寄存器(register)
这是最快的存储区,因为它位于不同于其他存储区的地方——处理器内部。但是寄存器的数量极其有限,所以寄存器由编译器根据需求进行分配。java中,你不能直接控制,也不能在程序中感觉到寄存器存在的任何迹象。 C语言可以定义寄存器变量。
栈(stack)
存放基本类型的变量数据和对象的引用,但对象本身不存放在栈中。
位于通用RAM(random-access memory )中,但通过它的“堆栈指针”可以从处理器哪里获得支持。堆栈指针若向下移动,入栈操作,则在栈顶分配新的内存;若向上移动,出栈操作,则在栈顶释放那些内存。这是一种快速有效的分配存储方法,仅次于寄存器。创建程序时候,JAVA编译器必须知道存储在堆栈内所有数据的确切大小和生命周期,因为它必须生成相应的代码,以便上下移动堆栈指针。这一约束限制了程序的灵活性,所以虽然某些JAVA数据存储在堆栈中——特别是对象引用,但是JAVA对象不存储其中。
{int c=6; //at line1c++;//at line2}c++;//at line3• 1
这是Java的普通代码块。编译器先在编译时在第一行的时候就在堆栈中分配一个储存数据为6的对象,当程序运行完这个花括后,存储为6的地址便会被销毁,于是第三行就会发生编译错误。所以这也为什么堆栈中的数据不能被多个线程共享的原因。
堆(heap)
存放所有new出来的对象。
一种通用性的内存池(也存在于RAM中(random-access memory )),用于存放所有的JAVA对象。堆不同于栈的好处是:编译器不需要知道要从堆里分配多少存储区域,也不必知道存储的数据在堆里存活多长时间。因此,在堆里分配存储有很大的灵活性。当你需要创建一个对象的时候,只需要new写一行简单的代码,当执行这行代码时,会自动在堆里进行存储分配。当然,为这种灵活性必须要付出相应的代码。用堆进行存储分配比用堆栈进行存储存储需要更多的时间。
堆内存和栈内存确实是我们常常用的东西,比如 Animal a = new Animal(); 这个时候相当于在堆内存中开辟了一个空间保存了Animal的信息以及着块空间的内存地址,然后在栈内存中划了一小快空间保存了堆中的内存地址,这个时候我们就可以说引用a指向Animal()了. 可是有时候,有个静态类.Animal,里面有个静态方法speak(); 那么可以这么直接调用Animal.sepak(); 这个时候既没有new,也没有Animal a=??; 所以既没有在堆中开辟空间也没有在栈内存中开辟空间 , 可是方法确实能执行,一切程序都运行在内存里,那么证明有新的内存区,就是静态空间了.
常量池(constant storage)
常量值通常直接存放在程序代码内部,这样做是安全的,因为它们永远不会被改变。有时,在嵌入式系统中,常量本身会和其他部分分割离开,所以在这种情况下,可以选择将其放在ROM(read only memory)中。
声明为final static的为常量,可以保存在常量池,还有String类型的对象都是常量,系统维护了一个String常量池。 String类型是final修饰的,无法被继承。
String s = new String("Hello world!");• 1
上面这行代码一共创建了几个对象?答案是不确定的,因为不知道常量池中存不存在Hello world!字符常量。如果存在,则只创建一个String类型的对象在堆上,如果不存在则在堆上创建一个String对象,并在常量池创建一个字符常量Hello world!对象。需要注意的是,常量池在java类加载的过程中会有很多字符常量被创建,需要比对的字符常量可能已经存在,只是你不知道而已。
图解
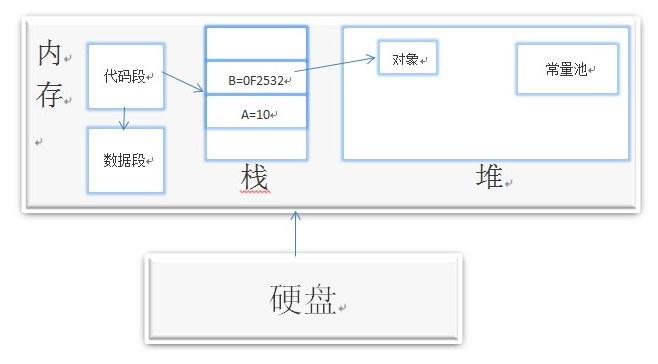
堆和栈示例
1.一个Java文件,只要有main入口方法,我们就认为这是一个Java程序,可以单独编译运行。
2.无论是普通类型的变量还是引用类型的变量(俗称实例),都可以作为局部变量,他们都可以出现在栈中。只不过普通类型的变量在栈中直接保存它所对应的值,而引用类型的变量保存的是一个指向堆区的指针,通过这个指针,就可以找到这个实例在堆区对应的对象。因此,普通类型变量只在栈区占用一块内存,而引用类型变量要在栈区和堆区各占一块内存。
3.在方法的参数传递中,基本数据类型,String类是按值传递,即拷贝了一个副本!引用数据类型是按引用传递,即把栈中的地址传入!
示例:
1.JVM自动寻找main方法,执行第一句代码,创建一个Test类的实例,在栈中分配一块内存,存放一个指向堆区对象的指针110925。
2.创建一个int型的变量date,由于是基本类型,直接在栈中存放date对应的值9。
3.创建两个BirthDate类的实例d1、d2,在栈中分别存放了对应的指针指向各自的对象。他们在实例化时调用了有参数的构造方法,因此对象中有自定义初始值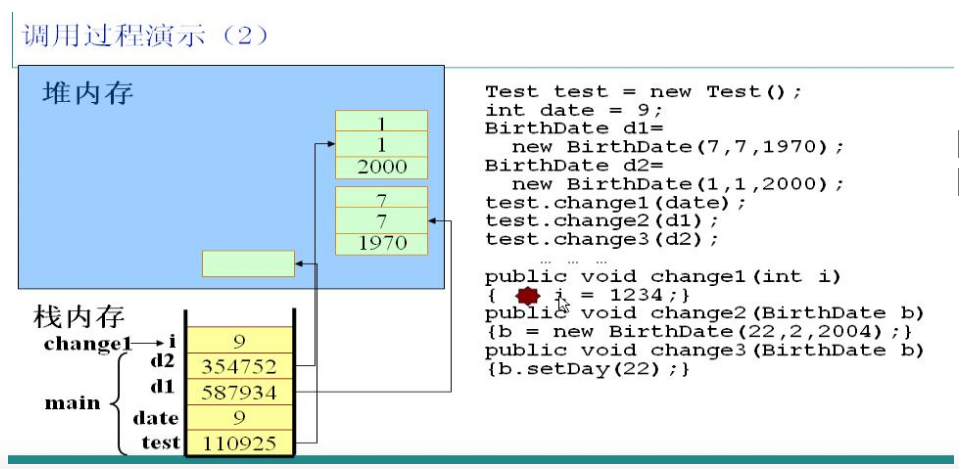
调用test对象的change1方法,并且以date为参数。JVM读到这段代码时,检测到i是局部变量,因此会把i放在栈中,并且把date的值赋给i。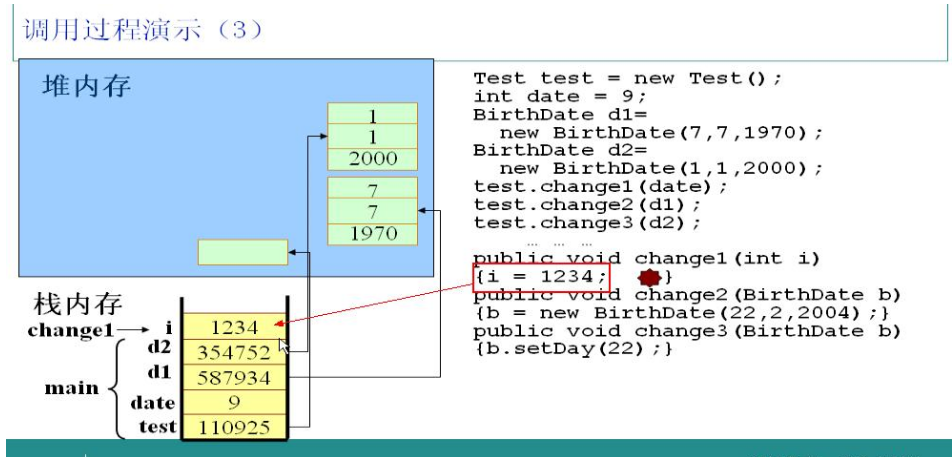
把1234赋给i。很简单的一步。
change1方法执行完毕,立即释放局部变量i所占用的栈空间。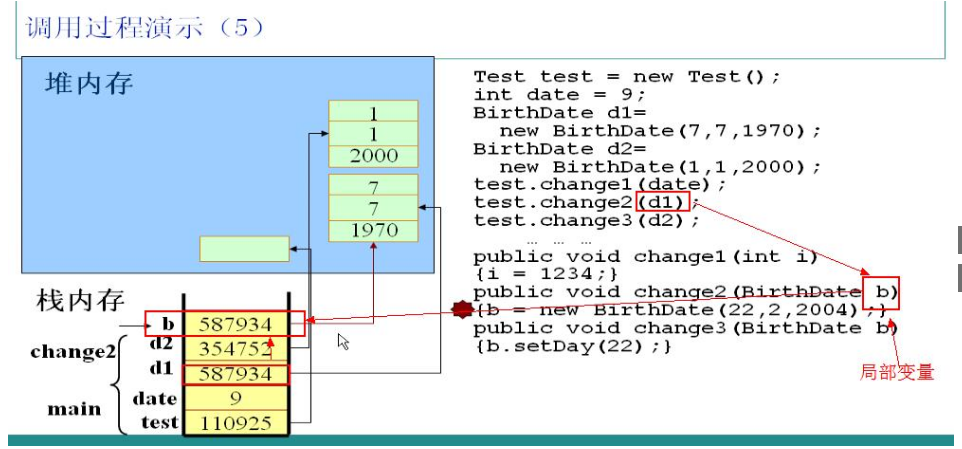
调用test对象的change2方法,以实例d1为参数。JVM检测到change2方法中的b参数为局部变量,立即加入到栈中,由于是引用类型的变量,所以b中保存的是d1中的指针,此时b和d1指向同一个堆中的对象。在b和d1之间传递是指针。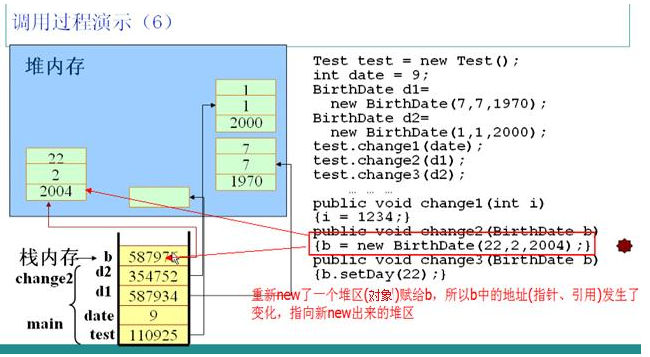
change2方法中又实例化了一个BirthDate对象,并且赋给b。在内部执行过程是:在堆区new了一个对象,并且把该对象的指针保存在栈中的b对应空间,此时实例b不再指向实例d1所指向的对象,但是实例d1所指向的对象并无变化,这样无法对d1造成任何影响。
change2方法执行完毕,立即释放局部引用变量b所占的栈空间,注意只是释放了栈空间,堆空间要等待自动回收。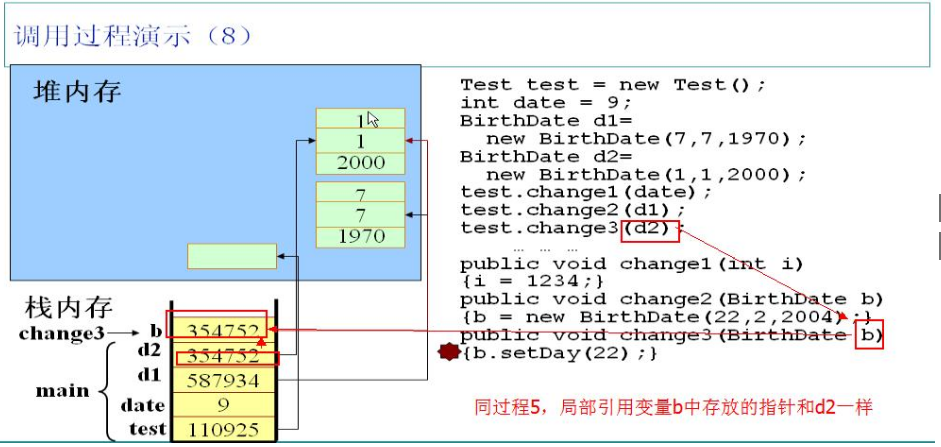
调用test实例的change3方法,以实例d2为参数。同理,JVM会在栈中为局部引用变量b分配空间,并且把d2中的指针存放在b中,此时d2和b指向同一个对象。再调用实例b的setDay方法,其实就是调用d2指向的对象的setDay方法。
调用实例b的setDay方法会影响d2,因为二者指向的是同一个对象。
change3方法执行完毕,立即释放局部引用变量b。
- 以上就是Java程序运行时内存分配的大致情况。其实也没什么,掌握了思想就很简单了。无非就是两种类型的变量:基本类型和引用类型。二者作为局部变量,都放在栈中,基本类型直接在栈中保存值,引用类型只保存一个指向堆区的指针,真正的对象在堆里。作为参数时基本类型就直接传值,引用类型传指针。
常量池示例
public class test {public static void main(String[] args) {objPoolTest();}public static void objPoolTest() {int i = 40;int i0 = 40;Integer i1 = 40;Integer i2 = 40;Integer i3 = 0;Integer i4 = new Integer(40);Integer i5 = new Integer(40);Integer i6 = new Integer(0);Double d1=1.0;Double d2=1.0;System.out.println("i=i0\t" + (i == i0));System.out.println("i1=i2\t" + (i1 == i2));System.out.println("i1=i2+i3\t" + (i1 == i2 + i3));System.out.println("i4=i5\t" + (i4 == i5));System.out.println("i4=i5+i6\t" + (i4 == i5 + i6));System.out.println("d1=d2\t" + (d1==d2));System.out.println();}}
结果为:
i=i0 truei1=i2 truei1=i2+i3 truei4=i5 falsei4=i5+i6 trued1=d2 false
结果分析:
- i和i0均是普通类型(int)的变量,所以数据直接存储在栈中,而栈有一个很重要的特性:栈中的数据可以共享。当我们定义了int i = 40;,再定义int i0 = 40;这时候会自动检查栈中是否有40这个数据,如果有,i0会直接指向i的40,不会再添加一个新的40。
- i1和i2均是引用类型,在栈中存储指针,因为Integer是包装类。由于Integer包装类实现了常量池技术,因此i1、i2的40均是从常量池中获取的,均指向同一个地址,因此i1=12。
- 很明显这是一个加法运算,Java的数学运算都是在栈中进行的,Java会自动对i1、i2进行拆箱操作转化成整型,因此i1在数值上等于i2+i3。
- i4和i5均是引用类型,在栈中存储指针,因为Integer是包装类。但是由于他们各自都是new出来的,因此不再从常量池寻找数据,而是从堆中各自new一个对象,然后各自保存指向对象的指针,所以i4和i5不相等,因为他们所存指针不同,所指向对象不同。
- 这也是一个加法运算,和3同理。
- d1和d2均是引用类型,在栈中存储指针,因为Double是包装类。但Double包装类没有实现常量池技术,因此Doubled1=1.0;相当于Double d1=new Double(1.0);,是从堆new一个对象,d2同理。因此d1和d2存放的指针不同,指向的对象不同,所以不相等。
小结:
- 以上提到的几种基本类型包装类均实现了常量池技术,但他们维护的常量仅仅是【-128至127】这个范围内的常量,如果常量值超过这个范围,就会从堆中创建对象,不再从常量池中取。比如,把上边例子改成Integer i1 = 400; Integer i2 = 400;,很明显超过了127,无法从常量池获取常量,就要从堆中new新的Integer对象,这时i1和i2就不相等了。
- String类型也实现了常量池技术,但是稍微有点不同。String型是先检测常量池中有没有对应字符串,如果有,则取出来;如果没有,则把当前的添加进去。

若有收获,就点个赞吧
0 人点赞
