决策树是广泛用于分类和回归任务的模型。
本质上,它从一层层的 if/else 问题中进行学习,并得出结论。
构造决策树
我们在二维分类数据集上构造决策树。这个数据集由 2 个半月形组成,每个类别都包含 50 个数据点。我们将这个数据集称为 twomoons。
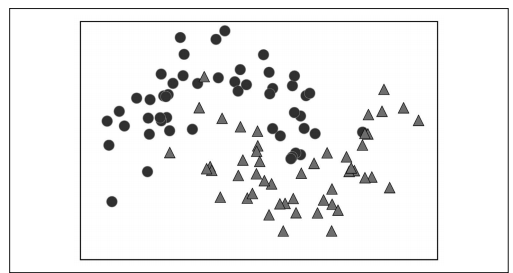
学习决策树,就是学习一系列 if/else 问题,使我们能够以最快的速度得到正确答案。在机器学习中,这些问题叫作测试(不要与测试集弄混,测试集是用来测试模型泛化性能的数据)。
数据通常并不是像动物的例子那样具有二元特征(是 / 否)的形式,而是表示为连续特。用于连续数据的测试形式是:“特征 _i 的值是否大于 a ?”


控制决策树的复杂度
通常来说,构造决策树直到所有叶结点都是纯的叶结点,这会导致模型非常复杂,并且对训练数据高度过拟合。纯叶结点的存在说明这棵树在训练集上的精度是 100%。训练集中的每个数据点都位于分类正确的叶结点中。
防止过拟合有两种常见的策略:
一种是及早停止树的生长,也叫预剪枝(pre-pruning);
一种是先构造树,但随后删除或折叠信息量很少的结点,也叫后剪枝(post-pruning)或剪枝(pruning)。预剪枝的限制条件可能包括限制树的最大深度、限制叶结点的最大数目, 或者规定一个结点中数据点的最小数目来防止继续划分。
scikit-learn 的决策树在 DecisionTreeRegressor 类和 DecisionTreeClassifier 类中实现。
scikit-learn 只实现了预剪枝,没有实现后剪枝。
我们在乳腺癌数据集上更详细地看一下预剪枝的效果。和前面一样,我们导入数据集并将其分为训练集和测试集。然后利用默认设置来构建模型,默认将树完全展开(树不断分支,直到所有叶结点都是纯的)。我们固定树的 random_state,用于在内部解决平局问题:
In:from sklearn.tree import DecisionTreeClassifiercancer = load_breast_cancer()X_train, X_test, y_train, y_test = train_test_split(cancer.data, cancer.target, stratify=cancer.target, random_state=42)tree = DecisionTreeClassifier(random_state=0)tree.fit(X_train, y_train)print("Accuracy on training set: {:.3f}".format(tree.score(X_train, y_train)))print("Accuracy on test set: {:.3f}".format(tree.score(X_test, y_test)))Out:Accuracy on training set: 1.000Accuracy on test set: 0.937
不出所料,训练集上的精度是 100%,这是因为叶结点都是纯的,树的深度很大,足以完美地记住训练数据的所有标签。测试集精度比之前讲过的线性模型略低,线性模型的精度约为 95%。
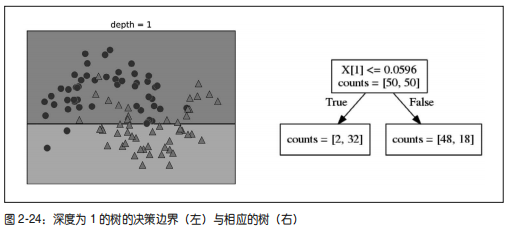
如果我们不限制决策树的深度,它的深度和复杂度都可以变得特别大。因此,未剪枝的树容易过拟合,对新数据的泛化性能不佳。现在我们将预剪枝应用在决策树上,这可以在完美拟合训练数据之前阻止树的展开。一种选择是在到达一定深度后停止树的展开。这里我
们设置 max_depth=4,这意味着只可以连续问 4 个问题(参见图 2-24 和图 2-26)。限制树的
深度可以减少过拟合。这会降低训练集的精度,但可以提高测试集的精度:
In:tree = DecisionTreeClassifier(max_depth=4, random_state=0)tree.fit(X_train, y_train)print("Accuracy on training set: {:.3f}".format(tree.score(X_train, y_train)))print("Accuracy on test set: {:.3f}".format(tree.score(X_test, y_test)))Out:Accuracy on training set: 0.988Accuracy on test set: 0.951
分析决策树
我们可以利用 tree 模块的 export_graphviz 函数来将树可视化。这个函数会生成一个 .dot 格式的文件,这是一种用于保存图形的文本文件格式。我们设置为结点添加颜色的选项,颜色表示每个结点中的多数类别,同时传入类别名称和特征名称,这样可以对树正确标记:
In:from sklearn.tree import export_graphvizexport_graphviz(tree, out_file="tree.dot", class_names=["malignant","benign"],feature_names=cancer.feature_names, impurity=False, filled=True)
我们可以利用 graphviz 模块读取这个文件并将其可视化(你也可以使用任何能够读取 .dot文件的程序),见图 2-27:
In:import graphvizwith open("tree.dot") as f:dot_graph = f.read()graphviz.Source(dot_graph)

树的特征重要性
查看整个树可能非常费劲,除此之外,我还可以利用一些有用的属性来总结树的工作原理。其中最常用的是特征重要性(feature importance),它为每个特征对树的决策的重要性进行排序。对于每个特征来说,它都是一个介于 0 和 1 之间的数字,其中 0 表示“根本没用到”,1 表示“完美预测目标值”。特征重要性的求和始终为 1:
In:print("Feature importances:\n{}".format(tree.feature_importances_))Out:Feature importances:[ 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.010.048 0. 0. 0.002 0. 0. 0. 0. 0. 0.727 0.0460. 0. 0.014 0. 0.018 0.122 0.012 0. ]
我们可以将特征重要性可视化,与我们将线性模型的系数可视化的方法类似(图 2-28):
In:def plot_feature_importances_cancer(model):n_features = cancer.data.shape[1]plt.barh(range(n_features), model.feature_importances_, align='center')plt.yticks(np.arange(n_features), cancer.feature_names)plt.xlabel("Feature importance")plt.ylabel("Feature")plot_feature_importances_cancer(tree)
这里我们看到,顶部划分用到的特征(“worst radius”)是最重要的特征。这也证实了我们在分析树时的观察结论,即第一层划分已经将两个类别区分得很好。

若有收获,就点个赞吧
0 人点赞
