并发和并行
- 并发
- 多个任务在一个cpu上交替执行
并行
同步
-
tamcat并发低的原因
tomcat的并发处理为什么这么低,其实是因为tomcat的运行模式导致的,当用户去使用浏览器访问tomcat服务器的时候,首先会经过tcp协议的三次握手四次挥手保证网络通畅,最终通过双方的socket来发送请求和响应;
- 确认连接以后用户访问服务器,这个时候tomcat的线程监听器监听到信息,告知tomcat,tomcat就会从工作线程池中分配线程来完成本次的访问;
- 我们的项目都是部署在tomcat中,tomcat会将打包好的request发送给controller层,service层,dao层,最后和db进行数据交互,然后将结果打包成Response通过socket返回给用户;
- 因为tomcat的运行模式是同步阻塞的,所以他这整个执行流程都不会收回线程或者转移线程,而整个请求的完成其实是很费时间的,又因为tomcat本身的总线程并不多,所以tomcat的并发才这么低;
- 线程总数不多,tps不高
线程池的7大参数:
- 常驻线程数
- 最大线程数
- 线程销毁时间
- 时间单位
- 阻塞队列
- 默认工厂
- 拒绝策略
线程池原理:
线程池刚创建初始化好的时候他的线程数其实是0,当任务提交过来后,线程池会判断当前的线程数是不是小于常驻线程数,小于,就创建对应的常驻线程,当线程池中的线程不再小于常驻线程之后,就暂时不创建线程了,后面来了其他任务,就到阻塞队列排队,当阻塞队列满了,就根据最大线程数把其他零时线程创建出来,当阻塞队列又满了,执行对应的拒绝策略。当一段时间后,如果常驻线程能够把任务处理过来,就把零时线程销毁。
阿里手册上明确指出,原生线程池的阻塞队列是Integer.MAX_VALUE,也叫无界队列,队列太大,无数任务都可以提交到线程池内部,会把线程池 撑爆。
并发编程三大问题
什么是并发编程:
- 多个线程相互协作,一起完成同一件事情。
可见性问题
public class VolatileDemo {static int flag = 0;public static void main(String[] args) {//线程一new Thread(() -> {int localFlag = flag;while (true) {if (localFlag != flag) {System.out.println("线程一读取到被修改的值 " + flag);localFlag = flag;}}}).start();//线程二new Thread(() -> {int localFlag = flag;while (true) {System.out.println("线程二标志位被修改为了:" + ++localFlag);flag = localFlag;try {TimeUnit.SECONDS.sleep(2);} catch (Exception e) {e.printStackTrace();}}}).start();}
代码理解:根据代码的运行逻辑应该是线程一和线程二交替进行,可是实际运行情况却不是这样,而是线程一只执行了一次就不再执行了
- cpu内存模型
- 原因:现代计算机内存和cpu的读写速度差异大,cpu直接操作内存的话会导致性能变的很差,所以一般是给cpu加几层缓存,cpu就不需要频繁的跟内存通信,所以就会出现两个问题:
- 1.可能当前cpu修改的数据只是存储在了缓存中,并没有刷回内存中
- 2.就算刷回了内存中,其他cpu并不知道你内存中的数据已经发生了修改
- 解决方法:
- MESI缓存一致性协议
- 强制把数据刷写回主内存
- 嗅探机制:当cpu写完之后,会向其他cpu发送一个指令,让其他cpu中的缓存失效,从而其他cpu要重新从内存中加载数据
- MESI缓存一致性协议
- 原因:现代计算机内存和cpu的读写速度差异大,cpu直接操作内存的话会导致性能变的很差,所以一般是给cpu加几层缓存,cpu就不需要频繁的跟内存通信,所以就会出现两个问题:
java内存模型
原理:
- 基于cpu缓存模型来建立
把存放数据的地方分成了工作内存和主内存
- 工作步骤:
- 从主存中读取数据(read),将读取到的数据写入工作内存中(load),从工作内存中读取数据来计算(use),再将计算好的数据重新赋值到工作内存中(assign),将工作内存中的数据写入主存(store),再将store过去的变量值赋值给主存中的变量(write)
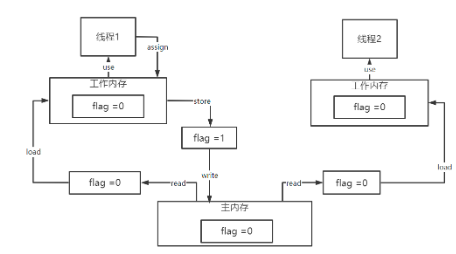
- 工作步骤:
1.同cpu模型一致,可能当前cpu修改的数据只是存储在了缓存中,并没有刷回内存中
- 2.就算刷回了内存中,其他cpu并不知道你内存中的数据已经发生了修改
- volatile解决可见性问题
- 成员变量加上volatile关键字后,只要修改成功,就会强制将工作内存中的数据写入主存(store),再将store过去的变量值赋值给主存中的变量(write),同时让其他cpu中的工作内存中的数据失效,其他cpu要重新从内存中加载数据。
原子性问题
for (int i = 0; i < 20; i++) {new Thread(()->{try {Thread.sleep(20);} catch (InterruptedException e) {e.printStackTrace();}System.out.println(num++);}).start();}
- 原子性:多个操作要么同时成功,要么同时失败
- Java内存模型把操作数据的过程分成了很多步,他执行每一步操作cpu的执行权都可能被别的线程抢走,当多条线程同时对一个数据进行修改时,线程一从工作内存中获取到数据,然后cpu执行权可能就被线程二抢走了,线程一就发生了阻塞,当线程二也获取到工作内存中的数据,然后对数据进行修改,当修改成功,就会强制刷写回主内存,并让其他线程中工作内存的数据失效,但线程一已经获取到工作内存中的数据了,工作内存中数据失效并不会影响他的执行,所以当他抢到cpu执行权时,他也会修改数据,当修改成功也会强制把数据刷写回主存,造成数据覆盖
- 解决方法
- 使用atomic原子性类中的CAS无锁化机制来解决
重排序问题
Atomic中CAS无锁化原理
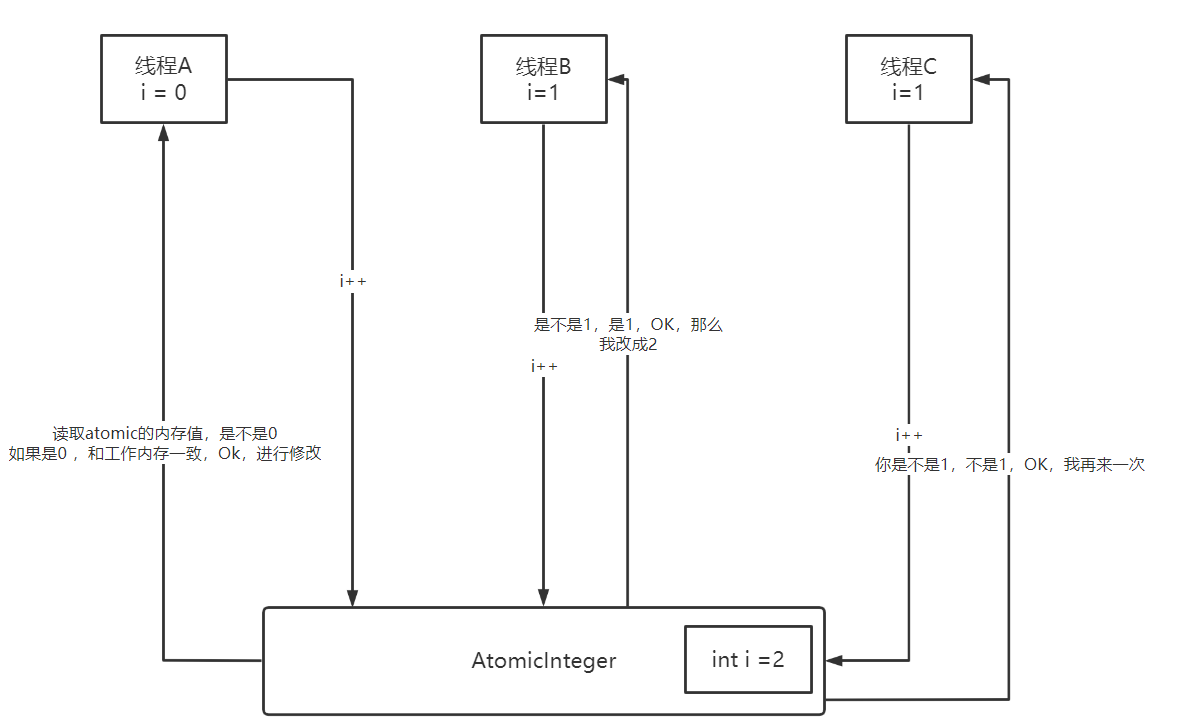
- CAS(比较并替换):无锁化机制
- 理解:CAS是一种无锁算法,CAS有3个操作数,内存值A,旧的预期值B,要修改的新值C。当且仅当预期值B和内存值A相同时,将内存值A修改为C,采用的乐观锁的思想;当预期值B和内存值A不相同,就会基于do while 循环 compareAndSwap来进行自旋。
 ```java
```java
//this:当前要操作的对象//valueOffset:当前要操作的变量偏移量(变量的内存当前值)//expect:期望内存中的值//update:要修改的新值
public final class Unsafe { //省略很多代码…… public final native boolean compareAndSwapInt(Object var1, long var2, int var4, int var5); //省略很多代码…… }
//读取传入对象this(var1)在内存中偏移量为valueOffset(var2)位置的值与期望值expect(var4)作比较。
//相等,就把update(var5)值赋值给valueOffset(var2)位置的值,方法返回true。
//不等,就取消赋值,方法返回false
- 优点:- 获得cpu底层支持,性能很高- 局部原子性,如果内存值==预估值,就一定会用修改值去替换内存值。- 缺点:- ABA问题:第二次拿到的数据虽然和第一次一样,但可能是别的线程改了后又被另外的线程改回来的数据- 解决方法:用版本号,标志位之类的方案解决,参考乐观锁- 高并发下大量线程执行不成功自旋对cpu造成巨大压力- 解决方法:利用LongAdder分布CAS机制优化多线程自旋问题- **unsafe类**- unsafe是JDK内部的类,提供了一些底层操作的不安全类,只有jdk内部可以拿到,atomic底层的操作就是依赖于unsafe```javapublic class CasSpinLock {//成员变量初始化static int num = 0;public static void main(String[] args) {//创建CAS无锁化对象SpinLock spinLock = new SpinLockCas();//循环创建多个线程对数据进行修改for (int i = 0; i < 20; i++) {new Thread(()->{//调用自定义CAS对象实现加锁功能spinLock.lock();System.out.println(num++);spinLock.unlock();}).start();}}}interface SpinLock{void lock();void unlock();}class SpinLockCas implements SpinLock{//创建AtomicInteger原子类AtomicInteger atomic = new AtomicInteger(0);@Overridepublic void lock() {//比较while(!atomic.compareAndSet(0,1)){}}@Overridepublic void unlock() {//替换atomic.compareAndSet(1,0);}}
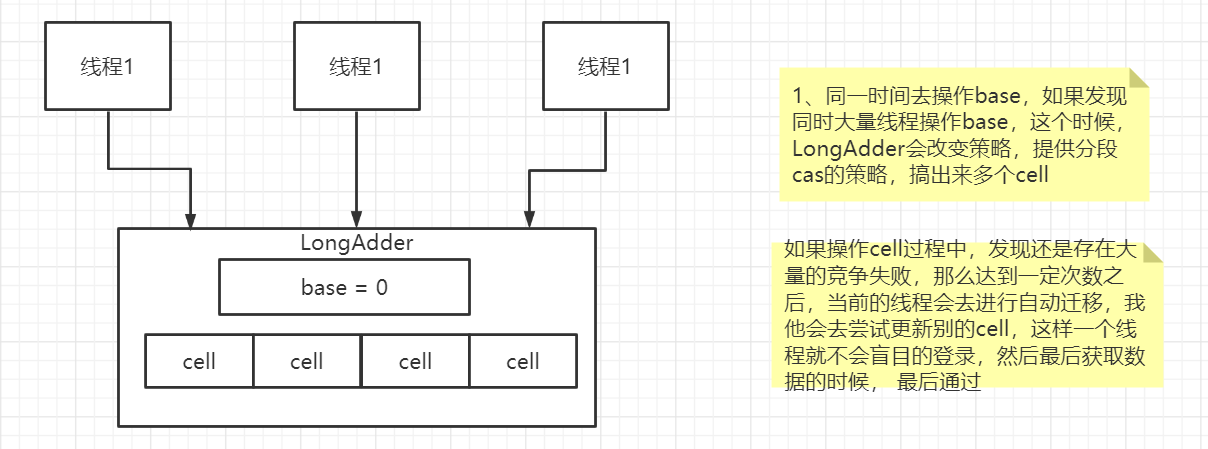
LongAdder优化CAS机制多线程自旋问题原理
- 这个类是jdk1.8之后提供的类
- 原理:
- 当有大量并发来操作base(就是Atomic里的Value),会创建出来很多cell,多个线程就去操作对应的cell
- 当有一个cell竞争很激烈容易失败,会自动迁移,把线程分配一些到其他cell中,如果每一个cell都竞争激烈,那就再创建cell
- 其实就是将内存中操作的变量拆分出来,让它变成多个变量( 这里和ConcurrentHashMap的原理就很相似了),然后让线程去竞争这些变量,将这些变量处理完后,然后在进行求和,这样降低了变量的并发度,减少了CAS失败次数
Threadlocal
volatile、atomic、threadLocal、读写锁使用建议
(1)关于volatile:简单读,简单写,如果仅仅只是去修改某一句代码的值,但是这个共享变量的值,是有人改,有人读,其实这种情况下就只需要添加volatile就可以了,比如源码分析中的一些标志位
(2)关于atomic:如果仅仅只是单纯的去累加一些值,推荐使用atomic,通过cas原子类来进行累加,性能比syn好得多
(3)关于threadLocal:如果你定义的一个成员变量不需要多个线程去进行共享操作的话,那么就可以使用threadLocal的副本机制,让每个线程都维护一个变量的副本,每个线程操作自己的变量
(4)关于读写锁:当多个线程来并发访问一块空间,而且业务稍微复杂一点,但是不是太复杂,就需要加锁了,优先考虑读写锁,syn锁太重了,在读多写少的这样一种情况下,读锁->大量线程并发的读,写数据时不能很多人同时过来写,也不能读,那么就应该使用读写锁
(5)不要让锁的时间过于长,尽量操作一些内存的一些数据就可以了。
(6)控制锁的粒度
多线程的使用
- 同步:产生阻塞,一个一个执行
异步:找别人帮我做,我接着做我自己的事
- 异步编排第一种使用:很多个查询或者很多个没有关联的分支都要执行 ```java @Autowired @Qualifier(“myThreadPool”) private Executor threadPool;
@Override public void submit(Orders orders) { Long userId = BaseContext.getCurrentId(); //第一条异步线程查询购物车数据并返回结果,supplyAsync方法带返回值 CompletableFuture
List<ShoppingCart> shoppingCarts = shoppingCartService.list(new LambdaQueryWrapper<ShoppingCart>().eq(ShoppingCart::getUserId, userId));if (shoppingCarts == null || shoppingCarts.size() == 0) {throw new CustomException("购物车为空,不能下单!");}log.info("查询购物车打印时间:"+LocalDateTime.now());return shoppingCarts;
},threadPool); //第二条异步线程查询用户数据并返回结果 CompletableFuture
taskUser = CompletableFuture.supplyAsync(() -> { User user = userService.getById(userId);log.info("查询用户打印时间:"+LocalDateTime.now());return user;
}, threadPool);
//雪花算法生产id Long orderId = IdWorker.getId(); //第三条异步线程查询地址数据并返回结果 CompletableFuture
taskAddressBook = CompletableFuture.supplyAsync(() -> { Long addressBookId = orders.getAddressBookId();AddressBook addressBook = addressBookService.getById(addressBookId);if (addressBook == null) {throw new CustomException("地址信息有误!");}log.info("查询地址打印时间:"+LocalDateTime.now());return addressBook;
}, threadPool); List
shoppingCarts =null; User user =null; AddressBook addressBook =null; try { CompletableFuture.allOf(taskUser,taskShoppingCarts,taskAddressBook).get();shoppingCarts = taskShoppingCarts.get();user = taskUser.get();addressBook = taskAddressBook.get();
} catch (Exception e) {
e.printStackTrace();
} ```
异步编排第二种使用:加载很大的任务,可以以分页的形式把大任务分成很多块。没有线程安全问题 ```java public class Test02 {
public static void main(String[] args) {
ExecutorService threadPool = Executors.newFixedThreadPool(5);//每个线程一次执行任务数int pageSize = 10;//最大任务量int allCount = 100;//计算最大执行次数int page = allCount % pageSize == 0 ? allCount / pageSize : allCount / pageSize + 1;//定义信号枪,没执行一次page减一,当page没有变成0,就会调用await()阻塞CountDownLatch cdl = new CountDownLatch(page);long startTime = System.currentTimeMillis();for (int i = 1; i <= page; i++) { // 1 2 3threadPool.submit(new TaskThread(i, pageSize,cdl));}//只有当他听到信号抢之后,主线程再往下边走,//而且信号枪什么时候响起来呢,当所有分线程都跑完得时候// countDownLatch 叫信号枪// countDownLatch countDown await countDownLatch//他得底层维护了一个变量 10 countDown --> 9 countDown -->8//当这个变量没有变为0之前,他就会阻塞try {cdl.await();} catch (Exception e) {e.printStackTrace();}long endTime = System.currentTimeMillis();System.out.println("最后执行结果" + (endTime-startTime));
}
static class TaskThread implements Runnable {
int page;int pageSize;CountDownLatch countDownLatch;public TaskThread(int page, int pageSize,CountDownLatch countDownLatch) {this.page = page;this.pageSize = pageSize;this.countDownLatch = countDownLatch;}// 想办法 0 1000:执行 0-999// 想办法:1 1000 执行 1000-1999// 想办法:2 1000执行 2000-2999// ....//当所有的循环都处理好之后,实际上所有的任务都完了@Overridepublic void run() {int startPage = (page-1)*pageSize; // 1 1000int endPage = (page * pageSize) -1 ; // 999 1999for (int i = startPage; i <= endPage; i++) {System.out.println(Thread.currentThread().getName() + "正在处理第" + i );}countDownLatch.countDown();}
}
}
```

若有收获,就点个赞吧
0 人点赞
