rabbitmq的好处和缺点
- 优点:
- 异步:
- 削峰
- 解耦
缺点
简单模式
- 工作模式
- 分裂模式
- 路由模式
-
rabbitmq的消息丢失
消息 从发送到接收会有多个过程,发送给mq时会丢失,mq内部路由到阻塞列表会丢失,mq宕机会丢失,接收时也可能会丢失。
- 针对这些不同的情况有不同的解决方法
- 生产者确认机制
- MQ提供了一种机制,他给每一个消息都指定一个唯一的Id,发送消息的时候每一步不管成功或者失败都返回一个不同的结果,根据不同结果判断消息是在哪一步丢失的。
- mq持久化
- 消息持久化分为交换机持久化、队列持久化、消息持久化 ,默认都是开启的。
- 消费者确认机制
- Rabbit MQ确认消息被消费者消费后会立即删除,他是通过消费者回调机执来确定消费者是否成功处理消息的,消费者获取消息后向Rabbit MQ发送ACK回执,表示自己已经处理消息了。
- 确认模式有三种,默认auto:
- manual:手动ack,需要在业务代码结束后,调用api发送ack。
- auto:自动ack,由spring监测listener代码是否出现异常,没有异常则返回ack;抛出异常则返回nack
- none:关闭ack,MQ假定消费者获取消息后会成功处理,因此消息投递后立即被删除
- 失败重试机制
- 当消费者出现异常,会不断发消息给消费者,给MQ带来压力。
- 解决方法就是通过配置文件控制重新投递时间和投递次数。
- 生产者确认机制
注:ack应答机制,spring版的和原生版rabbit的mq ack机制是不一样的,我们就按照spring版的去记就ok
rabbitmq的消息重复消费
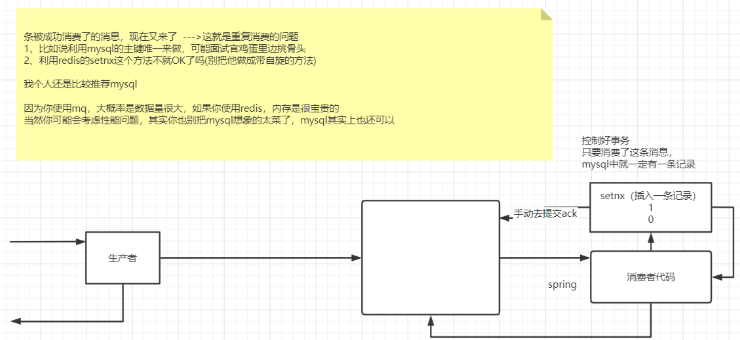
- 就是说一条消息已经被消费了, 在通过回调机制发送ACK的过程中出现网络抖动,把ACK抖没了,MQ就不知道这条消息已经被消费过了, 一段时间后又接着给消费者发这条消息,这就是消息的重复消费。
- 我们可以通过 利用Mysql的主键唯一来判断这条消息是否被消费过,如果被消费过手动再重新发一个ACK。
为什么不用redis的setnx来做这个事呢,因为当时我们组讨论了一下,认为既然都使用了mq,说明数据量是比较大的,用redis的话比较耗内存,还得考虑自旋问题,而且setnx设置了过期时间,万一还没到重新发送时间redis的数据就过期了,就没效果了。
rabbitmq的消息乱序
rabbitmq的消息乱序是什么情况?
- 就是说平时需要快速的处理消息或者当消息出现堆积的时候,为了提高消息的处理速度,新增了多台消息消费者,他们去不同的quaue中拿消息,然后再串行化的到mysql中执行,但是可能我消息生产者串行化的发送几条消息,比如,新增,修改,删除同一个数据,但是三条消息跑到不同的quaue中去了,可能有个消费者就先拿到删除或者修改了, 然后去数据库操作了,最后才进行新增操作,这个时候数据就存在了他不应该存在的值。这就是消息乱序。
解决方法
处理消息堆积的两大方案:
TTL+死信交换机
- 我们可以给消息本身或者消息所在的队列设置超时时间,当队列中的消息超时为未消费,就会变为死信,我们可以配置一个交换机,用于存放死信,或者队列满了也可以先放到死信交换机,交由人工处理,进一步提高消息队列的可靠性。
使用场景
普通集群
- 普通集群就是会在各个节点之间共享一部分数据,但是并不包含队列中的信息,访问集群节点的时候,如果队列不在该节点,就把消息从所在的节点传递到当前节点返回,但是当队列所在节点宕机,队列中的消息会丢失。
- 镜像集群
- 就是配置主从模式,交换机、队列、队列中的消息会在各个mq的镜像节点之间同步备份。
- 创建队列的节点被称为该队列的主节点,备份到的其它节点叫做该队列的镜像节点。
- 一个队列的主节点可能是另一个队列的镜像节点
- 所有操作都是主节点完成,然后同步给镜像节点
- 主宕机后,镜像节点会替代成新的主
仲裁队列
正常情况下我们是无法兼顾吞吐量和延迟性的,比如rabbitmq这种消息中间件,他会先把数据写到内存中,到一定时候再把数据一次性的从内存中写入磁盘中。
- 但是kafka却在保证海量吞吐量的情况下,还保持很低的延迟性,他在写数据的时候,直接把数据写入到os的page cache中,他就不管了 ,继续去进行其他的写入操作,而os 的page cache 定期进行磁盘顺序写,快速的进行数据落盘操作。
而读的时候,正常情况下是进行的非0拷贝,多了两次没有必要的上下文切换拷贝数据的过程,比较浪费性能,而采用0拷贝技术,os看page cache中有没有数据,没有就从磁盘中读取,有就直接拷贝给网卡了,中间不用再走page cache拷贝给应用系统,应用系统拷贝给socket这两个上下文切换和拷贝数据的过程,大大提高了读取速度。
kafka的日志文件和offset
kafka的每一个partition数据分区可以认为就-是一个日志文件,存放在某一台服务器上,每个日志文件里都放了很多消息,每个消息都有一个序号offset,代表的是第几条消息。
但在消费消息的时候,也有一个offset,这个offset代表的是消费者现在消费到日志文件中的第几条数据了。
kafka如何存储海量级数据?
kafka是支持分布式存储的,当有海量数据进行存储的时候,他会把业务拆分成多个topic 数据集,每个topic都有很多个partition数据分区,每一个partition就可以放在不同的机器上,每个分区采用负载均衡的方式分配数据进行存储,通过这个方式就可以实现数据的分布式存储了 。
kafka如何保证宕机时还具备高可用性?
采用分布式存储的话,当有一个kafka宕机了,就会损失一个partition的数据,所以我们采用多副本冗余机制,给每一个partition做几个副本,放到另外的机器上,然后kafka自动的从多个副本中选一个leader partition副本,负责提供对对外的读写操作,并且把接收过来的数据复制到其他副本上,实现数据同步。
就算某个机器宕机,leader partition没了,从副本中重新选举一个leader出来,实现kafka的高可用架构。
kafka如何保证消息不丢失?
多副本冗余机制只能保证kafka的高可用性,但是不能保证消息不会丢失,因为如果leader宕机了,但数据还没有同步到follower中,就算选举出来新的leader,还没同步的数据都丢失了。
- 解决方法是:
- ISR列表,存放和leader保持数据同步的follower,只有处于列表中的follower才能参与选举,为了保证消息不丢失,首先要保证ISR列表中至少得有一个follower,
- 其次发送消息的时候,要设置acks = all,要求一条消息写入leader中,就必须复制给ISR中的所有follower,才能代表这条数据已经提交。
- 解决方法是:
还有一种情况是offset的自动提交机制导致的,当消费者拿到消息后,消费者就每隔一段时间自动去维护offset,可能就会出现这个消息刚好到达了消费者,刚好又维护好了offset,刚好又到了提交时间,但又没来得及消费,就宕机了;等重启之后,在这个消费者眼里,这个消息已经被消费了。
有一批消息过来了 ,消费者这边消费成功了, 迟迟没有到offset提交时间,就宕机,内存里维护的那个offset并没有提交成功,在kafka的broker服务节点眼里,这个消息并没有被消费,当消费者重启之后,又把这个消息给消费者发过来。
生产者在写消息的时候,可以指定一个 key,比如说我们指定了某个订单 id 作为 key,那么这个订单相关的数据,一定会被分发到同一个 partition 中去,而且这个 partition 中的数据一定是有顺序的。
- 也可以在发送消息的时候,可以指定同一个分区,同一个分区下的数据是有序的。

若有收获,就点个赞吧
0 人点赞
