乐观锁和悲观锁
- 乐观锁:
- 总是认为不会产生并发问题,每次拿数据都认为其他线程不会修改数据,因此不会上锁, 但是在更新时会判断其他线程在这之前有没有对数据进行修改,一般会使用版本号机制或CAS操作实现。
- version方式 :
- 一般是在数据表中加上一个数据版本号version字段,表示数据被修改的次数,当数据被修改时,version值会加1。当线程A要更新数据值时,在读取数据的同时也会读取version值,在提交更新时,若刚才读取到的version值为当前数据库中的version值相等时才更新,否则重试更新操作,直到更新成功。
- CAS操作方式 :
- compare and swap 或者 compare and set,涉及到三个操作数,数据所在的内存值,预期值,新值。当需要更新时,判断当前内存值与之前取到的值是否相等,若相等,则用新值更新,若失败则重试,一般情况下是一个自旋操作,即不断的重试。
- version方式 :
- 总是认为不会产生并发问题,每次拿数据都认为其他线程不会修改数据,因此不会上锁, 但是在更新时会判断其他线程在这之前有没有对数据进行修改,一般会使用版本号机制或CAS操作实现。
- 悲观锁:物理级别的锁,就是数据库提供的锁,或者Java级别提供支持的锁
- 总是假设最坏的情况,每次取数据时都认为其他线程会修改,所以都会加锁(读锁、写锁、行锁等),当其他线程想要访问数据时,都需要阻塞挂起。可以依靠数据库实现,如行锁、读锁和写锁等,都是在操作之前加锁,在Java中,synchronized的思想也是悲观锁。
- 死锁:何为死锁,就是多个线程同时被阻塞,它们中的一个或者全部都在等待某个资源被释放。
ReentrantLock 重入锁
- 重入锁:
- 线程在获得锁之后,再次获取该锁不需要阻塞, 直接增加重试次数就行了 , synchronized 和 ReentrantLock 都是可重入锁。
- 重入锁的设计目的:
- 避免线程的死锁
- AQS
- 是一个同步工具也是 Lock 用来实现线程同步的核心组件
- 为什么AQS叫抽象队列同步器
- 一、他是抽象的
- 二、内部有一个队列(双向列表)
- 三、利用state进行加锁和释放锁的控制(1有人持有锁,0释放锁)
- lock原理
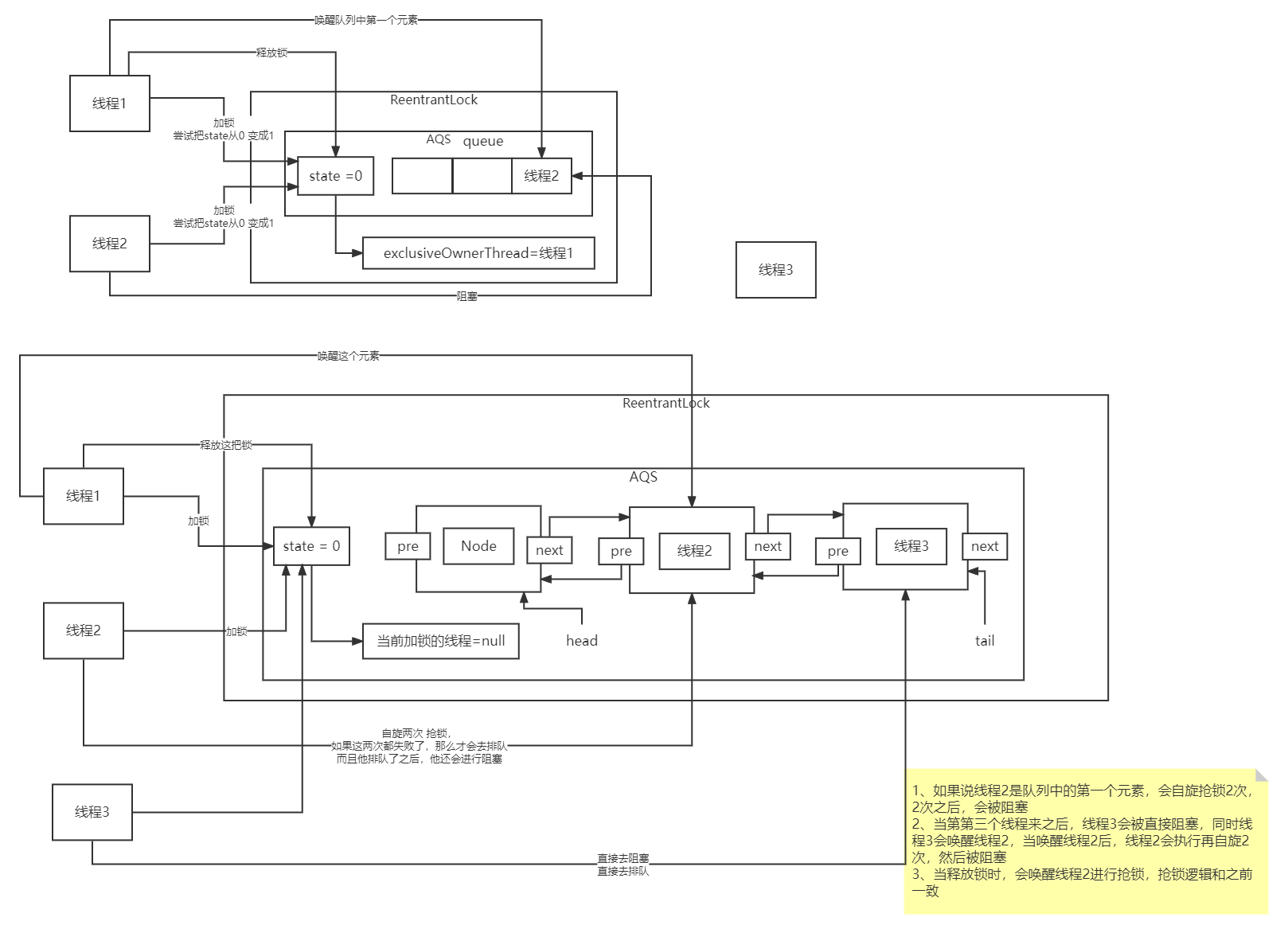
- 理解:
- 公平锁的时候当多个线程操作数据,会先判断这个数据上这把锁有没有人持有,没有就一起抢,假如线程一抢到了这把锁,其他线程就会进入AQS中的阻塞队列中按先后顺序进行排队并睡眠,当线程一执行完,就会唤醒队列中的第一个线程去抢这个锁。
- 非公平锁的时候呢,当线程1获取到锁了,线程2再进来的时候,他会直接尝试先抢一次,再去获得state,判断这把锁有没有被人持有,没有,他再尝试CAS一次,如果当前这把锁被人持有,会先判断持有人是不是自己,是自己,进行可重入,把stste递增,如果都没成功,他会去获取队列中的前置节点,如果发现自己就是第一个,他会构建一个双向链表,构建一个空的Node(只有第一次),然后再进行两次自旋。发现都没有抢到锁,就会阻塞。
- 假设现在线程3过来,公平锁的话,线程3不会自旋,直接排队,非公平锁的话,他也会自旋一次再获取state,判断有没有人持有这把锁,没有就再抢一次,没抢到再排队,有人持有直接排队
- 假设线程1释放了锁,他会把state进行递减,state==0,表示这把锁已经释放了,他会把持有锁的标识改为null,然后再去唤醒队列中的第一个元素,和非公平锁的其他线程进行抢锁,如果第一个元素是线程2,他被唤醒后又会自旋两次,还是失败,再进入阻塞队列中。
公平锁和非公平锁
- 非公平锁NofairSync: 不管当前队列上是否存在其他线程等待,新线程都有机会抢占锁 ,成功就获取到锁,失败就去AQS队列中排队
```java
// 直接调用 acquire(1)
final void lock() {
//进来先尝试抢一下锁
if (compareAndSetState(0, 1))
else acquire(1);setExclusiveOwnerThread(Thread.currentThread());
}
public final void acquire(int arg) {
//通过tryAcquire(arg)尝试的获取锁//若是没有获取到锁,通过该方法acquireQueued(addWaiter(Node.EXCLUSIVE), arg)就将当前的线程加入到存储等待线程的队列中if (!tryAcquire(arg) &&acquireQueued(addWaiter(Node.EXCLUSIVE), arg))selfInterrupt();
}
- 非公平锁NofairSync: 不管当前队列上是否存在其他线程等待,新线程都有机会抢占锁 ,成功就获取到锁,失败就去AQS队列中排队
```java
// 直接调用 acquire(1)
final void lock() {
//进来先尝试抢一下锁
if (compareAndSetState(0, 1))
final boolean nonfairTryAcquire(int acquires) { final Thread current = Thread.currentThread(); int c = getState(); if (c == 0) { //不会判断线程队列中是否有排在前面的线程等待着锁,直接再次去尝试cas 尝试加锁,有可能成功,也有可能失败 if (compareAndSetState(0, acquires)) { setExclusiveOwnerThread(current); return true; } } //判断对象头中的线程是否是自己 else if (current == getExclusiveOwnerThread()) { int nextc = c + acquires; if (nextc < 0) // overflow throw new Error(“Maximum lock count exceeded”); setState(nextc); return true; } return false; }
final boolean acquireQueued(final Node node, int arg) { boolean failed = true; try { boolean interrupted = false; // 死循环处理 for (;;) { // 获取前置线程节点 final Node p = node.predecessor(); // 再尝试的去获取锁 if (p == head && tryAcquire(arg)) { setHead(node); p.next = null; failed = false; // 直接return interrupted return interrupted; } // 在获取锁失败后,应该将线程暂停 if (shouldParkAfterFailedAcquire(p, node) &&parkAndCheckInterrupt()) interrupted = true; } } finally { if (failed) cancelAcquire(node); } }
- **公平锁FailSync:** 所有线程严格按照 FIFO (先进先出)来获取锁```java// 直接调用 acquire(1)final void lock() {acquire(1);}public final void acquire(int arg) {//通过tryAcquire(arg)尝试的获取锁//若是没有获取到锁,通过该方法acquireQueued(addWaiter(Node.EXCLUSIVE), arg)就将当前的线程加入到存储等待线程的队列中if (!tryAcquire(arg) &&acquireQueued(addWaiter(Node.EXCLUSIVE), arg))selfInterrupt();}protected final boolean tryAcquire(int acquires) {// 获取当前线程final Thread current = Thread.currentThread();// 获取当前线程拥有着的状态int c = getState();// 若为0,说明当前线程拥有者已经释放锁if (c == 0) {// 判断线程队列中是否有排在前面的线程等待着锁,有,获取锁失败,没有,设置线程的状态为1。if (!hasQueuedPredecessors() &&compareAndSetState(0, acquires)) {// 设置线程的拥有着为当前线程setExclusiveOwnerThread(current);return true;}// 若是当前的线程的锁的拥有者就是当前线程,可重入锁} else if (current == getExclusiveOwnerThread()) {// 执行状态值+1int nextc = c + acquires;if (nextc < 0)throw new Error("Maximum lock count exceeded");// 设置status的值为nextcsetState(nextc);return true;}return false;}final boolean acquireQueued(final Node node, int arg) {boolean failed = true;try {boolean interrupted = false;// 死循环处理for (;;) {// 获取前置线程节点final Node p = node.predecessor();// 这里又尝试的去获取锁if (p == head && tryAcquire(arg)) {setHead(node);p.next = null;failed = false;// 直接return interruptedreturn interrupted;}// 在获取锁失败后,应该将线程暂停if (shouldParkAfterFailedAcquire(p, node) &&parkAndCheckInterrupt())interrupted = true;}} finally {if (failed)cancelAcquire(node);}}
synchronized锁
synchronized锁本质是一个对象锁 ,他锁住的是一个对象
Java的对象头布局
必须是要求对象的大小必须是8的整数倍
1.首先是有一个object header
2.填充数据 :当对象大小不足8的倍数的时候,他会把当前对象填充成8的倍数,假如他现在本身就是8的byte的倍数,此时填充数据就不用了
3.成员变量 :就是咱们成员变量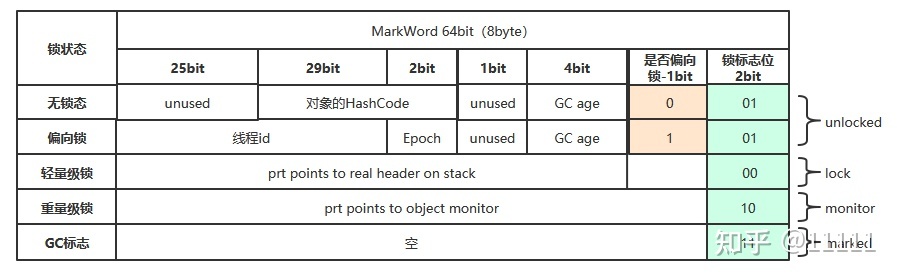
- 无锁
- 当一个对象被创建之后,还没有线程进入,这个时候对象处于无锁状态 (101 无锁可偏向)
- 如果在没有加锁的情况下去计算hashcode值,(001,无锁不可偏向),此时再去加锁,就不会成为偏向锁,直接变成轻量级锁
- 偏向锁
- 引入偏向锁的目的
- 大多时候并不存在竞争关系,常常是一个线程多次访问同一个锁,降低再次获取锁的代价
- 引入偏向锁的目的
轻量级锁
synchronized锁本质是一个对象锁 ,他锁住的是一个对象,并且具有可重入的性质
- 为什么要进行锁升级
- 因为jdk1.6时Java加锁的时候,就是实现一个线程互斥,但他自己又实现不了,就会调用mutex函数把数据从用户态转为内核态,然后保留数据在用户态时的现场,执行完还得放回去,本身用户态转内核态就很耗费性能,然后保留现场,还原现场等也很耗费性能,所以哪怕只有一个线程,加上synchronized锁后运行也会变慢。
- 锁升级条件和过程
- 在JVM中,每个对象都有一个对象头,synchronized用的锁是存在对象头中的 Mark Word中, 他定义了synchronized锁的4种状态: 无锁状态、偏向锁状态、自旋锁(轻量级锁状态)、重量级锁状态。锁可以升级,但不能降级,但是偏向锁可以被重置成无锁状态
- 一个对象被创建之后,还没有线程进入,这个时候对象处于无锁状态 ,当线程1访问代码块并获取锁对象时,会在java对象头中记录偏向的锁的线程id,因为偏向锁不会主动释放锁,因此以后线程1再次获取锁的时候,需要比较当前线程的ID和Java对象头中的线程ID是否一致,如果一致,还是线程1获取锁对象,则无需使用CAS来加锁、解锁;如果不一致,那么需要查看Java对象头中记录的线程1是否存活,没有存活,锁对象被重置为无锁状态,其它线程(线程2)可以竞争将其设置为偏向锁;如果存活,判断是否还需要继续持有这个锁对象,如果线程1 不再使用该锁对象,那么将锁对象状态设为无锁状态,重新偏向新的线程。
- 需要持有,那么暂停当前线程1,撤销偏向锁,升级为轻量级锁
- 升级过程中首先会方法压栈,栈帧中会创建两个和锁有关的空间displace hrd和owner
- 将 Mark Word中的信息拷贝到displace hrd中
- 然后用栈帧指针owner去指向对象头
- 对象头中轻量级指针会指向当前创建出来的这个栈帧
- 锁就会把状态改为00
- 使两条线程交替执行,其实还有两种方法也可以升级成轻量级锁,一种是在无锁不可偏向时加锁,会直接膨胀为轻量级锁,或者关闭延迟偏向锁打开,也会直接变成轻量级锁。轻量级锁考虑的是竞争锁对象的线程不多,而且线程持有锁的时间也不长的情景,因为阻塞线程需要cpu从用户态转到内核态。代价比较大,如果刚刚阻塞不久这个锁就被释放了,那这个代价就有点得不偿失了,因此这个时候干脆就不要阻塞这个线程,让它自旋等待这个锁释放 。
- 但是如果自旋的时间太长也不行,因为自旋是要消耗CPU的,因此自旋的次数是有限制的,比如10次或者100次,如果自旋次数到了线程1还没有释放锁,或者线程1还在执行,线程2还在自旋等待,这时又有一个线程3过来竞争这个锁对象,那么这个时候轻量级锁就会膨胀为重量级锁。把除了拥有锁的线程以外的其他线程都阻塞,防止CPU空转,线程会进入阻塞队列(EntryList)
- 而Java如果发现要创建一把重量级锁,就会为我们创建一个C++的ObjectMonitor,他会让对象头中monitor指向我们这个ObjectMonitor对象,这个时候如果你进入到锁内部,ObjectMonitor会发起汇编指令monitorenter,当你出syn代码块的时候,他会发出monitorexit指令,或者执行过程中出现了异常,他还是会执行monitorexit这个指令。
- 当多个线程同时访问一个被synchronized修饰的方法或代码块时,这些线程会先被放进entryList队列中,此时线程处于阻塞状态,他们会利用CAS来进行抢锁,当一个线程抢锁成功,ObjectMonitor对象会把他内部的owner指针指向当前线程,count加1,如果此时抢到锁的线程刚好是持有锁的线程,count会再加1(重入锁)
- 释放锁的时候,会把count—,直到count==0,ObjectMonitor对象把owner变为null,如果对线程调用wait()方法,线程就会进入waitSet队列中,直到有线程调用notifyall方法的时候,该线程重新进入entryList队列,重新竞争锁。
- 如果是同步方法,那么他执行的 指令为 acc_synchronized ,但是他是隐式调用
synchronized 和 volatile 的区别是什么?
volatile本质是在告诉jvm当前变量在寄存器(工作内存)中的值是不确定的,需要从主存中读取; synchronized则是锁定当前变量,只有当前线程可以访问该变量,其他线程被阻塞住。
volatile仅能使用在变量级别;synchronized则可以使用在变量、方法、和类级别的。
volatile仅能实现变量的修改可见性,不能保证原子性;而synchronized则可以保证变量的修改可见性和原子性。
volatile不会造成线程的阻塞;synchronized可能会造成线程的阻塞。
volatile标记的变量不会被编译器优化;synchronized标记的变量可以被编译器优化。synchronized 和 Lock 有什么区别?
首先synchronized是java内置关键字,在jvm层面,Lock是个java类;
synchronized无法判断是否获取锁的状态,Lock可以判断是否获取到锁;
synchronized会自动释放锁(a 线程执行完同步代码会释放锁;b 线程执行过程中发生异常会释放锁),Lock需在finally中手工释放锁(unlock()方法释放锁),否则容易造成线程死锁;
用synchronized关键字的两个线程1和线程2,如果当前线程1获得锁,线程2线程等待。如果线程1阻塞,线程2则会一直等待下去,而Lock锁就不一定会等待下去,如果尝试获取不到锁,线程可以不用一直等待就结束了;
synchronized的锁可重入、不可中断、非公平,而Lock锁可重入、可判断、可公平(两者皆可);
Lock锁适合大量同步的代码的同步问题,synchronized锁适合代码少量的同步问题。
短信防刷
我们在发短信的时候,需要去把当前发送短信的时间 放到code的后面,在正式发送前,先判空,是空直接发验证码,不是空取出code后边的时间和当前时间比,大于60就让发,小于提示个错。
接口幂等性
使用户一次提交和多次提交的效果是一样的
- 保证接口幂等性
- 用悲观锁解决,在获取数据时进行加锁,当同时有多个请求时只有一个请求操作成功,其他请求都无法操作
- 用乐观锁的原理实现,为数据增加version版本号,更新数据前先和版本号作对比,不相等提示更新失败
- 幂等的本质是分布式锁的问题,分布式锁正常可以通过redis或zookeeper实现;在分布式环境下,锁定全局唯一资源,使请求串行化,实际表现为互斥锁,防止重复,解决幂等。
- 令牌机制
- 其实就是往页面和后台同时存放一个uuid,当用户发起需要幂等性保证的操作,那么在后台逻辑中,就需要把页面携带过来的uuid和 后台存储uuid进行一个对比,如果相同的话,就删除,后续 这个用户相同的点击的时候,就不会生效了, 要使用lua脚本原子验证令牌和删除令牌机制 ,否则还会有并发问题。
分布式锁
@Autowiredprivate RedisTemplate<String, String> redisTemplate;@Autowiredprivate RedissonClient redissonClient;@Overridepublic void redisLockCD() {//调用setnx方法原子性的设置线程名、版本号和线程失效时间Boolean lock = redisTemplate.opsForValue().setIfAbsent("lock", UUID.randomUUID().toString(),30L, TimeUnit.SECONDS);if(lock){//抢锁成功,执行逻辑String num = redisTemplate.opsForValue().get("num");Integer intNum = Integer.parseInt(num);intNum = intNum + 1;redisTemplate.opsForValue().set("num", intNum.toString());//直接delete删除会出现原子性问题,用lua表达式原子性的拿锁、比锁、释放锁。String luaString = "if redis.call('get',KEYS[1]) == ARGV[1] then return redis.call('del',KEYS[1]) else return 0 end";redisTemplate.execute(new DefaultRedisScript<Long>(luaString, Long.class), Arrays.asList("lock"), uuid);}else{try {Thread.sleep(20);} catch (InterruptedException e) {e.printStackTrace();}redisLockCD();}}
- 利用setNx和setEx方法向redis写一个字符串,写入成功返回1,失败返回0,client如果拿到的返回值结果为1,表示获取到了锁,就去执行相应业务逻辑,执行完释放锁,拿到的结果为0,表示没有获取到锁,自旋重新竞争锁。
但是这个方法有很多问题:
- 可能会出现死锁,我们需要在redis设置key的时候原子性的加锁和设置过期时间。
- 但是这样就会出现删除别人锁的情况,就是说当设置了过期时间后,线程1执行过程中出现了卡顿,把过期时间卡过了锁失效了,线程2抢到锁进来了, 线程1又不卡了继续执行,把线程2的锁给删除了。我们可以给每一个线程生成一个随机的id,当需要释放锁的时候先比较一下id是否相同,但是应该用lua表达式原子化的拿锁、比锁、删锁。不然中间有一步卡住还会出现问题。
前面解决问题的过程都让别的线程进入到锁内部了,就是锁不住的情况,所以我们使用redis提供的对于分布式支持的lock锁—redission,他的底层就是看门狗原理。
redisson分布式锁
他满足了一切悲观锁的特点:公平锁、非公平锁、可重入锁. ```java @Override public void testRedission() {
RLock lock = redissonClient.getLock(“lock”);
lock.lock(); // 续期
lock.lock(20,TimeUnit.SECONDS);
lock.lock(); //2
String num = redisTemplate.opsForValue().get("num");Integer intNum = Integer.parseInt(num);intNum = intNum + 1;redisTemplate.opsForValue().set("num", intNum.toString());lock.unlock();lock.unlock(); //释放}
```
- 他的锁有两个,一个传递时间的,一个不传递时间的,如果传递了时间,redis就不会进行续约逻辑,时间到了就释放锁。
- 如果不传递时间,则使用的是看门狗时间,除了抢锁以外,他还会利用异步编排的oncomplete 在抢锁完毕后,进行锁续期逻辑,底层会有一个timeTask的内部类,在此逻辑中进行续约,每次续约又续约成看门狗的默认时间,在1/3时间时候,又会执行续约逻辑

若有收获,就点个赞吧
0 人点赞
