4.1 什么是dubbo(必会)
工作在soa面向服务分布式框架中的服务管理中间件。Dubbo是一个分布式服务框架,致力于提供高性能和透明化的RPC远程服务调用方案,以及SOA服务治理方案。
它最大的特点是按照分层的方式来架构,使用这种方式可以使各个层之间解耦合(或者最大限度地松耦合)。从服务模型的角度来看,Dubbo采用的是一种非常简单的模型,要么是提供方提供服务,要么是消费方消费服务,所以基于这一点可以抽象出服务提供方(Provider)和服务消费方(Consumer)两个角色。关于注册中心、协议支持、服务监控等内容。
Dubbo使用的是缺省协议, 采用长连接和nio异步通信, 适合小数据量大并发的服务调用,以及服务消费者机器数远大于服务提供者机器数的情况。
反之, dubbo缺省协议不适合传送大数据量的服务,比如传文件,传视频等,除非请求量很低。
4.2 Dubbo的实现原理(必会)
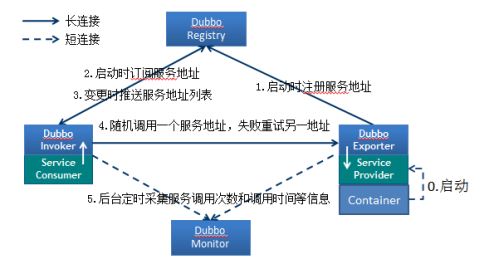
4.3 节点角色说明(必会)
Provider: 暴露服务的服务提供方。
Consumer: 调用远程服务的服务消费方。
Registry: 服务注册与发现的注册中心。
Monitor: 统计服务的调用次调和调用时间的监控中心。
Container: 服务运行容器。
4.4 调用关系说明(必会)
- 服务容器负责启动,加载,运行服务提供者。
2. 服务提供者在启动时,向注册中心注册自己提供的服务。
3. 服务消费者在启动时,向注册中心订阅自己所需的服务。
4. 注册中心返回服务提供者地址列表给消费者,如果有变更,注册中心将基于长连接推送变更数据给消费者。
5. 服务消费者,从提供者地址列表中,基于软负载均衡算法,选一台提供者进行调用,如果调用失败,再选另一台调用。
6. 服务消费者和提供者,在内存中累计调用次数和调用时间,定时每分钟发送一次统计数据到监控中心。4.5 在实际开发的场景中应该如何选择RPC框架(了解)
SpringCloud : Spring全家桶,用起来很舒服,只有你想不到,没有它做不到。可惜因为发布的比较晚,国内还没出现比较成功的案例,大部分都是试水,不过毕竟有Spring作背景,还是比较看好。
Dubbox:相对于Dubbo支持了REST,估计是很多公司选择Dubbox的一个重要原因之一,但如果使用Dubbo的RPC调用方式,服务间仍然会存在API强依赖,各有利弊,懂的取舍吧。
Thrift: 如果你比较高冷,完全可以基于Thrift自己搞一套抽象的自定义框架吧。
Hessian:如果是初创公司或系统数量还没有超过5个,推荐选择这个,毕竟在开发速度.运维成本.上手难度等都是比较轻量.简单的,即使在以后迁移至SOA,也是无缝迁移。
rpcx/gRPC:在服务没有出现严重性能的问题下,或技术栈没有变更的情况下,可能一直不会引入,即使引入也只是小部分模块优化使用。4.6 Dubbo的核心架构
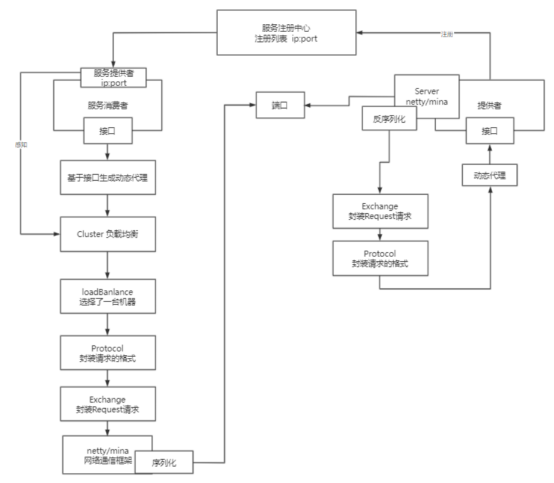
dubbo的核心原理(在讲完dubbo的大致内容) 实实在在能够帮你找到工作的东西
首先有一层接口,接口完事之后config,config去读取配置文件,拿到注册列表信息,需要针对当前这个接口生成一个代理问题,完事之后,其实现在dubbo就已经开始工作了,dubbo这个时候会从消费者方拉取下来的服务列表,然后把服务列表交给cluster这一层(他现在相当于就知道我能够调用哪些服务器了)但是,他得去进行负载均衡,这个负载均衡是依赖于cluster这一层 bloadBalance来选择
但是现在咱们如果想要通信还得选择一个对应的协议来完成 —>就是dubbo的通信协议
然后这个其实我们的请求就按照我们选择的协议进行组织数据了
你得先封装成一个对象,这个对象request对象,现在就可以传输了,但是由于涉及到网络传输,所以这个时候需要序列化,而且dubbo的底层采用的netty/mina这两个框架在进行传输数据的,所以说,你要先序列化,然后再把序列化好的数据交个 netty/mina然后再由他们两兄弟去把这个请求发出去。
消费者方法就依赖于传输层当然也是netty/mina拿到了序列化过后的数据,那么他就需要层层去解析。首先反序列化,然后通过exchange拿到他封装request对象,然后再去通过protocal拿到他的协议,然后走到现在终于知道消息者方到底想要干嘛了,然后这个时候其实可以去帮他实现了他想完成的事情,但是作为程序员而言,你是不是只有一个接口,明显dubbo过来的服务他没法调用,所以dubbo又对生产者方的接口生成了一个代理对象,然后再通过这个代理类对象去完成我们的调用。

若有收获,就点个赞吧
0 人点赞
