任务背景
实现了远程的存储共享(NAS或SAN)后, 公司业务发展迅速, 存储空间还需要增大。使用NAS或SAN都不方便扩容,NAS可以增加新的挂载目录, SAN可以增加新的硬盘,但我们希望直接在原来挂载的业务目录上实现在线扩容,数据体量越来越大, 这个时候我们就可以考虑使用分布式存储了。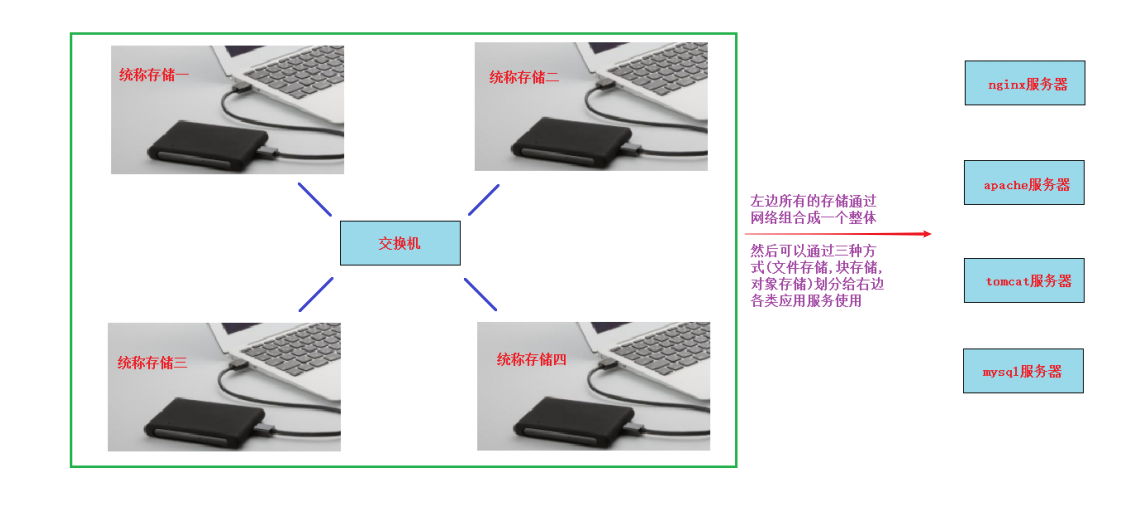
任务要求
1, 将远程多台服务器的空闲存储空间整合,组合成一个大存储给应用服务器(如apache,nginx,tomcat,mysql等)使用
2, 考虑高可用与负载均衡原则,并能实现在线扩容
任务拆解
1, 了解分布式存储的概念与原理
2, 选择对应的分布式存储软件
3, 准备多台有空闲空间的服务器做存储服务器
4, 搭建集群将多台存储服务器组合
5, 将组合的大存储划分成卷共享给应用服务器使用
6, 实现在线扩容
学习目标
- 能够说出分布式存储的优点
- 能够成功搭建glusterfs集群
- 掌握常见的glusterfs卷模式的创建与使用
- 能够对特定的glusterfs卷实现在线裁减或扩容
分布式存储介绍
我们已经学习了NAS是远程通过网络共享目录, SAN是远程通过网络共享块设备。
那么分布式存储你可以看作拥有多台存储服务器连接起来的存储导出端。把这多台存储服务器的存储合起来做成一个整体再通过网络进行远程共享,共享的方式有目录(文件存储),块设备(块存储),对象网关或者说一个程序接口(对象存储)。
常见的分布式存储开源软件有:GlusterFS,Ceph,HDFS,MooseFS,FastDFS等。
分布式存储一般都有以下几个优点:
- 扩容方便,轻松达到PB级别或以上
- 提升读写性能(LB)或数据高可用(HA)
- 避免单个节点故障导致整个架构问题
- 价格相对便宜,大量的廉价设备就可以组成,比光纤SAN这种便宜很多
储存容量计算单位 1B (byte 字节); 1KB(Kilobyte 千字节) = 2^10 B = 1024 B; 1MB(Megabyte 兆字bai节) = 2^10 KB = 1024 KB = 2^20 B; 1GB(Gigabyte 吉字节) = 2^10 MB = 1024 MB = 2^30 B; 1TB(Trillionbyte 太字节) = 2^10 GB = 1024 GB = 2^40 B; 1PB(Petabyte 拍字节) = 2^10 TB = 1024 TB = 2^50 B; 1EB(Exabyte 艾字节) = 2^10 PB = 1024 PB = 2^60 B; 1ZB(Zettabyte 泽字节) = 2^10 EB = 1024 EB = 2^70 B; 1YB(YottaByte 尧字节) = 2^10 ZB = 1024 ZB = 2^80 B; 1BB(Brontobyte ) = 2^10 YB = 1024 YB = 2^90 B; 1NB(NonaByte ) = 2^10 BB = 1024 BB = 2^100 B; 1DB(DoggaByte) = 2^10 NB = 1024 NB = 2^110 B;
Glusterfs
一、glusterfs介绍
glusterfs是一个免费,开源的分布式文件系统(它属于文件存储类型)。具有强大的横向扩展能力,通过扩展能够支持数PB存储容量和处理数千客户端
文档:https://docs.gluster.org/en/latest/Install-Guide/Overview/
Glusterfs特点
- 扩展性和高性能
- 高可用性
- 弹性卷管理
缺点:- 扩容、缩容时影响的服务器较多
- 遍历目录下文件耗时
- 小文件性能较差
几个概念:
- Brick [brɪk] 存储块: GlusterFS 的基本单元,以节点服务器目录形式出现
- Volume [ˈvɒljuːm] 卷 :多个bricks的逻辑集合
- Metadata [ˈmetədeɪtə] 元数据,用于描述文件目录等信息
- Self-heal 用于后台运行监测副本卷中文件和目录的不一致性,并解决这些不一致性
- FUSE filesystem userspace 是一个可加载的内核模块,其支持非特权用户创建自己的文件系统,而不需要修改内核代码。通过在用户空间运行文件系统的代码,通过FUSE代码和内核桥接
- GlusterFS Server: 数据存储服务器,即组成GlusterFS存储集群的节点
- Gluster Client 使用GlusterFS存储服务器的服务器,例如KVM、OpenStack、LBRealServer、HAnode
扩展阅读
glusterfs分布式文件系统详细原理:https://blog.csdn.net/yujin2010good/article/details/75268877
GlusterFS 存储结构原理介绍:https://blog.51cto.com/wzlinux/1949441
https://www.cnblogs.com/linyaonie/p/11238097.html
https://www.cnblogs.com/huangyanqi/p/8406534.html
二、raid级别回顾(拓展)
RAID技术 :https://blog.csdn.net/ensp1/article/details/81318135
raid:廉价的磁盘冗余阵列,独立磁盘冗余阵列,RAID 是由多个独立的高性能磁盘驱动器组成的磁盘子系统,从而提供比单个磁盘更高的存储性能和数据冗余的技术
raid级别有很多种,下面主要介绍常用的几种:
raid0 : 读写性能佳,坏了其中一块,数据挂掉,可靠性低(stripe条带化),磁盘利用率100%,它不提供数据冗余保护,一旦数据损坏,将无法恢复
RAID0 是一种简单的、无数据校验的数据条带化技术。实际上不是一种真正的 RAID ,因为它并不提供任何形式的冗余策略。 RAID0 将所在磁盘条带化后组成大容量的存储空间(如图 所示),将数据分散存储在所有磁盘中,以独立访问方式实现多块磁盘的并读访问

raid1 镜像备份(mirror),同一份数据完整的保存在多个磁盘上,写的性能不佳,可靠性高,读的性能还行,磁盘利用率50%

raid10 先做raid 1 再做raid 0 读写的速度都快,磁盘利用率50%
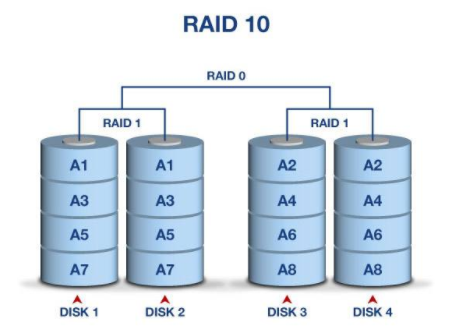
raid5 由至少三块磁盘做raid 5,磁盘利用率为n-1/n, 其中一块放校验数据,允许坏一块盘,数据可以利用校验值来恢复
比如三块磁盘都写,有2个磁盘写,一个做校验

raid6 在raid5的基础上再加一块校验盘,共两块盘做校验,进一步提高数据可靠性,最少四块磁盘

生产环境中最常用的为raid5和raid10
三、常见卷的模式

| 卷模式 | 描述 |
|---|---|
| Replicated | 复制卷,类似raid1,浪费空间 |
| Striped(了解,新版本将会放弃此模式及其它相关的组合模式) | 条带卷,类似raid0,可靠性低 |
| Distributed | 分布卷 |
| Distribute Replicated | 分布与复制组合,类似RAID10 |
| Dispersed | 纠删卷,类似raid5,raid6 |
glusterfs看作是一个将多台服务器存储空间组合到一起,再划分出不同类型的文件存储卷给导入端使用。
Replicated卷

Striped卷

Distributed卷

Distribute Replicated卷

此类型卷是基本复本卷的扩展,可以指定若干brick组成一个复本卷,另外若干brick组成另个复本卷。单个文件在复本卷内数据保持复制,不同文件在不同复本卷之间进行分布
其它模式请参考官网: https://docs.gluster.org/en/latest/Administrator Guide/Setting Up Volumes/
四、glusterfs集群搭建
https://blog.csdn.net/goser329/article/details/78569257
安装GlusterFS-快速启动指南:
https://docs.gluster.org/en/latest/Quick-Start-Guide/Quickstart/#purpose-of-this-document
1.实验准备:
| 操作系统 | IP | 主机名 | 硬盘数量(三块) |
|---|---|---|---|
| centos 7.6 | 192.168.216.129 | node1 | sdb:10G sdc:10G sdd:10G |
| centos 7.6 | 192.168.216.128 | node2 | sdb:10G sdc:10G sdd:10G |
| centos 7.6 | 192.168.216.130 | node3 | sdb:10G sdc:10G sdd:10G |
| centos 7.6 | 192.168.216.131 | node4 | sdb:10G sdc:10G sdd:10G |
| centos 7.6 | 192.168.216.132 | client | sda:20G |
1.所有节点(包括client)静态IP(NAT网络,能上外网)
2.所有节点(包括client)都配置主机名及其主机名互相绑定(这次我这里做了别名,方便使用)
# vim /etc/hosts192.168.216.129 node1192.168.216.128 node2192.168.216.130 node3192.168.216.131 node4192.168.216.132 client
3.所有节点(包括client)关闭防火墙,selinux
# systemctl stop firewalld
# systemctl disable firewalld
# firewall-cmd --state
# sestatus
SELinux status: disabled
# getenforce
Disabled
# iptables -F
4.所有节点(包括client)时间同步
所有主机
#crontab -e
0 */1 * * * ntpdate time1.aliyun.com
5.所有节点(包括client)配置好yum(需要加上glusterfs官方yum源)
# vim /etc/yum.repos.d/glusterfs.repo
[glusterfs]
name=glusterfs
baseurl=https://buildlogs.centos.org/centos/7/storage/x86_64/gluster-4.1/
enabled=1
gpgcheck=0
#yum repolist
yum源说明:
- 可按照以上yum路径去查找
glusterfs5或glusterfs6版本的yum源路径(目前我们使用4.1版) - 如果网速太慢,可下载我共享的软件做本地yum源安装
- 官方yum源:https://buildlogs.centos.org/centos/7/storage/x86_64/
6.准备存储磁盘(全部glusterfs主机)
- 查看磁盘
# lsblk
- 创建文件系统 ```powershell 格式化磁盘(全部glusterfs主机)
格式化使用整个磁盘不用分区
nodex# mkfs.xfs /dev/sdb
nodex# mkfs.xfs /dev/sdc
nodex# mkfs.xfs /dev/sdd
- 挂载文件系统
```powershell
glusterfs主机上创建挂载块设备的目录,挂载硬盘到目录
对应三个磁盘创建三个文件夹
nodex# mkdir g{b..d} 挂载的目录
nodex# ls
gb gc gd
nodex# vim /etc/fstab
/dev/sdb /gb xfs defaults 0 0
/dev/sdc /gc xfs defaults 0 0
/dev/sdd /gd xfs defaults 0 0
或
nodex# echo '/dev/sdb /gb xfs defaults 0 0' >> /etc/fstab
nodex# echo '/dev/sdc /gc xfs defaults 0 0' >> /etc/fstab
nodex# echo '/dev/sdd /gd xfs defaults 0 0' >> /etc/fstab
启动所有/etc/fstab中的设备挂载,
nodex# mount -a
nodex# df -hT
再次提示以上操作在所有的存储服务器都进行一样的配置 node 1 2 3 4
2.实验步骤:
- 在所有storage服务器上安装相关软件包,并启动服务
- 所有storage服务器建立连接, 成为一个集群
- 所有storage服务器准备存储目录
- 创建存储卷
- 启动存储卷
- client安装挂载软件
- client挂载使用
3.实验过程:
第1步, 在所有storage服务器上(不包括client)安装glusterfs-server软件包,并启动服务
下面的命令所有存储服务器都要做
# yum install glusterfs-server
# glusterfs -V
# systemctl start glusterd
# systemctl enable glusterd
# systemctl status glusterd
分布式集群一般有两种架构:
- 有中心节点的 中心节点一般指管理节点,后面大部分分布式集群架构都属于这一种
- 无中心节点的 所有节点又管理又做事,glusterfs属于这一种
第2步, 所有storage服务器建立连接,成为一个集群
将分布式存储主机加入到信任主机池并查看加入的主机状态
查看主机池中主机的状态
# gluster peer status
4个storage服务器建立连接不用两两连接,只需要找其中1个,连接另外3个各一次就OK了(随便一台服务器都可以,不用都做)
下面我就在storage1上操作
node1# gluster peer probe node2
node1# gluster peer probe node3
node1# gluster peer probe node4 --这里使用ip,主机名,主机名别名都可以
然后在所有storage服务器上都可以使用下面命令来验证检查主机池中主机的状态
# gluster peer status
注意:一旦建立了这个池,只有受信任的成员可能会将新的服务器探测到池中。新服务器无法探测池,必须从池中探测。
注意:
如果这一步建立连接有问题(一般问题会出现在网络连接,防火墙,selinux,主机名绑定等);
如果想重做这一步,可以使用gluster peer detach xxxxx [force]来断开连接,重新做
第3步, 所有storage服务器准备存储目录(可以用单独的分区,也可以使用根分区,还可以是整个硬盘)
整个硬盘
在/gd 下创建存储目录
# mkdir -p /gd/rgv0 /gd/rgv0 === /data/gv0
第4步, 创建存储卷(在任意一个storage服务器上做)
GlusterFS 五种卷
- Distributed:分布式卷,文件通过 hash 算法随机分布到由 bricks 组成的卷上。
- Replicated: 复制式卷,类似 RAID 1,replica 数必须等于 volume 中 brick 所包含的存储服务器数,可用性高。
- Striped: 条带式卷,类似 RAID 0,stripe 数必须等于 volume 中 brick 所包含的存储服务器数,文件被分成数据块,以 Round Robin 的方式存储在 bricks 中,并发粒度是数据块,大文件性能好。
- Distributed Striped: 分布式的条带卷,volume中 brick 所包含的存储服务器数必须是 stripe 的倍数(>=2倍),兼顾分布式和条带式的功能。
- Distributed Replicated: 分布式的复制卷,volume 中 brick 所包含的存储服务器数必须是 replica 的倍数(>=2倍),兼顾分布式和复制式的功能。
分布式复制卷的brick顺序决定了文件分布的位置,一般来说,先是两个brick形成一个复制关系,然后两个复制关系形成分布。
企业一般用后两种,大部分会用分布式复制(可用容量为 总容量/复制份数),通过网络传输的话最好用万兆交换机,万兆网卡来做。这样就会优化一部分性能。它们的数据都是通过网络来传输的。
注意: 改变的操作(create,delete,start,stop)等只需要在任意一个storage服务器上操作,查看的操作(info)等可以在所有storage服务器上操作
Setting up GlusterFS Volumes:
https://docs.gluster.org/en/latest/Administrator-Guide/Setting-Up-Volumes/
任意一个storage服务器上操作
下面命令我是在node1上操作的
replica 4表示是在4台上做复制模式(类似raid1)
replica 数必须等于 volume 中 brick 所包含的存储服务器数
glusterfs 中卷volume的大小取决于砖Brick的数量
创建卷类型为replica的存储rgv0_volume卷,卷volume有四块砖Brick组成,分别为。。。。
node1# gluster volume create rgv0_volume replica 4 node1:/gd/rgv0 node2:/gd/rgv0 node3:/gd/rgv0 node4:/gd/rgv0
所有storage服务器上都可以查看
# gluster volume info rgv0_volume
Volume Name: rgv0_volume
Type: Replicate 模式为replicate模式
Volume ID: 328d3d55-4506-4c45-a38f-f8748bdf1da6
Status: Created 这里状态为created,表示刚创建,还未启动,需要启动才能使用
Snapshot Count: 0
Number of Bricks: 1 x 4 = 4
Transport-type: tcp
Bricks:
Brick1: node1:/gd/rgv0
Brick2: node2:/gd/rgv0
Brick3: node3:/gd/rgv0
Brick4: node4:/gd/rgv0
Options Reconfigured:
transport.address-family: inet
nfs.disable: on
第5步, 启动存储卷
查看创建卷的状态
所有storage服务器上都可以查看
node1# gluster volume status rgv0_volume
node1# gluster volume start rgv0_volume
node1# gluster volume info rgv0_volume
Volume Name: rgv0_volume
Type: Replicate
Volume ID: 328d3d55-4506-4c45-a38f-f8748bdf1da6
Status: Started 现在看到状态变为started,那么就表示可以被客户端挂载使用了
Snapshot Count: 0
Number of Bricks: 1 x 4 = 4
Transport-type: tcp
Bricks:
Brick1: node1:/gd/rgv0
Brick2: node2:/gd/rgv0
Brick3: node3:/gd/rgv0
Brick4: node4:/gd/rgv0
Options Reconfigured:
transport.address-family: inet
nfs.disable: on
node1# gluster volume status rgv0_volume
第6步, client安装软件
客户端上操作
client# yum install glusterfs glusterfs-fuse -y
说明:
fuse(Filesystem in Userspace): 用户空间文件系统,是一个客户端挂载远程文件存储的模块
第7步, client挂载使用
注意:客户端也需要在/etc/hosts文件里绑定存储节点的主机名,才可以挂载(因为我前面做的步骤是用名字的)
client# mkdir /test0
client# mount -t glusterfs node1:rgv0_volume /test0
这里client是挂载node1,也可以挂载node2,node3,node4任意一个。(也就是说这4个node既是老板,又是员工。这是glusterfs的一个特点,其它的分布式存储软件基本上都会有专门的管理server)
client# df -h
文件系统 容量 已用 可用 已用% 挂载点
node1:rgv0_volume 10.0G 133M 9.9G 2% /test0 #容量是总容量的一半
总共有四个数据块Brick,每一块Brick 10G, 总共有40G,由于是复制卷,要存4分,所以可用空间是10G
client# umount /test0
client# mount -t glusterfs node2:rgv0_volume /test0
client# df -h
文件系统 容量 已用 可用 已用% 挂载点
node2:rgv0_volume 10.0G 133M 9.9G 2% /test0 #容量是总容量的一半
第8步,使用glusterfs 中的卷
client# cp /etc/passwd /test0
client# ls /test0
passwd
在存储服务上查看
nodex# ls /gd/rgv0
passwd
#创建文件的实际存在位置为node1和node2上的/gd/rgv0目录下,因为是复制卷,这四个目录下的内容是完全一致的。
4.replica复制卷测试(类似raid 1)
读写测试方法:
在客户端使用dd命令往挂载目录里写文件,然后查看在storage服务器上的分布情况(具体验证详细过程参考授课视频)
(注意: 读写操作请都在客户端进行,不要在storage服务器上操作)
client# dd if=/dev/zero of=/test0/file1 bs=1M count=100
- 读写测试结果: 结果类似raid1
- 同读同写测试: 有条件的可以再开一台虚拟机做为client2,两个客户端挂载gv0后实现同读同写(文件存储类型的特点)
运维思想:
搭建OK后,你要考虑性能,稳定, 高可用,负载均衡,健康检查, 扩展性等
如果某一个节点挂了,你要考虑是什么挂了(网卡,服务,进程,服务器关闭了),如何解决?
请测试如下几种情况:
- 将其中一个storage节点关机
客户端需要等待10几秒钟才能正常继续使用,再次启动数据就正常同步过去
- 将其中一个storage节点网卡down掉
客户端需要等待10几秒钟才能正常继续使用,再次启动数据就正常同步过去
- 将其中一个storage节点glusterfs相关的进程kill掉
客户端无需等待就能正常继续使用,但写数据不会同步到挂掉的storage节点,等它进程再次启动就可以同步过去了
结论: 作为一名运维工程师,HA场景有不同的挂法:
- 服务器关闭
- 网卡坏了
- 网线断了
- 交换机挂了
- 服务进程被误杀等等
但我们需要去考虑,当软件无法把我们全自动实现时,我们可能需要使用脚本来辅助。有一个简单的方法为: 如果一个节点没死透,我们就干脆将它关机,让它死透
请参考拓展: RHCS,pacemaker里的fence,stonish(shoot the other node in the head)等概念。
5.卷的删除
一般会用在命名不规范的时候才会删除
删除卷中的文件的话,如果是在客户端只需要删除一次就可以,如果是在服务器端的话就需要删除4次
第1步: 先在客户端umount已经挂载的目录(在umount之前把测试的数据先删除)
client# rm /test0/* -rf
client# umount /test0
client# df -h
第2步: 在任一个storage服务器上使用下面的命令停止rgv0_volume并删除,我这里是在node1上操作
node1# gluster volume stop rgv0_volume
Stopping volume will make its data inaccessible. Do you want to continue? (y/n) y
volume stop: gv0: success
node1# gluster volume delete rgv0_volume
Deleting volume will erase all information about the volume. Do you want to continue? (y/n) y
volume delete: gv0: success
第3步: 在所有storage服务器上都可以查看,没有rgv0_volume的信息了,说明这个volumn被删除了
# gluster volume info rgv0_volume
Volume gv0 does not exist
问题: 我在不删除rgv0_volume的情况下,能否再创建一个叫rgv1_volume的卷?
当然可以,换个目录再创建就OK
模拟误删除卷信息故障及解决办法
GlusterFS将其动态生成的配置文件存储在
/var/lib/glusterd,如果GlusterFS在任何时候都无法写入这些文件(例如,当备份文件系统已满时),它至少会导致系统的异常行为;或者更糟糕的是,使您的系统完全脱机。建议为目录创建单独的分区,例如/var/log以减少这种情况发生的可能性。
[root@node01 ~]# gluster volume stop gv1
[root@node01 ~]# gluster volume delete gv
[root@node01 ~]# ls /var/lib/glusterd/vols/
gv2 gv3
[root@node01 ~]# rm -rf /var/lib/glusterd/vols/gv3 #删除卷gv3的卷信息
[root@node01 ~]# ls /var/lib/glusterd/vols/ #再查看卷信息情况如下:gv3卷信息被删除了
gv2
[root@node01 ~]# gluster volume sync node02 #因为其他节点服务器上的卷信息是完整的,比如从node02上同步所有卷信息如下:
Sync volume may make data inaccessible while the sync is in progress. Do you want to continue? (y/n) y
volume sync: success
[root@node01 ~]# ls /var/lib/glusterd/vols/ #验证卷信息是否同步过来
gv2 gv3
6.stripe模式(条带)(类似raid 0)
适合大文件但是不安全 数据会丢失,不建议 ,
第1步: 再重做成stripe模式的卷(重点是命令里的stripe 4参数)(在任一个storage服务器上操作, 我这里是在storage1上操作)
创建数据块brick(一个目录就相当于一个数据块brick)
node1# mkdir /gc/sgv0
node1# gluster volume create gv0 stripe 4 node1:/gc/sgv0 node2:/gc/sgv0 node3:/gc/sgv0 node4:/gc/sgv0 force
volume create: gv0: success: please start the volume to access data
第2步: 启动gv0(在任一个storage服务器上操作, 我这里是在node1上操作)
node1# gluster volume start gv0
node1# gluster volume status gv0
第3步: 客户端挂载
client# mount -t glusterfs node1:gv0 /test0
挂载任意一台node主机都可以
client# df -h
文件系统 容量 已用 可用 已用% 挂载点
node1:gv0 40.0G 540M 40G 4% /test0
第4步:读写测试
client# dd if=/dev/zero of=/test0/file1 bs=1M count=100
client# ll /test0/file1 -h
#文件的实际存放位置
node1# ll -h /gc/sgv0/file1
node2# ll -h /gc/sgv0/file1
node3# ll -h /gc/sgv0/file1
node4# ll -h /gc/sgv0/file1
可以看到/test0/file1 被分成了四份,每份大小为25M
node 任意主机数据丢失,数据就全丢失了
nodex# rm -rf /gc/sgv0/file1
client# ls /test0/file1
读写测试结果: 文件过小,不会平均分配给存储节点。有一定大小的文件会平均分配。类似raid0。
- 磁盘利率率100%(前提是所有节点提供的空间一样大,如果大小不一样,则按小的来进行条带)
- 大文件会平均分配给存储节点(LB)
- 没有HA,挂掉一个存储节点,则全部数据丢失,此stripe存储卷则不可被客户端访问
- 写和读的速度快
- 上面配置的条带卷在生产环境是很少使用的,因为它会将文件破坏,比如一个图片,它会将图片一份一份地分别存到条带卷中的brick上。
7.distributed分布卷模式
第1步: 准备新的存储目录(所有存储服务器上都要操作)
# mkdir -p /gd/dv0
第2步: 创建distributed卷gv1(不指定replica或stripe就默认是Distributed的模式, 在任一个storage服务器上操作, 我这里是在node1上操作)
node1# gluster volume create gv1 node1:/gd/dv0 ndoe2:/gd/dv0 node3:/gd/dv0 node4:/gd/dv0
第3步: 启动gv1(在任一个storage服务器上操作, 我这里是在node1上操作)
node1# gluster volume info gv1
node1# gluster volume start gv1
第4步: 客户端挂载
client# mkdir /test1
client# mount -t glusterfs node1:gv1 /test1
client# df -h
node1:/gd/dv0 40G 640M 40G 2% /test1 #四个设备容量之和
第5步:读写测试(测试方法与replica模式一样)
client# cd /test1
client# touch {a..f} #创建测试文件
client# ll
node1# ll /gd/dv0
node2# ll /gd/dv0
node3# ll /gd/dv0
node4# ll /gd/dv0
#文件实际存在位置node1,node2,node3,node4上的/gd/dv0目录下,通过hash分别存到node1,node2,node3,node4上的分布式磁盘上
读写测试结果: 测试结果为随机写到不同的存储里,直到所有写满为止。
- 利用率100%
- 方便扩容
- 不保障的数据的安全性(挂掉一个节点,等待大概1分钟后,这个节点就剔除了,被剔除的节点上的数据丢失)
- 也不提高IO性能
- 多个文件哈希算法随机存储到trick 上
8.distributed-replica分布复制卷模式
最少需要4台服务器才能创建,[生产场景推荐使用此种方式]
第1步: 准备新的存储目录(所有存储服务器上都要操作)
# mkdir -p /data/gv2
第2步: 创建distributed-replica卷gv2(在任一个storage服务器上操作, 我这里是在node1上操作)
storage1# gluster volume create gv2 replica 2 storage1:/data/gv2/ storage2:/data/gv2/ storage3:/data/gv2/ storage4:/data/gv2/ force
第3步: 启动gv2(在任一个storage服务器上操作, 我这里是在node1上操作)
storage1# gluster volume start gv2
第4步: 客户端挂载
client# mkdir /test2
client# mount -t glusterfs storage1:gv2 /test2
第5步:读写测试
读写测试结果: 4个存储分为两个组,这两个组按照distributed模式随机。但在组内的两个存储会按replica模式镜像复制。
特点:
- 结合了distributed与replica的优点:可以扩容,也有HA特性
9.dispersed分散卷模式
disperse [dɪˈspɜːrst] 卷是v3.6版本后发布的一种卷模式,类似于raid5/6
第1步: 准备新的存储目录(所有存储服务器上都要操作)
# mkdir -p /gb/dvg0
第2步: 创建卷gv3(在任一个storage服务器上操作, 我这里是在node1上操作)
node1# gluster volume create gv3 disperse 4 node1:/gb/dvg0 node2:/gb/dvg0 node3:/gb/dvg0 node4:/gb/dvg0
There is not an optimal redundancy value for this configuration. Do you want to create the volume with redundancy 1 ? (y/n) y
是否要创建冗余为1的卷?
volume create: gv3: success: please start the volume to access data
注意:没有指定冗余值,默认为1,按y确认
第3步: 启动gv3(在任一个storage服务器上操作, 我这里是在node1上操作)
node1# gluster volume start gv3
node1# gluster volume info gv3
Volume Name: gv3
Type: Disperse
Volume ID: 767add4e-48c4-4a2d-a5d1-467076d73afd
Status: Started
Snapshot Count: 0
Number of Bricks: 1 x (3 + 1) = 4 这里看到冗余数为1
Transport-type: tcp
Bricks:
Brick1: node1:/gb/dvg0
Brick2: node2:/gb/dvg0
Brick3: node3:/gb/dvg0
Brick4: node4:/gb/dvg0
Options Reconfigured:
transport.address-family: inet
nfs.disable: on
第4步: 客户端挂载
client# mkdir /test3
client# mount -t glusterfs node1:gv3 /test3
client# df -h
node1:gv3 30.0G 504M 30G 2% /test3 #容量是总容量的3/4 有一个做冗余
第5步:读写测试(测试方法与replica模式一样)
读写测试结果: 写100M,每个存储服务器上占33M左右。因为4个存储1个为冗余(与raid5一样)。
课后测试: 如果想要实现2个冗余,则最少需要5台存储服务器
# gluster volume create gv4 disperse 4 redundancy 2 storage1:/data/gv4/ storage2:/data/gv4/ storage3:/data/gv4/ storage4:/data/gv4/ force
redundancy must be less than 2 for a disperse 4 volume
这里指定disperse 4 redundancy 2参数,但报错为冗余值必须要比disperse值少2以上
优点:在冗余和磁盘空间上取得平衡
缺点: 要求消耗额外的资源进行验证,对性能有一定的影响
应用场景: 对冗余和磁盘空间都敏感的场景
创建4个trick 冗余的分散数,最多允许一个trick 故障而不丢失数据
分散卷需要需要制定冗余Brick数量,冗余数量小于Brick 数量。例如创建一个4个brick冗余的分散数,最多允许一个Brick故障而数据不丢失
删除任意个node上面的brick
node1# rm -rf /gb/dvg0
client# ls /test3 数据还在
3 + 1 有一块是做冗余的
五、在线裁减与在线扩容
在线裁减要看是哪一种模式的卷,比如stripe模式就不允许在线裁减。下面我以distributed卷来做裁减与扩容
在线裁减(注意要remove没有数据的brick)
任一个storage服务器上操作, 我这里是在node1上操作
node1# gluster volume remove-brick gv1 node4:/gd/dv0 force
Removing brick(s) can result in data loss. Do you want to Continue? (y/n) y
volume remove-brick commit force: success
node1#ls /gd/dv0 下面的文件还在(卷里面的文件还在)
裁剪掉的那个brick 的数据就没了,再加回来又就有了
裁减任意个node上面的brick
client# ls /test1 丢失了裁剪的那个brick上的数据
在线扩容
# gluster volume add-brick gv1 node4:/data/gv1 force
volume add-brick: success
添加裁减掉的node上面的brick
client# ls /test1 数据又全部恢复
增加至50G
node# mdkir /gc/dv0
node# gluster volume add-brick gv1 node1:/gc/dv0 force
client# df -h
node1:/gd/dv0 50G 799M 50G 2% /test1 #四个设备容量之和
问题1: 4个存储节点想扩容为5个存储节点怎么做?
答案: 第5个存储服务器安装服务器软件包,启动服务,然后gluster peer probe node5加入集群
问题2: 一个卷里已经有4个brick,想在线扩容brick,怎么做?
只有distributed模式或带有distributed组合的模式才能在线扩容brick
六、在线裁减与扩容分布式复制卷
配置分布式复制卷
配置分布式复制卷
最少需要4台服务器才能创建,[生产场景推荐使用此种方式]
[root@node01 ~]# gluster volume stop gv2
[root@node01 ~]# gluster volume add-brick gv2 replica 2 node03:/data/brick1 node04:/data/brick1 force #添加brick到gv2中
volume add-brick: success
[root@node01 ~]# gluster volume start gv2
volume start: gv2: success
[root@node01 ~]# gluster volume info gv2
Volume Name: gv2
Type: Distributed-Replicate # 这里显示是分布式复制卷,是在 gv2 复制卷的基础上增加 2 块 brick 形成的
Volume ID: 9f33bd9a-7096-4749-8d91-1e6de3b50053
Status: Started
Snapshot Count: 0
Number of Bricks: 2 x 2 = 4
Transport-type: tcp
Bricks:
Brick1: node01:/data/brick2
Brick2: node02:/data/brick2
Brick3: node03:/data/brick1
Brick4: node04:/data/brick1
Options Reconfigured:
transport.address-family: inet
nfs.disable: on
performance.client-io-threads: off
注意:当你给分布式复制卷和分布式条带卷增加 bricks 时,你增加的 bricks 数目必须是复制或条带数目的倍数,
例如:你给一个分布式复制卷的 replica 为 2,你在增加 bricks 的时候数量必须为2、4、6、8等。
扩容后进行测试,发现文件都分布在扩容前的卷中。
在线裁减与扩容
[root@node01 ~]# gluster volume stop gv2
[root@node01 ~]# gluster volume remove-brick gv2 replica 2 node03:/data/brick1 node04:/data/brick1 force #强制移除brick块
[root@node01 ~]# gluster volume info gv2
Volume Name: gv2
Type: Replicate
Volume ID: 9f33bd9a-7096-4749-8d91-1e6de3b50053
Status: Stopped
Snapshot Count: 0
Number of Bricks: 1 x 2 = 2
Transport-type: tcp
Bricks:
Brick1: node01:/data/brick2
Brick2: node02:/data/brick2
Options Reconfigured:
transport.address-family: inet
nfs.disable: on
performance.client-io-threads: off# 如果误操作删除了后,其实文件还在 /storage/brick1 里面的,加回来就可以了
[root@node01 ~]# gluster volume add-brick gv2 replica 2 node03:/data/brick1 node04:/data/brick1 force
volume add-brick: success
[root@node01 ~]# gluster volume info gv2
Volume Name: gv2
Type: Distributed-Replicate
Volume ID: 9f33bd9a-7096-4749-8d91-1e6de3b50053
Status: Stopped
Snapshot Count: 0
Number of Bricks: 2 x 2 = 4
Transport-type: tcp
Bricks:
Brick1: node01:/data/brick2
Brick2: node02:/data/brick2
Brick3: node03:/data/brick1
Brick4: node04:/data/brick1
Options Reconfigured:
transport.address-family: inet
nfs.disable: on
performance.client-io-threads: off
分布式复制卷的最佳实践:
1)搭建条件
- 块服务器的数量必须是复制的倍数
- 将按块服务器的排列顺序指定相邻的块服务器成为彼此的复制
例如,8台服务器:
- 当复制副本为2时,按照服务器列表的顺序,服务器1和2作为一个复制,3和4作为一个复制,5和6作为一个复制,7和8作为一个复制
- 当复制副本为4时,按照服务器列表的顺序,服务器1/2/3/4作为一个复制,5/6/7/8作为一个复制
2)创建分布式复制卷
磁盘存储的平衡
平衡布局是很有必要的,因为布局结构是静态的,当新的 bricks 加入现有卷,新创建的文件会分布到旧的 bricks 中,所以需要平衡布局结构,使新加入的 bricks 生效。布局平衡只是使新布局生效,并不会在新的布局中移动老的数据,如果你想在新布局生效后,重新平衡卷中的数据,还需要对卷中的数据进行平衡。
#在gv2的分布式复制卷的挂载目录中创建测试文件入下
[root@node01 ~]# df -h
文件系统 容量 已用 可用 已用% 挂载点
127.0.0.1:/gv2 10G 65M 10G 1% /mnt
[root@node01 ~]# cd /mnt/
[root@node01 mnt]# touch {x..z}#新创建的文件只在老的brick中有,在新加入的brick中是没有的
[root@node01 mnt]# ls /data/brick2
1 2 3 4 5 6 x y z
[root@node02 ~]# ls /data/brick2
1 2 3 4 5 6 x y z
[root@node03 ~]# ll -h /data/brick1
总用量 0
[root@node04 ~]# ll -h /data/brick1
总用量 0
# 从上面可以看到,新创建的文件还是在之前的 bricks 中,并没有分布中新加的 bricks 中
# 下面进行磁盘存储平衡
[root@node01 ~]# gluster volume rebalance gv2 start
[root@node01 ~]# gluster volume rebalance gv2 status
#查看平衡存储状态# 查看磁盘存储平衡后文件在 bricks 中的分布情况
[root@node01 ~]# ls /data/brick2
1 5 y
[root@node02 ~]# ls /data/brick2
1 5 y
[root@node03 ~]# ls /data/brick1
2 3 4 6 x z
[root@node04 ~]# ls /data/brick1
2 3 4 6 x z
#从上面可以看出部分文件已经平衡到新加入的brick中了每做一次扩容后都需要做一次磁盘平衡。 磁盘平衡是在万不得已的情况下再做的,一般再创建一个卷就可以了。
glusterfs小结:
属于文件存储类型,优点:可以数据共享 缺点: 速度较低
七、glusterfs 其他
优化参数调整方式
命令格式:
gluster.volume set <卷><参数>
例如:
#打开预读方式访问存储
[root@node01 ~]# gluster volume set gv2 performance.read-ahead on
#调整读取缓存的大小
[root@mystorage gv2]# gluster volume set gv2 performance.cache-size 256M
监控及日常维护
使用zabbix自带的模板即可,CPU、内存、磁盘空间、主机运行时间、系统load。日常情况要查看服务器监控值,遇到报警要及时处理。
#看下节点有没有在线
gluster volume status nfsp
#启动完全修复
gluster volume heal gv2 full
#查看需要修复的文件
gluster volume heal gv2 info
#查看修复成功的文件
gluster volume heal gv2 info healed
#查看修复失败的文件
gluster volume heal gv2 heal-failed
#查看主机的状态
gluster peer status
#查看脑裂的文件
gluster volume heal gv2 info split-brain
#激活quota功能
gluster volume quota gv2 enable
#关闭quota功能
gulster volume quota gv2 disable
#目录限制(卷中文件夹的大小)
gluster volume quota limit-usage /data/30MB --/gv2/data
#quota信息列表
gluster volume quota gv2 list
#限制目录的quota信息
gluster volume quota gv2 list /data
#设置信息的超时时间
gluster volume set gv2 features.quota-timeout 5
#删除某个目录的quota设置
gluster volume quota gv2 remove /data
备注:quota功能,主要是对挂载点下的某个目录进行空间限额。如:/mnt/gulster/data目录,而不是对组成卷组的空间进行限制。
Gluster日常维护及故障处理
注:给自己的提示:此处如有不详之处查看qq微云—linux-glusterfs文件夹
1、硬盘故障
如果底层做了raid配置,有硬件故障,直接更换硬盘,会自动同步数据。
如果没有做raid处理方法:参看其他博客:http://blog.51cto.com/cmdschool/1908647
2、一台主机故障
https://www.cnblogs.com/xiexiaohua007/p/6602315.html
一台节点故障的情况包含以下情况:
物理故障
同时有多块硬盘故障,造成数据丢失
系统损坏不可修复
解决方法:
找一台完全一样的机器,至少要保证硬盘数量和大小一致,安装系统,配置和故障机同样的 IP,安装 gluster 软件, 保证配置一样,在其他健康节点上执行命令 gluster peer status,查看故障服务器的 uuid
[root@mystorage2 ~]# gluster peer status
Number of Peers: 3
Hostname: mystorage3
Uuid: 36e4c45c-466f-47b0-b829-dcd4a69ca2e7
State: Peer in Cluster (Connected)
Hostname: mystorage4
Uuid: c607f6c2-bdcb-4768-bc82-4bc2243b1b7a
State: Peer in Cluster (Connected)
Hostname: mystorage1
Uuid: 6e6a84af-ac7a-44eb-85c9-50f1f46acef1
State: Peer in Cluster (Disconnected)
复制代码
修改新加机器的 /var/lib/glusterd/glusterd.info 和 故障机器一样
[root@mystorage1 ~]# cat /var/lib/glusterd/glusterd.info
UUID=6e6a84af-ac7a-44eb-85c9-50f1f46acef1
operating-version=30712
在信任存储池中任意节点执行
# gluster volume heal gv2 full
就会自动开始同步,但在同步的时候会影响整个系统的性能。
可以查看状态
# gluster volume heal gv2 info
GlusterFS在企业中应用场景
理论和实践分析,GlusterFS目前主要使用大文件存储场景,对于小文件尤其是海量小文件,存储效率和访问性能都表现不佳,海量小文件LOSF问题是工业界和学术界的人工难题,GlusterFS作为通用的分布式文件系统,并没有对小文件额外的优化措施,性能不好也是可以理解的。
Media
-文档、图片、音频、视频
Shared storage
-云存储、虚拟化存储、HPC(高性能计算)
Big data
-日志文件、RFID(射频识别)数据
glusterfs 扩展阅读:
GlusterFS原创资源:https://blog.csdn.net/liuaigui/article/details/17331557
官方手册:https://docs.gluster.org/en/latest/Quick-Start-Guide/Quickstart/#purpose-of-this-document
glusterfs分布式存储部署:https://blog.csdn.net/goser329/article/details/78569257

若有收获,就点个赞吧
0 人点赞
