决策树是广泛用于分类和回归任务的模型。
本质上,它从一层层的 if/else 问题中进行学习,并得出结论。
构造决策树
我们在二维分类数据集上构造决策树。这个数据集由 2 个半月形组成,每个类别都包含 50 个数据点。我们将这个数据集称为 twomoons。
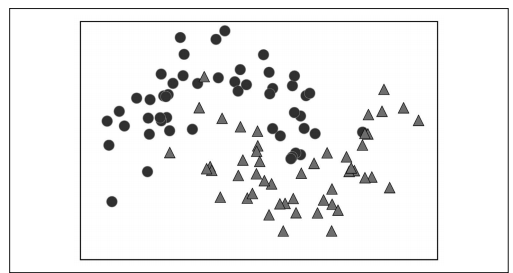
学习决策树,就是学习一系列 if/else 问题,使我们能够以最快的速度得到正确答案。在机器学习中,这些问题叫作测试(不要与测试集弄混,测试集是用来测试模型泛化性能的数据)。
数据通常并不是像动物的例子那样具有二元特征(是 / 否)的形式,而是表示为连续特。用于连续数据的测试形式是:“特征 _i 的值是否大于 a ?”
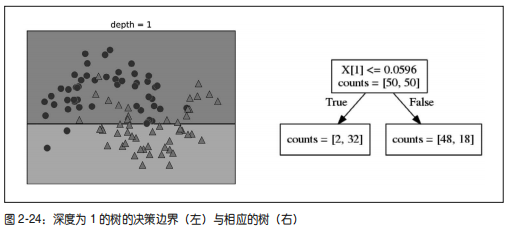


控制决策树的复杂度
通常来说,构造决策树直到所有叶结点都是纯的叶结点,这会导致模型非常复杂,并且对训练数据高度过拟合。纯叶结点的存在说明这棵树在训练集上的精度是 100%。训练集中的每个数据点都位于分类正确的叶结点中。
防止过拟合有两种常见的策略:
一种是及早停止树的生长,也叫预剪枝(pre-pruning);
一种是先构造树,但随后删除或折叠信息量很少的结点,也叫后剪枝(post-pruning)或剪枝(pruning)。预剪枝的限制条件可能包括限制树的最大深度、限制叶结点的最大数目, 或者规定一个结点中数据点的最小数目来防止继续划分。
scikit-learn 的决策树在 DecisionTreeRegressor 类和 DecisionTreeClassifier 类中实现。
scikit-learn 只实现了预剪枝,没有实现后剪枝。
我们在乳腺癌数据集上更详细地看一下预剪枝的效果。和前面一样,我们导入数据集并将其分为训练集和测试集。然后利用默认设置来构建模型,默认将树完全展开(树不断分支,直到所有叶结点都是纯的)。我们固定树的 random_state,用于在内部解决平局问题:

若有收获,就点个赞吧
0 人点赞
