分布与回归
监督机器学习问题主要有两种,分别叫作分类(classifification)与回归(regression)。
分类问题的目标是预测类别标签(class label),这些标签来自预定义的可选列表。
分类问题可分为二分类和多分类。
在二分类问题中,我们通常将其中一个类别称为正类(positive class),另一个类别称为反类(negative class)。这里的“正”并不代表好的方面或正数,而是代表研究对象。将两个类别中的哪一个作为“正类”,往往是主观判断,与具体的领域有关。
鸢尾花的例子则属于多分类问题。另一个多分类的例子是根据网站上的文本预测网站所用的语言。这里的类别就是预定义的语言列表。
- 回归任务的目标是预测一个连续值,编程术语叫作浮点数(flfloating-point number)。
- 区分分类任务和回归任务有一个简单方法,就是问一个问题:输出是否具有某种连续性。如果在可能的结果之间具有连续性,那么它就是一个回归问题。
泛化、过拟合与欠拟合
在监督学习中,我们在训练数据上构建模型,然后能够对没见过的新数据(具有相同的特性)做出准确预测。如果一个模型能够对没见过的数据做出准确预测,我们就说它能够从训练集泛化(generalize)到测试集。
- 一个模型过于复杂,我们过分关注训练集上每个单独的数据点,而无法很好地泛化到新数据上,我们称之为过拟合。
- 一个模型过于简单,无法抓住数据的全部 内容以及数据中的变化,模型甚至在训练集上的表现就很差,我们称之为过拟合。
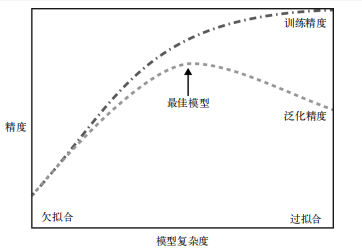
需要注意,模型复杂度与训练数据集中输入的变化密切相关:数据集中包含的数据点的变化范围越大,在不发生过拟合的前提下你可以使用的模型就越复杂。通常来说,收集更多的数据点可以有更大的变化范围,所以更大的数据集可以用来构建更复杂的模型。但是,仅复制相同的数据点或收集非常相似的数据是无济于事的。
收集更多数据,适当构建更复杂的模型,对监督学习任务往往特别有用,这可能比模型调参更为有效。永远不要低估更多数据的力量!
监督学习算法
- 从特征较少的数据集(也叫低维数据集)中得出的结论可能并不适用于特征较多的数据集(也叫高维数据集)。
- 要扩展数据集,输入特征不仅可以包括测量结果,还包括这些特征之间的乘积(也叫交互项)。像这样包含导出特征的方法叫作特征工程。

若有收获,就点个赞吧
0 人点赞
