逻辑架构
客户端
连接器
server层 查询缓存 分析器 优化器 执行器
存储引擎 自带的MyISAM 常用InnoDB
日志
redo Log 是innodb引擎带的物理日志,存放在磁盘中,具备crash-safe,redolog会在固定大小的磁盘循环写。
mysql自带的binlog日志不具备 crash-safe能力,binlog日志会追加。
两阶段提交
执行sql操作的时候,执行之后,先写入redolog,此时redolog处于prepare状态,然后系统写binlog,之后提价事务。提交事务之后,redolog处于commit状态。如果出错,就不会提交,此时回滚,这样redolog和binlog记录会保持一致性,成功都成功,失败都失败。
事务
提到事务,你肯定会想到 ACID(Atomicity、Consistency、Isolation、Durability,即原子性、一致性、隔离性、持久性),今天我们就来说说其中 I,也就是“隔离性”。
事务的隔离级别
- 读未提交 提交前改动就能被其他事物看见
- 读提交 提交之后改动才会被其他事务看见
- 可重复读 一个事务执行过程中看到的数据和启动时看到的一致,未提交的变更对其他事务不可见
- 串行化 会加 读写锁,所冲突时,只有当前一个事务执行完成,其他事务才能继续执行。
事务隔离实现——多版本并发控制 MVCC
更新的时候会同时记录一条回滚段,不同时间段开始的事务对应不同的视图数据库索引
常见的索引模型有hash表,有序数组和搜索树
主键索引
其他索引和联合索引
其他索引生成的B+数节点存放该索引值和主键的值,联合索引存放着的是联合索引的值和主键的值
回表
从非主键索引搜索到之后,需要搜索主键索引树得到对应行的数据,这个过程成为回表
覆盖索引、最左前缀原则和索引下推
- 查询语句中查询主键索引,但是条件是其他索引,因为主键索引的B+树中已经存在其他索引,所以这个时候并不会去其他索引的树中搜索,而是直接在主键树中搜索,称为主键索引覆盖其他索引
- 当语句包含索引左边的一部分字符时,也会直接从该索引处搜索,称为最左前缀原则
- 联合索引当根据第一个索引条件搜索后,并不会立即回表,而是根据下一个索引条件继续搜索,搜索完毕后回表搜索,称为索引下推
Innodb使用的索引模型是B+树
全局锁和表锁
全局锁在做数据库备份的时候使用,通过命令Flush tables with read lock (FTWRL) 。 但是因为此时整个库处于只读状态,会造成业务暂时不可用,并且如果备份从库,也会造成不能及时从主库同步信息。
更好的方式是使用一致性视图,启动可重复读隔离级别的事务。但是要求引擎支持。
表锁有读锁和写锁,读锁不互斥,可以多个线程同时读,但不能写。写锁互斥,同一时间只能有一个线程写,并且期间其他线程不能读取该表。5.5版本之后引入MDL锁,MDL读锁不互斥,同一时间可以多个线程对表进行crud操作,但是需要更改表结构时,会加上写锁,如果读锁未被释放,写锁会阻塞等待,且之后的读锁也会被阻塞。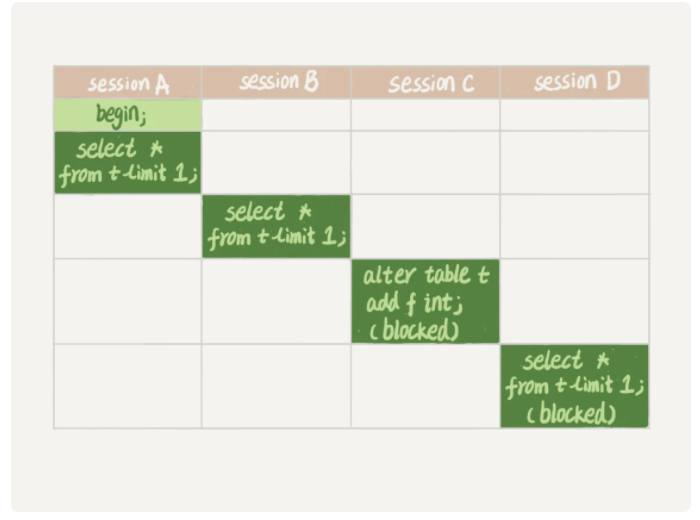
行锁
死锁检测处理
- 设置超时时间,等待一定时间还失败就回滚是事务,但是设置时间过长和过短都不合适
- 启动事务时检测死锁,但是这种方式会占用大量cpu资源
常用结:懂得mysql代码的人员修改底层,让相同行的事务进入引擎前排队执行,或者让一行逻辑改为多行。
事务
视图
普通查询或者创建的虚拟表
- innodb实现mvcc时用的一致性读视图,以可重复读隔离级别为例,事务启动时,会创建当前数据的视图。
innodb每一个事务都有一个唯一的id,且严格递增。每次更新,数据行都有多个版本,版本号对应事务的id,且这些数据并不是真实存在的,而是通过undo log计算出来的版本。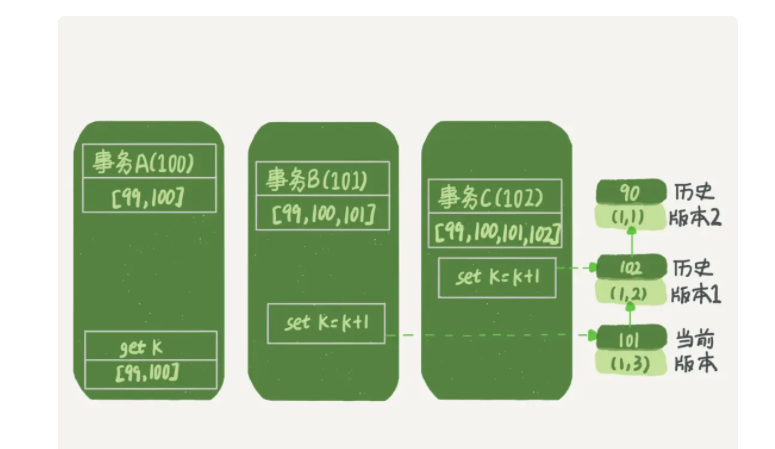
一致性读
一致性读就是事务id只能读取当前版本id值之前的版本。
当前读
update操作都是先读后写,读的数据必须是当前数据值,称为当前读,如果事务c更新没有提交,事务B更新先读当前值时会被锁住,等事务C释放锁才可以继续执行。
唯一索引和普通索引
前提
change buffer 和merge
- change buffer 是插入时,如果内存不存在对应的数据页,则先保存到buffer中,之后对应的数据页进入缓存在写入数据页,这个过程称为merge,merge可以主动触发,也会定时触发。
insert操作 唯一索引需要更新需要查询是否存在,即读取数据页,然后插入,因为遍历所有数据页,说以唯一索引不适用change buffer
普通索引,插入到change buffer中。
对于写多读少的业务来说,可以使用普通索引利用change buffer提高效率
对于要求数据最新的业务查询比较频繁,及时用change buffer也会因为查询而执行merge,并不会提高效率,反而会增加change buffer的压力。
给字符串加索引
为什么有时候mysql会变慢
当内存里有脏页的时候,mysql会将脏页更新到磁盘,如果脏页临近的页也是脏页,那么会有连坐反应,将脏页的临近脏页页更新到磁盘,之后我们称为干净页,干净页可以直接使用。
mysql删除表文件大小不变
因为删除数据后 页还保留,并被mysql设置为可复用状态,如果有新的数据,mysql会使用这些可以服用的数据页存储。
count(*)
order by
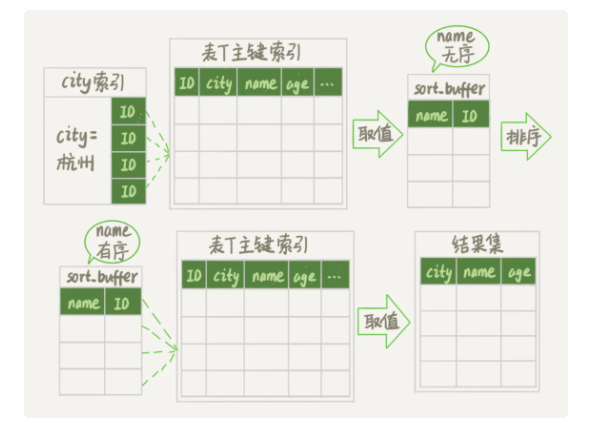
全字段排序和rowid排序
全字段排序就是将查询的字段都存起来,经过排序之后返回给客户端。
首先会将 查询的字段 放入称为 sort_buffer的内存中,如果内存的大小足够大,排序在内存中进行,如果不够大,会生成多个临时文件,分别排序后合并为有序的结果,之后返回结果。
如果查询的字段过多,会占用大量内存导致排序效率降低,这时就需要转变算法,使用rowid排序。 rowid排序,只将排序字段和主键id存入内存,排序之后在根据主键id回表获取其他查询的字段,并返回给客户端。

若有收获,就点个赞吧
0 人点赞
