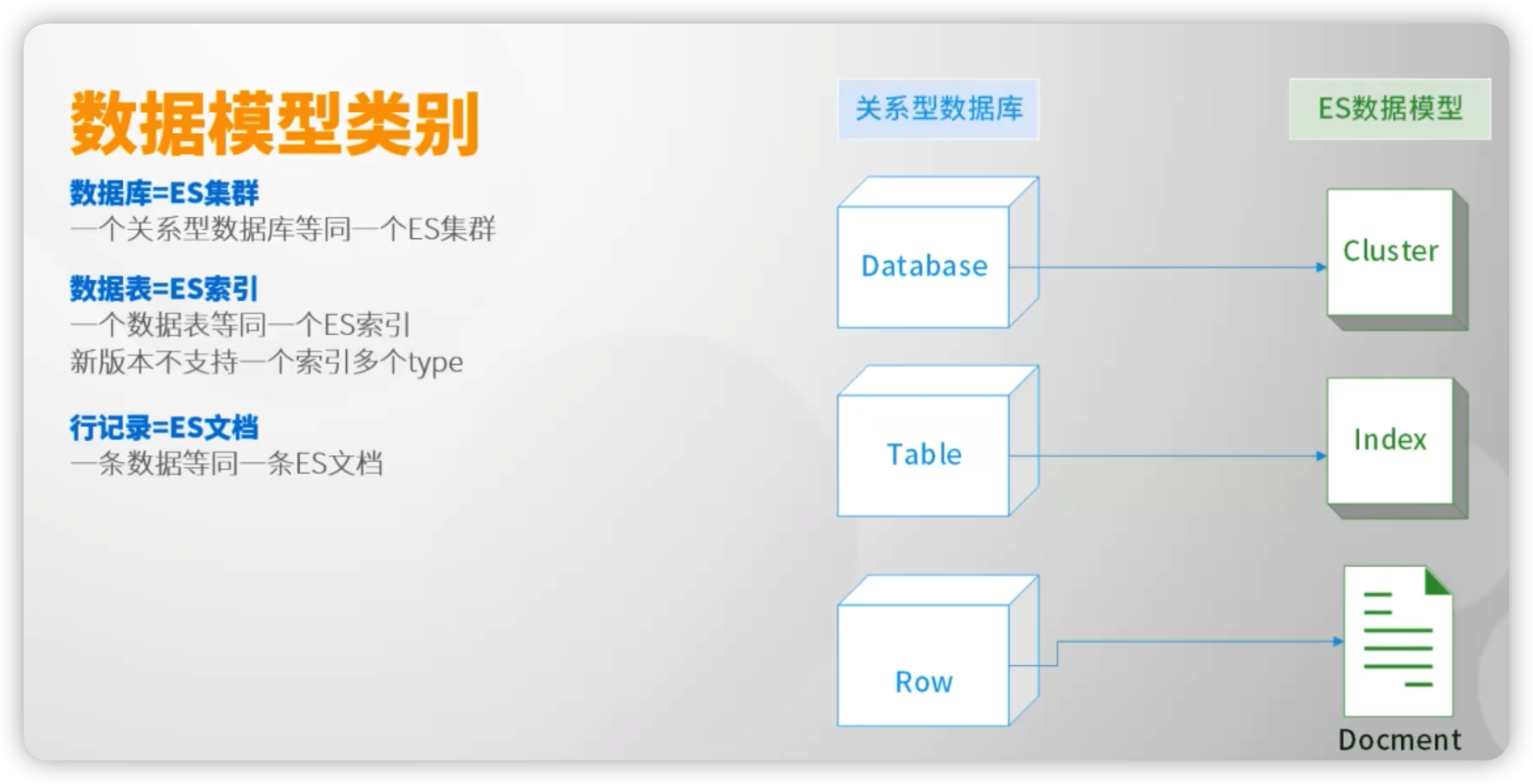
索引概念
index索引是个虚拟空间,类型数据库中的table
一个索引由至少1个分片组成
一个索引由可以由住分片与副本分片组成;
索引别名用途

索引命名
命名重要性
命名规范建议
应用意义

创建索引
动态创建:
- 概念定义:
索引无需提前创建,第一条数据插入即可创建完成;
- 应用场景:
非严格数据模型限制规范的场景,日志,监控
- 索引膜拜:
通常采用索引膜拜固定下来
- 可限制自动机制:

静态创建:
- 概念定义:
依据客观背景提前创建好索引,提前做好索引数据分布与相应设置;
- 应用场景:
业务系统数据需要严格规范;
索引分布在极端情况下需要消化集群资源,避免集中创建索引史,集群相应慢;
滚动创建/自动创建
- rollover特性:
1.利用别名alias
2.利用rollover特性
3.自动化滚动创建,达到一定阀值创建
- 应用场景:
1.日志领域,需要自动化依据触发条件滚动创建
2.大数据领域,单索引能力局限需要创建很多
3.索引和别名是多对多关系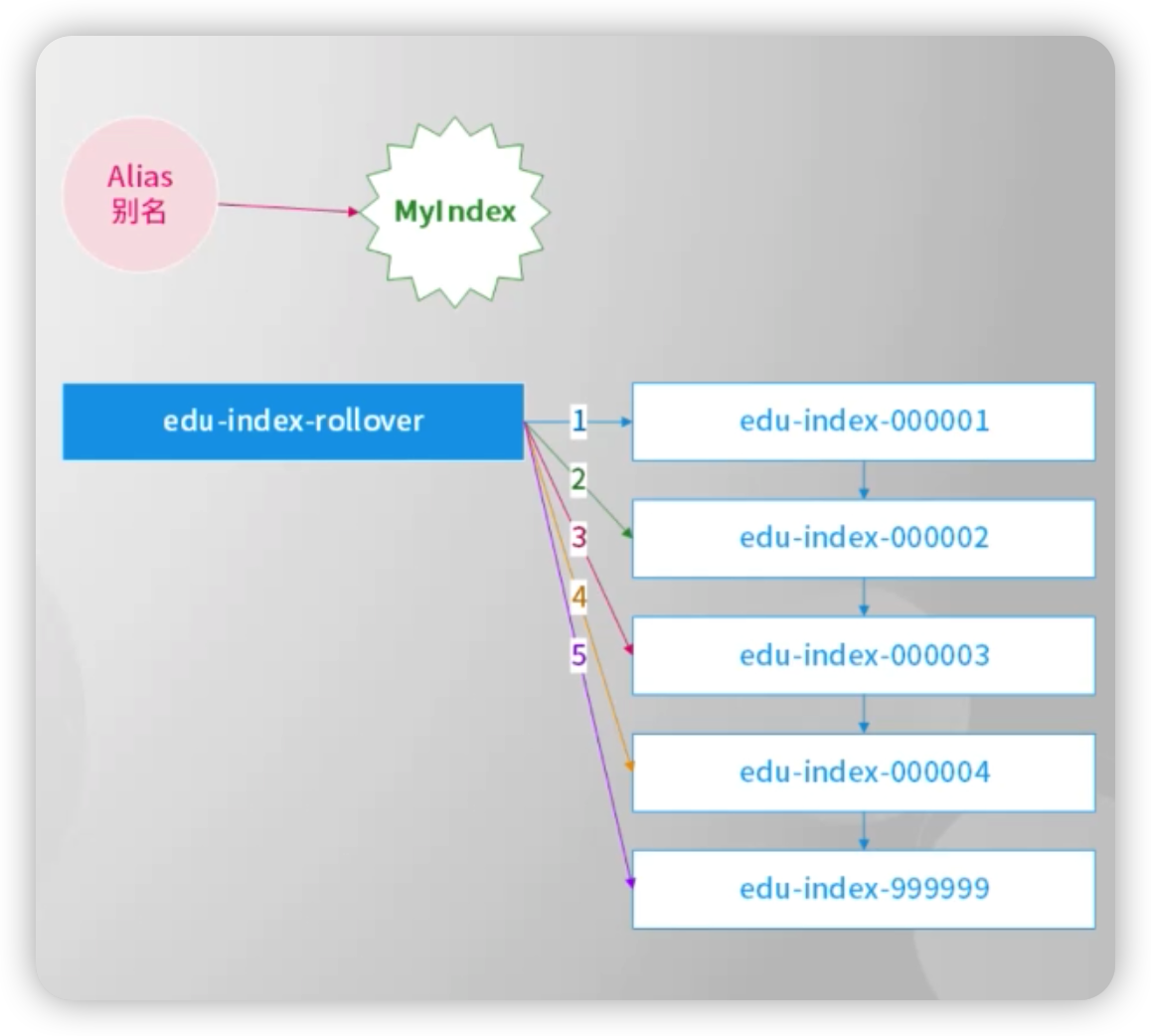
#第一种创建别名PUT /test-004/_alias/test-alias02#第二种创建别名PUT /test-003{"aliases": {"test-alias": {}}}##查询别名数据:GET test-alias##查询所有别名GET /_cat/aliases
滚动索引创建命名规范
- 滚动索引创建命名规范
- 索引命名规范,必须符合自动增长模式
- 建议后缀是标准数字
- 索引名称中不要有特殊符号

- 手动创建滚动索引,别名自动关联到最新索引上
```shell
手动模式
PUT /test-rollover-index-000001 { “aliases”: { “test-rollover-index”: {} } }查询索引情况
GET test-rollover-index
手动触发滚动创建索引
POST test-rollover-index/_rollover
- 滚动索引创建触发条件1. 索引最大文档数1. 索引创建时间1. 索引最大大小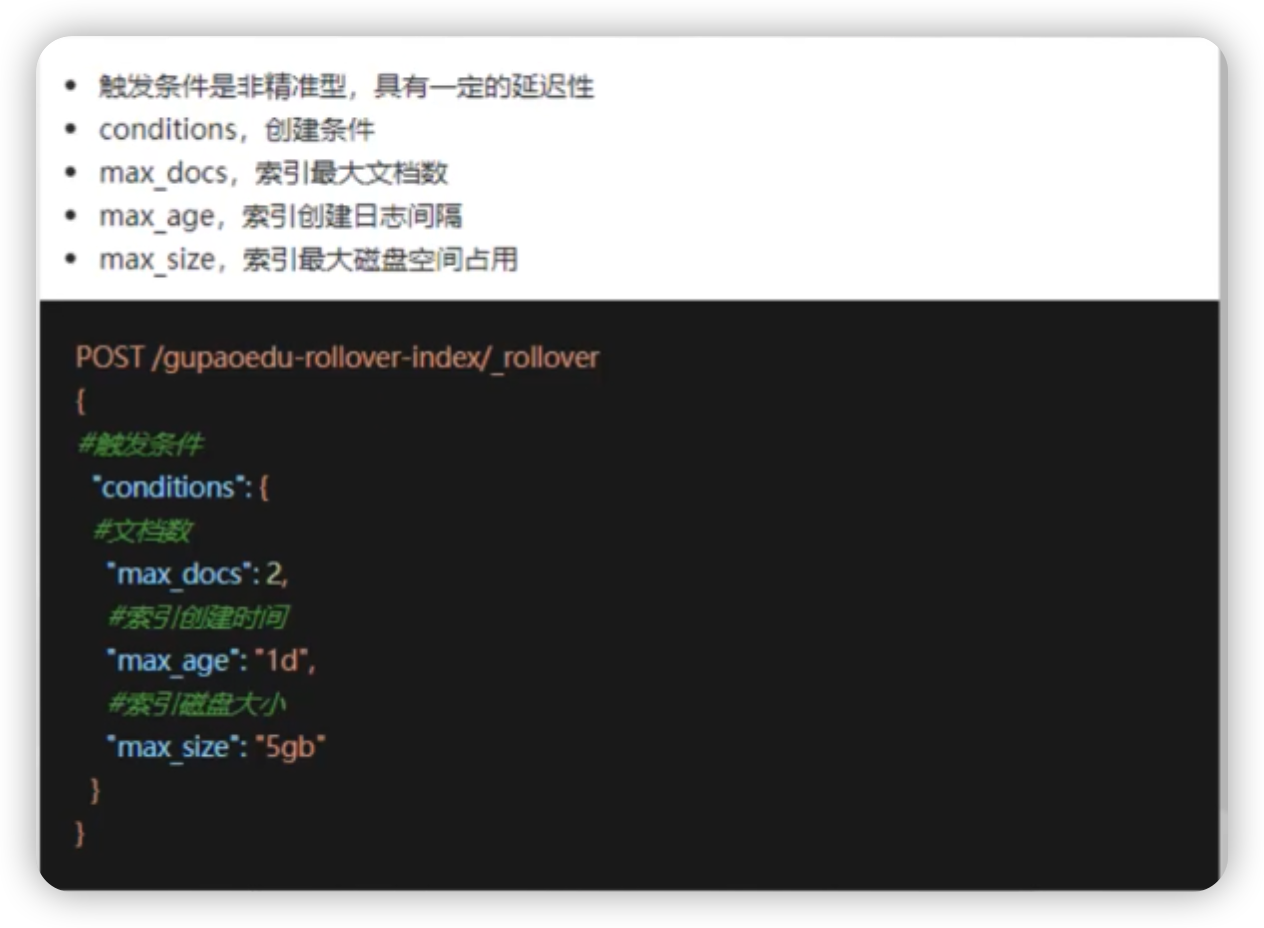```shell## 手动触发滚动创建索引--设置文档数插入2条后,创建新的索引POST test-rollover-index/_rollover{"conditions": {"max_docs": 2}}
索引设置-静态设置
索引分片
默认1,创建索引时需要指定,之后索引活动期不可变,后期只能重建
索引字段类型
字段类型不可变,一旦指定几乎不可变,若要修改,则需要刷新所有历史数据,等同与索引重建
设置索引分片及副本分片和字段类型;

索引设置-动态设置
索引副本
其他索引设置
索引有很多高级设置,可以动态修改

索引文档数据模型
平铺型:
- 概念介绍
Json结构平铺
- 优点:
简单,效率
- 缺点:
简单
- 应用场景:

对象型:
- 概念介绍:
Json对象嵌套
- 优点:
表达能力
- 缺点:
复杂,效率,维护
- 应用场景:

数组类型:
- 概念介绍:
Json数组对象
- 优点:
表达能力
- 缺点:
效率,维护
- 应用场景

关联类型:
- 关联类型
父子关系:join字段类型
键值对关系:nested字段类型
- 优点:
表达能力
- 缺点:
效率,复杂,维护
- 应用场景:

索引设计经验建议:
索引与分片与副本关系:
- 分片数量:
索引分片数量不超过节点数量
1个索引40个分片等同于40个1分片索引
- 副本数量:
分片容量:
数据容量:
分片数据容量上限不超过50GB,建议30GB-30GB
数据条数:
单分片不超过2的32次方-1(21亿条)
数据模型设计原则
- 简单模型原则
能用平铺模型搞定,尽量平铺
对象深度建议不要超过2级
- 最细粒度原则
对像嵌套遵循最细粒度原则,上曾数据冗余处理
- 多索引原则
单一索引尽量满足单一业务场景
不同业务场景索引即使数据模型相似也要分开
- 大宽表索引原则
特殊场景合并多个表时,尽量全部合并在一起
ES不支持join,大宽表可解决查询问题
某物流派单项目:
- 模型介绍:
多个DB表
一个索引
大宽表结构
- 背景场景:
查询场景,对象型
- 优点缺点:
通用查询能力,查询效率

若有收获,就点个赞吧
0 人点赞
