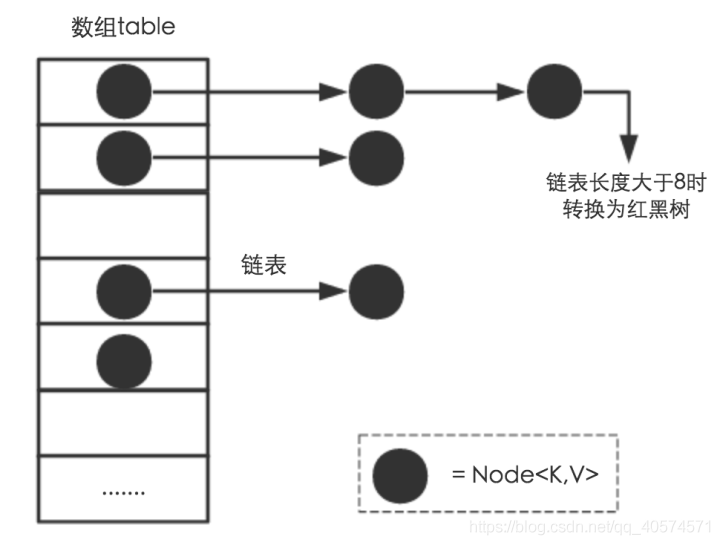
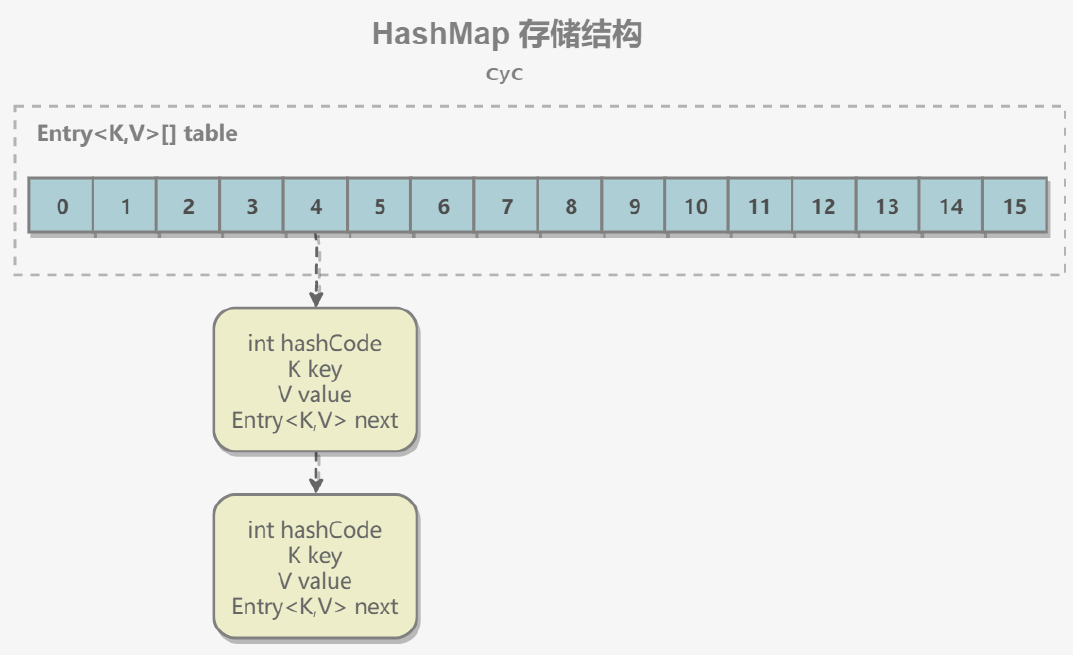
内部结构
内部包含了一个 Entry 类型的数组 table。Entry 存储着键值对。它包含了四个字段,从 next 字段我们可以看出 Entry 是一个链表。即数组中的每个位置被当成一个桶,一个桶存放一个链表。HashMap 使用拉链法来解决冲突,同一个链表中存放哈希值和散列桶取模运算结果相同的 Entry。
确定桶下标
很多操作都需要先确定一个键值对所在的桶下标。
int hash = hash(key);int i = indexFor(hash, table.length);
计算 hash 值然后再对桶个数取模:hash%capacity
扩容
设 HashMap 的 table 长度为 M,需要存储的键值对数量为 N,如果哈希函数满足均匀性的要求,那么每条链表的长度大约为 N/M,因此查找的复杂度为 O(N/M)。
为了让查找的成本降低,应该使 N/M 尽可能小,因此需要保证 M 尽可能大,也就是说 table 要尽可能大。HashMap 采用动态扩容来根据当前的 N 值来调整 M 值,使得空间效率和时间效率都能得到保证。
和扩容相关的参数主要有:capacity、size、threshold 和 load_factor。
(1) 扩容是一个特别耗性能的操作,所以当程序员在使用HashMap的时候,估算map的大小,初始化的时候给一个大致的数值,避免map进行频繁的扩容。
(2) 负载因子是可以修改的,也可以大于1,但是建议不要轻易修改,除非情况非常特殊。
(3) HashMap是线程不安全的,不要在并发的环境中同时操作HashMap,建议使用ConcurrentHashMap。
(4) JDK1.8引入红黑树大程度优化了HashMap的性能。

若有收获,就点个赞吧
0 人点赞
