关联字段类型应用
join父子关系
- 概念定义:
数据存在父子关系
一条数据可以有多条子数据
一条子数据仅有一条父数据
- 优点:
数据更新分离影响
- 注意事项:
父子数据必须在同一分片上
父子层级深度要注意
一个索引仅容许一对父子关系约束
一个父关系可以支持多个字对应关系
定义类型和join索引:
定义join关系为order_join,其中order是父文档,suborder是子文档。
DELETE myorderPUT myorder{"mappings": {"properties": {"order_join": {"type": "join","relations":{"order": "suborder"}}}}}
创建mapping
PUT myorder/_mapping{"properties": {"orderId": {"type": "keyword"},"shortTime": {"type": "date"},"name": {"type": "keyword"},"amount": {"type": "double"},"desc": {"type": "text"}}}
插入主单数据:
order_join定义为order类型
PUT myorder/_doc/10001{"shortTime": "2019-01-05","orderId": "10001","name": "user2","amount": 123.09,"desc": "其他收入","order_join": "order"}
插入子单数据
建立父子关系索引,routing 参数是必须的,因为父子文档必须在同一个分片上
POST myorder/_doc?routing=1{"shortTime": "2019-01-05","orderId": "10001","name": "user2","amount": 12.09,"desc": "收入","order_join": {"name": "suborder","parent":"10001"}}POST myorder/_doc?routing=1{"shortTime": "2019-01-05","orderId": "10002","name": "user2","amount": 122.09,"desc": "收入","order_join": {"name": "suborder","parent":"10001"}}
查询主单:
GET myorder/_search{"query": {"has_child" : {"type" : "suborder","query" : {"match_all" : {}}}}}
查询子单:
GET myorder/_search{"query": {"has_parent" : {"parent_type" : "order","query" : {"match_all" : {}}}}}
聚和查询
GET myorder/_search{"query": {"parent_id": {"type": "suborder","id": "10001"}},"aggs": {"parents12312": {"terms": {"field": "order_join#order"},"aggs": {"sumAmount": {"stats": {"field": "amount"}}}}}}
子聚会查询
GET myorder/_search{"size": 0,"aggs": {"parent": {"children": {"type": "suborder"},"aggs": {"sumAmount": {"stats": {"field": "amount"}}}}}}
聚合加筛选:
GET myorder/_search{"query": {"has_child" : {"type" : "suborder","query" : {"match_all" : {}}}},"aggs": {"parent": {"children": {"type": "suborder"},"aggs": {"fields": {"terms": {"field": "orderId"},"aggs": {"sumAmount": {"sum": {"field": "amount"}},"having": {"bucket_selector": {"buckets_path": {"orderCount": "_count","sumAmount": "sumAmount"},"script": {"source": "params.sumAmount >= 100 && params.orderCount >=0"}}}}}}}}}
定义一对多的索引
一对一的索引模型很难满足日常业务的数据处理,es也支持一对多的join
PUT myorder{"mappings": {"_doc": {"properties": {"order_join": {"type": "join","relations": {"order": ["suborder1", "suborder2"],"suborder2":"suborder3"}}}}}}
上面的索引的关联的关系如下:
order/ \suborder1 suborder2\suborder3
nested:嵌套
概念解释:
数组键值对查询会出现数据查询误差,Nested解决键值对查询误差
嵌套类型是对象数据类型的一个特例,允许对象数组彼此独立地进行索引和查询, 可以让array类型的对象被独立索引和搜索.
内置实现:
存储多条文档数据,通过内置查询关联合并为一条数据
注意事项:
- 嵌套深度
- 单条嵌套数据量条数限制
- 字段嵌套数量限制默认50
- 字段嵌套对象限制默认10000
使用场景:
子文档(例如:上面的user), 较少更新,查询频繁的场景
说明:
当不使用nested字段类型时候,对于某个字段,其值是一个列表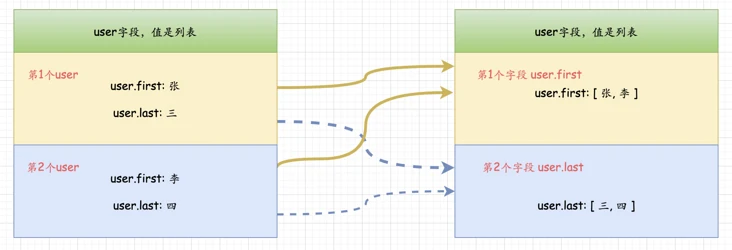
如上图,用户张三 和 李四的信息混合到一起,此时查找张四,同样可以获取
PUT test-009/_doc/1{"group": "fans","user": [{"first": "张","last": "三"},{"first": "李","last": "四"}]}GET test-009/_search{"query": {"bool": {"filter": [{"term": {"user.first.keyword": "张"}},{"term": {"user.last.keyword": "四"}}]}}}
设置nested类型
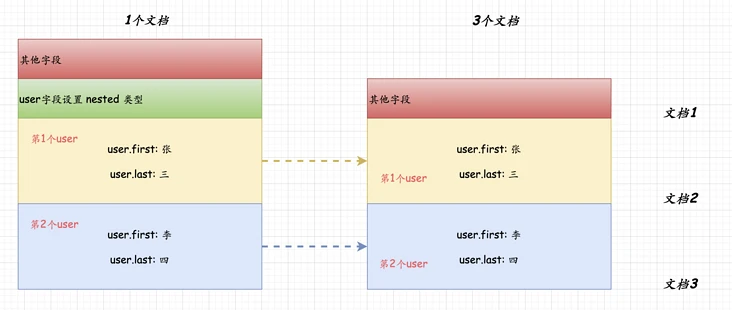
如上图,设置user字段类型为 nested, 在lucene内部,会存储为3个文档,其中nested类型的每个元素都作为一个独立的文档存在
注意:查询nested字段需要使用nested查询语法
DELETE test-009PUT test-009/{"mappings": {"properties": {"user": {"type": "nested"}}}}PUT test-009/_doc/1{"group": "fans","user": [{"first": "张","last": "三"},{"first": "李","last": "四"}]}GET test-009/_search{"query": {"nested": {"path": "user","query": {"bool": {"filter": [{"term": {"user.first.keyword": "张"}},{"term": {"user.last.keyword": "三"}}]}}}}}
辅助字段类型应用
alias别名:
- 命名应用:
字段代理
字段指向
避免直接暴露原始字段
- 注意事项:
数据不可以更新
别名不存储任何数据,仅仅是路径指向
PUT test-008{"mappings": {"properties": {"company1":{"type": "text"},"companyName":{"type": "alias","path":"company1"}}}}POST test-008/_doc{"company1":"liwenjun"}GET test-008/_search{"query": {"match": {"companyName": "liwenjun"}}}
单值多字段:
Multi-fileds
概念定义:
一个字段用途多种场景,可以设计为多种类型同时支持原数据仅存储一份,节约空间
应用领域:
多用途多场景检索需求
如:字符检索效率比数值要高效
PUT test-100{"mappings": {"properties": {"name":{"type": "text","fields": {"keyword" :{"type":"keyword"},"age":{"type":"integer"}}}}}}POST test-100/_doc{"age": 11}GET test-100/_search
Copy_to
概念定义:
字段数据来源去其他字段,在原数据中不存储
应用领域:
多字段同时组合检索,节约组合字段空间资源
PUT my_index{"mappings": {"properties": {"first_name": {"type": "text","copy_to": "full_name"},"last_name": {"type": "text","copy_to": "full_name"},"full_name": {"type": "text"}}}}PUT my_index/_doc/1{"first_name": "John","last_name": "Smith"}PUT my_index/_doc/2{"first_name": "Tom","last_name": "Cruise"}GET my_index/_search{"query": {"match": {"full_name": {"query": "John Smith","operator": "and"}}}}
地理与多边形图形类型应用
geo_point:地理位置
概念介绍:
- 基于经纬度坐标,应用与地址位置检索领域
- 基于geohash算法
geo_shape:地理图形
概念定义
- 基于地理位置坐标点,扩展了地理位置多边形区域搜索类型,基于球体模型设计检索
- 默认quadtree四叉树算法,可以选择geohash

特殊行业字段类型应用
ip网络地址

runtime运行时字段类型应用
概念定义:
- 查询运行时,字段才会计算实际值;
- 比占用source,不占用磁盘
- 一般使用脚本方式,需要计算,性能与便利需要平衡
- 创建复杂表达式,使用的是painless脚本
使用方式:
- 索引创建mapping时定义,查询时使用
- 查询时定义,查询时使用
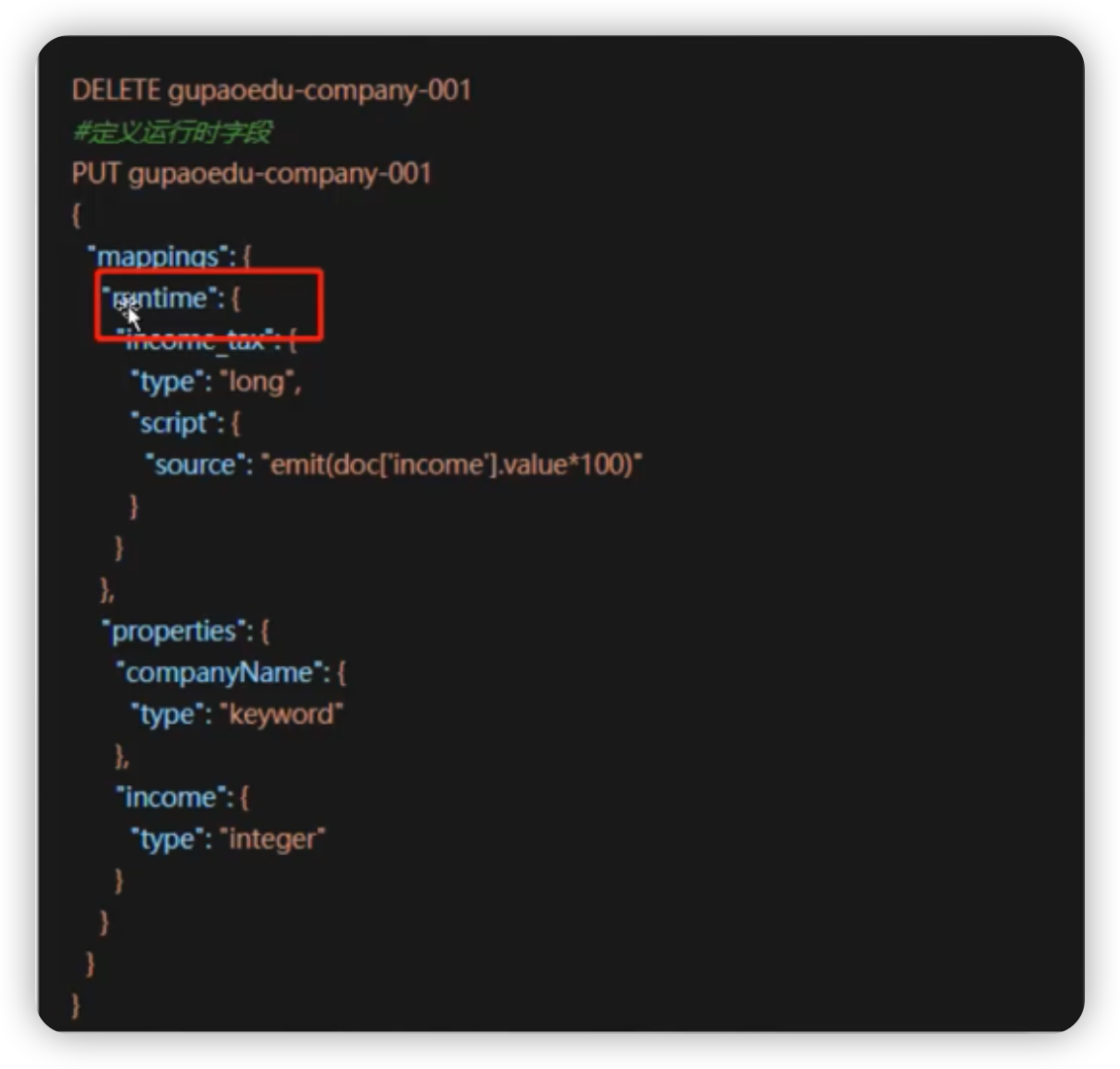
Mapper字段源码解读

若有收获,就点个赞吧
0 人点赞
