旧桶与新桶之间相互对应,当哈希表容量翻倍时,每个旧桶中的元素都会分配到新创建的两个桶中。从最终桶的数量上来看两者相同,但是第一种会继续使用旧桶,而第二种,将旧桶中的元素全部分配到了新桶中。
扩容条件:
1. map 中数据总个数/桶个数>6.5,引发翻倍扩容。`mapassign` 中的 `overLoadFactor`函数。
2. 使用了太多的溢出桶时(溢出桶使用的太多会导致map处理速度降低)。`mapassign` 中的`tooManyOverflowBuckets` 函数。
B<=15,已使用的溢出桶个数>=2的B次方时,引发等量扩容。<br /> B>15,已使用的溢出桶个数>=2的15次方时,引发等量扩容
第二种情况下,使用 sameSizeGrow 机制在出现较多溢出桶时整理哈希表的内存减少空间占用。
扩容期间当对哈希表中的值进行访问时,如果 oldbuckets不为空,说明数据还未被分流,新桶尚未创建,或者创建之后数据为空,此时由旧桶提供数据。如果分流期间删除元素,就会分流出桶中的元素,分流结束后找到桶中的元素完场删除操作。
字符串
概述
往往被看成是一个整体,但其实是一块连续的内存空间,也可以将其理解为由字符组成的数组。Go 中的字符串是只读的字节数组。
只读意味着字符串会被分配到只读的内存空间,而 Go 不支持直接修改 string类型的变量的内存空间,我们可以在 string和 []byte 类型之间反复转换实现修改:
● 将这段内存复制到堆上或栈上
● 将变量的类型转换为 []byte 之后修改字节数据
● 将修改后的字节数组转换回 string
数据结构
type StringHeader struct {
Data uintptr
Len int
}
结构比较简单,注意字符串在内存中是只读的不能通过下标的方式直接改变其中的某个字符,可以通过与 []byte之间的类型转换实现,但是转换过程中使用的是内存的复制,所以要注意性能消耗。
同样,字符串的拼接也是开辟一块新的内存,将原数据复制到其中,当数据量过大时,也会很大的影响性能消耗。

若有收获,就点个赞吧
0 人点赞
