任务背景
虽然使用了分布式的glusterfs存储, 但是对于爆炸式的数据增长仍然感觉力不从心。随着大数据与云计算等技术的成熟, 存储也需要跟上步伐. 所以这次我们选用对象存储.
任务要求
1, 搭建ceph集群
2, 实现对象存储的应用
任务拆解
1, 了解ceph
2, 搭建ceph集群
3, 了解rados原生数据存取
4, 实现ceph文件存储
5, 实现ceph块存储
6, 实现ceph对象存储
学习目标
- 能够成功部署ceph集群
- 能够使用ceph共享文件存储,块存储与对象存储
- 能够说出对象存储的特点
前言
对象存储概念及实现
对象存储引入
为什么要有对象存储?
- 文件存储
- 其立足于纹理存储截止之上,是操作系统对数据管理操作的抽象,这些抽象最终汇总形成文件系统,例如nfs、samba 等。
- 文件系统遵循POSIX标准从而定义了操作系统为上层应用程序提供了接口的标准。
- 基于这套标准可以非常方便的管理文件和文件夹,常见的文件系统都是按目录数进行管理
- 但是文件存储达到海量之后就有些低效了,比如一些遍历操作
优点:便于共享
缺点:文件数量多和大的话,不便于传输和查找
- 块存储
- 主要将存储介质的空间整体映射给主机使用,主机需要对这些空间进行读写IO操作,需要进行分区和格式化操作,形成可以被操作系统识别的逻辑命名空间,之后主机才可以通过操作系统对这些存储介质进行读写操作,常见的块存储有磁盘,SSD,SAN等。
- 这些物理设备或多或少存在物理上限问题,比如存储空间、性能等都存在物理极限
优点:以块单元,方便传输,速度较快,可以由用户来自行分区,格式化等
缺点:无法数据共享,无法数据可视化
- 对象存储
- 适用于当前互联网爆照式的数据需求

- 扁平化的命名空间
- 对象存储就是数据存储,==把数据以对象(Object)形式存储在桶(Bucket)==为命名空间的的结构中。(鱼放在桶中)
- 通过新增Bucket的方式横向扩张命名空间,同时通过在Bucket中新增Object方式来存储海量数据。(增加Bucket的方式增加存储空间)
- 这种扁平话的数据管理模型克服 了目录树管理的不足,实现了海量数据简单有效的管理
- Bucket全局名称,通过桶名称和对象的键名来定位一个对象的最终存储路劲。
- 分布式架构设计
- 通过命名空间规则进行底层对象数据存储分区,借助哈希算法最终将需要存储的数据按分区规则均匀分布到多个主机的多个磁盘上的对象存储设备OSD
- 从而实现数据分布式存储,解决了物理硬件设备的扩容和性能问题,为海量数据存储铺平道路
- 对象存储数据借助哈希算法以分区的方式存储到多个主机的对象存储设备OSD中
- 接口标准
- 解决了海量数据管理和硬件短板问题后,对象存储还需要实现通用接口的标准
- 这个接口是整个系统和外界系统数据传输的重要窗口,如何兼容各个外围系统,去适配各种开发语言,形成了一套对象存储系统的生态接口标准RESTful风格的API,同时也衍生出各种语言的SDK
- (非)结构化数据和对象存储的关系
- 有一定结构的数据,比如数据库存储的数据就是结构化数据
- 非结构化数据没有一定规则和结构,比如存储的相片都是以二进制方式存储
- 由于非结构化数据在关系型数据库管理的缺陷,在对象存储模型中,把每一条非结构化数据抽象成一个对象存储
- 一个对象object:有四部分组成
- 键名Key:用于标识对象的名称。由Bucket name + key 来确定对象的存储路劲
- 键值Value : 用于存储对象的内容数据
- 访问控制ACL:标识对象可以被哪些用户和用户组访问
- 元数据Metadata:以key-value形式存储对象的额外信息(对象内容的MD5校验值,atime/ctime/mtime,对象的属主)

总结:通过扁平化的命名空间,分布式的存储架构设计,通用型的接口标准,以对象方式存储非结构化数据的方式
一、认识Ceph
Ceph架构简介及使用场景介绍 Ceph啥都有:https://www.bookstack.cn/search/result?wd=ceph&tab=book Ceph中文文档: http://docs.ceph.org.cn/ 版本至到10. Jewel https://www.bookstack.cn/read/ceph-10-zh/d81603911af53a39.md
Ceph是一个能提供的文件存储,块存储和对象存储的分布式存储系统。它提供了一个可无限伸缩的Ceph存储集群。
ceph 是一个可靠的、自组织的、可自我修复、可自我管理的分布式文件系统
官方网站:https://ceph.io/
- 高性能
- a. 摒弃了传统的集中式存储元数据寻址的方案,采用CRUSH算法,数据分布均衡,并行度高。
- b.考虑了容灾域的隔离,能够实现各类负载的副本放置规则,例如跨机房、机架感知等。
- c. 能够支持上千个存储节点的规模,支持TB到PB级的数据。
- 高可用性
- a. 副本数可以灵活控制。
- b. 支持故障域分隔,数据强一致性。
- c. 多种故障场景自动进行修复自愈。
- d. 没有单点故障,自动管理。
- 高可扩展性
- a. 去中心化。
- b. 扩展灵活。
- c. 随着节点增加而线性增长。
- 特性丰富
- a. 支持三种存储接口:块存储、文件存储、对象存储。
- b. 支持自定义接口,支持多种语言驱动。
二、ceph架构
ceph 版本
英文文档:https://docs.ceph.com/en/latest/releases/
版本号有三部分组成,X.y.z. x标识释放周期(例如,13表示模拟)。y标识发布类型:
- X.0.z-开发版本(适用于早期测试人员和内心勇敢的人)
- X.1.z-发布候选版本(用于测试集群,勇敢的用户)
- X.2.z-稳定/修复版本(供用户使用) V13.2.10 MIMIC 2020年4月
各个版本发布的时间如下:
ceph基础组件


RADOS: Ceph的高可靠,高可拓展,高性能,高自动化都是由这一层来提供的, 用户数据的存储最终也都是通过这一层来进行存储的。
可以说RADOS就是ceph底层原生的数据引擎, 但实际应用时却不直接使用它,而是分为如下4种方式来使用:
- LIBRADOS是一个库, 它允许应用程序通过访问该库来与RADOS系统进行交互,支持多种编程语言。如Python,C,C++等. 简单来说,就是给开发人员使用的接口。
- CEPH FS通过Linux内核客户端和FUSE来提供文件系统。(文件存储)
- RBD通过Linux内核客户端和QEMU/KVM驱动来提供一个分布式的块设备。(块存储)
- RADOSGW是一套基于当前流行的RESTFUL协议的网关,并且兼容S3和Swift。(对象存储)
ceph存储数据方法(IO算法)
ceph存储数据的详细流程:https://blog.csdn.net/cloudxli/article/details/79518620

Ceph中的寻址至少要经历以下三次映射
- Filefile就是用户需要存储或者读写的文件。File->Object映射
- 映射的目的:将用户要操作的file,映射为RADOS能够处理的object。
- 映射的本质上就是按照object的最大size对file进行切分
- ino 是待操作file的元数据,该file的唯一id
- ono是由该file切分产生的某个object的序号,默认以4M切分一个块大小
- object id是每一个切分后产生的object将获得唯一的oid
- oid (object id : ino + ono)文件id + 切分后的对象序号
- 例如:id为filename的file被切分成了三个object,则其object序号依次为0、1和2,而最终得到的oid就依次为filename0、filename1和filename2。
- Object 是
RADOS对象存储系统中 需要的对象。Object ->PG映射- 在file被映射为一个或多个object之后,就需要将每个object独立地映射到一个PG中去
- Ceph系统指定的一个静态哈希函数计算oid的哈希值,将oid映射成为一个近似均匀分布的伪随机值。然后,将这个伪随机值和mask按位相与,得到最终的PG序号(pgid)
- 公式:hash(oid) & mask -> pgid()
- mask = PG总数m(m应该为2的整数幂)
- PG(Placement Group)用途是对object的存储进行组织和位置映射,PG -> OSD映射
- OSD —— 即object storage device,对象存储设备
- 映射的目的将作为object的逻辑组织单元的PG映射到数据的实际存储单元OSD
- RADOS采用一个名为
CRUSH的算法,将pgid代入其中,然后得到一组共n个OSD。这n个OSD即共同负责存储和维护一个PG中的所有object - CRUSH (pgid) ->(osd1,osd2,osd3)
- PG负责组织若干个object,但一个object只能被映射到一个PG中,即,PG和object之间是“一对多”映射关系。
- 一个PG会被映射到n个OSD上,而每个OSD上都会承载大量的PG,即,PG和OSD之间是“多对多”映射关系
- 在实践当中,n至少为2,如果用于生产环境,则至少为3。一个OSD上的PG则可达到数百个。事实上,PG数量的设置牵扯到数据分布的均匀性问题
CRUSH算法: Crush(Controlled Replication Under Scalable Hashing)算法为可控的,可扩展的,分布式副本数据放置算法的简称。 一个对象需要保存三个副本,也就需要保存到三个OSD上。 Crush算法使得数据的存储位置都是计算出来的而不是去查询专门的元数据服务器得来的。
总结:
- ceph 存储数据要经过三次寻址操作,即三次映射
- File->Object映射:file切分成要存储的object
- Object ->PG映射:把对象归置组
- PG -> OSD映射:把归置的对象存储到 n 个OSD 对象存储设备
拓展名词
RESTFUL: RESTFUL是一种架构风格,提供了一组设计原则和约束条件,http就属于这种风格的典型应用。REST最大的几个特点为:资源、统一接口、URI和无状态。
- 资源: 网络上一个具体的信息: 一个文件,一张图片,一段视频都算是一种资源。
- 统一接口: 数据的元操作,即CRUD(create, read, update和delete)操作,分别对应于HTTP方法
- GET(SELECT):从服务器取出资源(一项或多项)。
- POST(CREATE):在服务器新建一个资源。
- PUT(UPDATE):在服务器更新资源(客户端提供完整资源数据)。
- PATCH(UPDATE):在服务器更新资源(客户端提供需要修改的资源数据)。
- DELETE(DELETE):从服务器删除资源。
- URI(统一资源定位符): 每个URI都对应一个特定的资源。要获取这个资源,访问它的URI就可以。最典型的URI即URL
- 无状态: 一个资源的定位与其它资源无关,不受其它资源的影响。
S3 (Simple Storage Service 简单存储服务): 可以把S3看作是一个超大的硬盘, 里面存放数据资源(文件,图片,视频等),这些资源统称为对象.这些对象存放在存储段里,在S3叫做bucket.
和硬盘做类比, 存储段(bucket)就相当于目录,对象就相当于文件。
- 硬盘路径类似
/root/file1.txt - S3的URI类似
s3://bucket_name/object_name
swift: 最初是由Rackspace公司开发的高可用分布式对象存储服务,并于2010年贡献给OpenStack开源社区作为其最初的核心子项目之一.
对象存储:swift、FastDFS、ceph
补充:
URI 在于I(Identifier)是统一资源标示符,可以唯一标识一个资源。
URL在于Locater,一般来说(URL)统一资源定位符,可以提供找到该资源的路径
URN = Uniform Resource Name 统一资源名称,通过特定命名空间中的唯一名称或ID来标识资源
URI是抽象的定义,不管用什么方法表示,只要能定位一个资源,就叫URI,本来设想的的使用两种方法定位:1,URL,用地址定位;2,URN 用名称定位。换言之,URN定义某事物的身份,而URL提供查找该事物的方法。
举个例子:去村子找个具体的人(URI),如果用地址:某村多少号房子第几间房的主人 就是URL, 如果用身份证号+名字 去找就是URN了。
结果就是 目前WEB上就URL流行开了,平常见得URI 基本都是URL。
举个栗子:
个人的身份证号就是URN,个人的家庭地址就是URL,URN可以唯一标识一个人,而URL可以告诉邮递员怎么把货送到你手里。
统一资源标志符URI就是在某一规则下能把一个资源独一无二地标识出来。
拿人做例子,假设这个世界上所有人的名字都不能重复,那么名字就是URI的一个实例,通过名字这个字符串就可以标识出唯一的一个人。
现实当中名字当然是会重复的,所以身份证号才是URI,通过身份证号能让我们能且仅能确定一个人。
那统一资源定位符URL是什么呢。也拿人做例子然后跟HTTP的URL做类比,
就可以有:动物住址协议://地球/中国/浙江省/杭州市/西湖区/某大学/14号宿舍楼/525号寝/张三.
人可以看到,这个字符串同样标识出了唯一的一个人,起到了URI的作用,所以URL是URI的子集。
URL是以描述人的位置来唯一确定一个人的。在上文我们用身份证号也可以唯一确定一个人。对于这个在杭州的张三,我们也可以用:身份证号:123456789来标识他。所以不论是用定位的方式还是用编号的方式,我们都可以唯一确定一个人,都是URl的一种实现,而URL就是用定位的方式实现的URI。
回到Web上,假设所有的Html文档都有唯一的编号,记作html:xxxxx,xxxxx是一串数字,即Html文档的身份证号码,这个能唯一标识一个Html文档,那么这个号码就是一个URI。而URL则通过描述是哪个主机上哪个路径上的文件来唯一确定一个资源,也就是定位的方式来实现的URI。对于现在网址我更倾向于叫它URL,毕竟它提供了资源的位置信息,如果有一天网址通过号码来标识变成了http://741236985.html,那感觉叫成URI更为合适,不过这样子的话还得想办法找到这个资源咯…
三、Ceph集群
Ceph 简介 不管你是想为云平台提供Ceph 对象存储和/或 Ceph 块设备,还是想部署一个 Ceph 文件系统或者把 Ceph 作为他用,所有 Ceph 存储集群的部署都始于部署一个个 Ceph 节点、网络和 Ceph 存储集群。 Ceph 存储集群至少需要一个 Ceph Monitor 和两个 OSD 守护进程。而运行 Ceph 文件系统客户端时,则必须要有元数据服务器( Metadata Server )。
- Ceph OSDs: Ceph OSD 守护进程( Ceph OSD )的功能是存储数据,处理数据的复制、恢复、回填、再均衡,并通过检查其他OSD 守护进程的心跳来向 Ceph Monitors 提供一些监控信息。当 Ceph 存储集群设定为有2个副本时,至少需要2个 OSD 守护进程,集群才能达到
active+clean状态( Ceph 默认有3个副本,但你可以调整副本数)。- Monitors: Ceph Monitor维护着展示集群状态的各种图表,包括监视器图、 OSD 图、归置组( PG )图、和 CRUSH 图。 Ceph 保存着发生在Monitors 、 OSD 和 PG上的每一次状态变更的历史信息(称为 epoch )。
- MDSs: Ceph 元数据服务器( MDS )为 Ceph 文件系统存储元数据(也就是说,Ceph 块设备和 Ceph 对象存储不使用MDS )。元数据服务器使得 POSIX 文件系统的用户们,可以在不对 Ceph 存储集群造成负担的前提下,执行诸如
ls、find等基本命令。Ceph 把客户端数据保存为存储池内的对象。通过使用 CRUSH 算法, Ceph 可以计算出哪个归置组(PG)应该持有指定的对象(Object),然后进一步计算出哪个 OSD 守护进程持有该归置组。 CRUSH 算法使得 Ceph 存储集群能够动态地伸缩、再均衡和修复。

集群组件
https://docs.ceph.com/en/mimic/start/intro/
CJoseph存储集群至少需要一个CephMonitor、CephManager和CephOSD(对象存储守护进程)。在运行CephFilessystem客户端时,也需要CJoseph元数据服务器。

Ceph集群包括Ceph OSD,Ceph Monitor两种守护进程。
Ceph OSD(Object Storage Device): 功能是存储数据,处理数据的复制、恢复、回填、再均衡,并通过检查其他OSD守护进程的心跳来向Ceph Monitors提供一些监控信息。冗余和高可用性通常需要至少3个CephOSD。Ceph Monitor: 是一个监视器,监视Ceph集群状态和维护集群中的各种关系。- Ceph存储集群至少需要一个Ceph Monitor和两个 OSD 守护进程。Ceph Monitor建议奇数个,因为要选举。
CephManager (ceph-mgr)负责跟踪运行时指标和CJoseph集群的当前状态,包括存储利用率、当前性能指标和系统负载。该组件的主要作用是分担和扩展monitor的部分功能,减轻monitor的负担,让更好地管理ceph存储系统。Ceph-mds:ceph-mds 是 Ceph 分布式文件系统的元数据服务器守护进程。一或多个 ceph-mds 例程协作着管理文件系统的命名空间、协调到共享 OSD 集群的访问。- Ceph文件存储类型存放与管理==元数据metadata(文件的属组,属主,权限,防控列表以及一些其他的描述信息)==的服务
集群环境准备

准备工作:
ceph 可以有两种网络,一种是专门做OSD数据存储的cluster网络,一种是连接互联网public 网络
准备四台服务器,需要能上外网,IP静态固定 (除client外每台最少加1个磁盘,最小1G,不用分区);
# lsblk
1, 配置主机名和主机名绑定(所有节点都要绑定)
(注意:这里都全改成短主机名,方便后面实验。如果你坚持用类似vm1.cluster.com这种主机名,或者加别名的话,ceph会在后面截取你的主机名vm1.cluster.com为vm1,造成不一致导致出错)
# hostnamectl set-hostname --static node1
# vim /etc/hosts
10.1.1.11 node1
10.1.1.12 node2
10.1.1.13 node3
10.1.1.14 client
2, 关闭防火墙,selinux(使用iptables -F清一下规则)
# systemctl stop firewalld
# systemctl disable firewalld
# firewall-cmd --state
# iptables -nL 清空DROP 规则
# iptables -F
# setenforce 0
# sestatus
3, 时间同步(启动ntpd服务并确认所有节点时间一致,包括client)
# systemctl restart ntpd
# systemctl enable ntpd
或者
# crontab -l
0 */1 * * * ntpdate ntp.aliyun.com
4, 配置yum源(所有节点都要配置,包括client)
# yum -y install epel-release
ceph的yum源方法2种:
https://www.cnblogs.com/sanduzxcvbnm/p/13553035.html
对于主要版本,您可以向
/etc/yum.repos.d目录。创建一个ceph.repo档案 在下面的示例中,替换{ceph-release}Ceph版本和{distro}使用您的Linux发行版(例如,el8等等)
一些CephPackage(例如,Epel)必须优先于标准包,因此您必须确保设置priority=2.
[ceph]
name=Ceph packages for $basearch
baseurl=https://download.ceph.com/rpm-{ceph-release}/{distro}/$basearch
enabled=1
priority=2
gpgcheck=1
gpgkey=https://download.ceph.com/keys/release.asc
[ceph-noarch]
name=Ceph noarch packages
baseurl=https://download.ceph.com/rpm-{ceph-release}/{distro}/noarch
enabled=1
priority=2
gpgcheck=1
gpgkey=https://download.ceph.com/keys/release.asc
[ceph-source]
name=Ceph source packages
baseurl=https://download.ceph.com/rpm-{ceph-release}/{distro}/SRPMS
enabled=0
priority=2
gpgcheck=1
gpgkey=https://download.ceph.com/keys/release.asc
- 公网ceph源(centos7默认的公网源+epel源+ceph的aliyun源)
# yum install epel-release -y
# vim /etc/yum.repos.d/ceph.repo
[ceph]
name=ceph
baseurl=http://mirrors.aliyun.com/ceph/rpm-mimic/el7/x86_64/
enabled=1
gpgcheck=0
priority=1
[ceph-noarch]
name=cephnoarch
baseurl=http://mirrors.aliyun.com/ceph/rpm-mimic/el7/noarch/
enabled=1
gpgcheck=0
priority=1
[ceph-source]
name=Ceph source packages
baseurl=http://mirrors.aliyun.com/ceph/rpm-mimic/el7/SRPMS
enabled=1
gpgcheck=0
priority=1
- 本地ceph源(centos7默认的公网源+ceph本地源)
- 公网源下载网络慢,而且公网源可能更新会造成问题。可使用下载好的做本地ceph源
将共享的ceph_soft目录拷贝到所有节点上(比如:/root/目录下)
# vim /etc/yum.repos.d/ceph.repo
[local_ceph]
name=local_ceph
baseurl=file:///root/ceph_soft
gpgcheck=0
enabled=1
集群部署过程
用的版本是minic [ˈmɪmɪk]
http://docs.ceph.org.cn/start/
https://docs.ceph.com/en/mimic/start/quick-start-preflight/
http://docs.ceph.org.cn/start/quick-start-preflight/#ceph
http://docs.ceph.org.cn/rados/deployment/
创建部署 CEPH 的用户(所有节点)
ceph-deploy 工具必须以普通用户登录 Ceph 节点,且此用户拥有无密码使用 sudo 的权限,因为它需要在安装软件及配置文件的过程中,不必输入密码。
建议在集群内的所有 Ceph 节点上给 ceph-deploy 创建一个特定的用户,但不要用 “ceph” 这个名字。
在各 Ceph 节点创建新用户
# sudo useradd -d /home/zeng -m zeng
# sudo passwd zeng
确保各 Ceph 节点上新创建的用户都有 sudo 权限
# echo "zeng ALL = (root) NOPASSWD:ALL" | sudo tee /etc/sudoers.d/zeng
# sudo chmod 0440 /etc/sudoers.d/zeng
第1步: 配置ssh免密
以node1为部署配置节点,在node1上配置ssh等效性(要求ssh node1,node2,node3 ,client都要免密码)
说明: 此步骤不是必要的,做此步骤的目的:
- 如果使用ceph-deploy来安装集群,密钥会方便安装
- 如果不使用ceph-deploy安装,也可以方便后面操作: 比如同步配置文件
ssh-keygen 产生公钥与私钥对.
ssh-copy-id 将本机的公钥复制到远程机器的authorized_keys文件中,ssh-copy-id也能让你有到远程机器的home, ~./ssh , 和 ~/.ssh/authorized_keys的权利
[root@node1 ~]# ssh-keygen
[root@node1 ~]# ssh-copy-id -i node1
[root@node1 ~]# ssh-copy-id -i node2
[root@node1 ~]# ssh-copy-id -i node3
[root@node1 ~]# ssh-copy-id -i client
第2步: 在node1上安装部署工具
(其它节点不用安装)
[root@node1 ~]# yum install ceph-deploy -y
第3步: 在node1上创建集群
建立一个集群配置目录
用于保存 ceph-deploy 生成的配置文件和密钥对。
注意: 后面的大部分操作都会在此目录
[root@node1 ~]# mkdir /etc/ceph
[root@node1 ~]# cd /etc/ceph
创建一个ceph集群
使node1成 部署节点
[root@node1 ceph]# ceph-deploy new node1
[root@node1 ceph]# ls
ceph.conf ceph-deploy-ceph.log ceph.mon.keyring
说明:
ceph.conf 集群配置文件
ceph-deploy-ceph.log 使用ceph-deploy部署的日志记录
ceph.mon.keyring mon的验证key文件
问题:如果出现 “[ceph_deploy][ERROR ] RuntimeError: remote connection got closed, ensure
requirettyis disabled for node1”,执行 sudo visudo 将 Defaults requiretty 注释掉。
第4步: ceph集群节点安装ceph
前面准备环境时已经准备好了yum源,在这里==所有集群节点不包括client==都安装以下软件
如果公网OK,并且网速好的话
# ceph-deploy install node1 node2 node3
网速不好用下面的方法
# yum install ceph ceph-radosgw -y
# ceph -v
ceph version 13.2.6 (02899bfda814146b021136e9d8e80eba494e1126) mimic (stable)
补充说明:
- 如果公网OK,并且网速好的话,可以用
ceph-deploy install node1 node2 node3命令来安装,但网速不好的话会比较坑 - 所以这里我们选择直接用准备好的本地ceph源,然后
yum install ceph ceph-radosgw -y安装即可。
如果在某些地方碰到麻烦,想从头再来,可以用下列命令清除配置:
# ceph-deploy purgedata {ceph-node} [{ceph-node}]
# ceph-deploy forgetkeys
用下列命令可以连 Ceph 安装包一起清除:
# ceph-deploy purge {ceph-node} [{ceph-node}]
# rm ceph.*
如果执行了
purge,你必须重新安装 Ceph 。 要从集群主机卸载 Ceph 软件包,在管理主机的终端下执行:
# ceph-deploy uninstall {hostname [hostname] ...}
在 Debian 或 Ubuntu 系统上你也可以:
# ceph-deploy purge {hostname [hostname] ...}
此工具会从指定主机上卸载
ceph软件包,另外purge会删除配置文件。
第5步: 客户端安装ceph-common
[root@client ~]# yum install ceph-common -y
第6步: 创建mon(监控)
增加public网络用于监控
在[global]配置段里添加下面一句(直接放到最后一行)
[root@node1 ceph]# vim /etc/ceph/ceph.conf
public network = 10.1.1.0/24 监控网络
监控节点初始化,并同步配置到所有节点(node1,node2,node3,不包括client)
[root@node1 ceph]# ceph health
配置初始 monitor(s)、并收集所有密钥:
[root@node1 ceph]# ceph-deploy mon create-initial
[root@node1 ceph]# ceph health
HEALTH_OK 状态health(健康)
[root@node1 ceph]# ls
将配置文件信息同步到所有节点(用 ceph-deploy 把配置文件和 admin 密钥拷贝到管理节点和 Ceph 节点的/etc/ceph)
[root@node1 ceph]# ceph-deploy admin node1 node2 node3
[root@node2 ceph]# ls /etc/ceph 查看
[root@node1 ceph]# ceph -s
cluster:
id: c05c1f28-ea78-41b7-b674-a069d90553ac
health: HEALTH_OK 健康状态为OK
services:
mon: 1 daemons, quorum node1 1个监控
mgr: no daemons active
osd: 0 osds: 0 up, 0 in
data:
pools: 0 pools, 0 pgs
objects: 0 objects, 0 B
usage: 0 B used, 0 B / 0 B avail
pgs:
为了防止mon单点故障,你可以加多个mon节点(建议奇数个,因为有quorum仲裁投票)
回顾: 什么是quorum(仲裁,法定人数)?
[root@node1 ceph]# ceph-deploy mon add node2
[root@node1 ceph]# ceph-deploy mon add node3
[root@node1 ceph]# ceph -s
cluster:
id: c05c1f28-ea78-41b7-b674-a069d90553ac
health: HEALTH_OK 健康状态为OK
services:
mon: 3 daemons, quorum node1,node2,node3 3个监控
mgr: no daemons active
osd: 0 osds: 0 up, 0 in
data:
pools: 0 pools, 0 pgs
objects: 0 objects, 0 B
usage: 0 B used, 0 B / 0 B avail
pgs:
[root@node1 ceph]# ceph mon dump
[root@node1 ceph]# ceph mon stat
监控到时间不同步的解决方法
ceph集群对时间同步要求非常高, 即使你已经将ntpd服务开启,但仍然可能有clock skew deteted相关警告
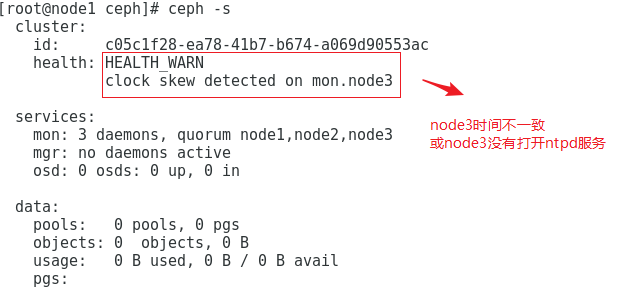
请做如下尝试:
1, 在ceph集群所有节点上(node1,node2,node3)不使用ntpd服务,直接使用crontab同步
# systemctl stop ntpd
# systemctl disable ntpd
# crontab -e
*/10 * * * * ntpdate ntp1.aliyun.com 每5或10分钟同步1次公网的任意时间服务器
2, 调大时间警告的阈值
[root@node1 ceph]# vim ceph.conf
[global] 在global参数组里添加以下两行
......
mon clock drift allowed = 2 # monitor间的时钟滴答数(默认0.5秒)
mon clock drift warn backoff = 30 # 调大时钟允许的偏移量(默认为5)
3, 同步到所有节点
[root@node1 ceph]# ceph-deploy --overwrite-conf admin node1 node2 node3
前面第1次同步不需要加--overwrite-conf参数
这次修改ceph.conf再同步就需要加--overwrite-conf参数覆盖
4, 所有ceph集群节点上重启ceph-mon.target服务
# systemctl restart ceph-mon.target

第7步: 创建mgr(管理节点)
ceph luminous版本中新增加了一个组件:Ceph Manager Daemon,简称ceph-mgr。
该组件的主要作用是分担和扩展monitor的部分功能,减轻monitor的负担,让更好地管理ceph存储系统。
创建一个mgr
[root@node1 ceph]# ceph-deploy mgr create node1
[root@node1 ceph]# ceph -s
cluster:
id: c05c1f28-ea78-41b7-b674-a069d90553ac
health: HEALTH_OK
services:
mon: 3 daemons, quorum node1,node2,node3
mgr: node1(active) node1为mgr
osd: 0 osds: 0 up, 0 in
data:
pools: 0 pools, 0 pgs
objects: 0 objects, 0 B
usage: 0 B used, 0 B / 0 B avail
pgs:
添加多个mgr可以实现HA
[root@node1 ceph]# ceph-deploy mgr create node2
[root@node1 ceph]# ceph-deploy mgr create node3
[root@node1 ceph]# ceph -s
cluster:
id: c05c1f28-ea78-41b7-b674-a069d90553ac
health: HEALTH_OK 健康状态为OK
services:
mon: 3 daemons, quorum node1,node2,node3 3个监控
mgr: node1(active), standbys: node2, node3 看到node1为主,node2,node3为备
osd: 0 osds: 0 up, 0 in 看到为0个磁盘
data:
pools: 0 pools, 0 pgs
objects: 0 objects, 0 B
usage: 0 B used, 0 B / 0 B avail
pgs:
第8步: 创建osd(存储盘)
[root@node1 ceph]# ceph-deploy disk --help
[root@node1 ceph]# ceph-deploy osd --help
列表所有节点的磁盘,都有sda和sdb两个盘,sdb为我们要加入分布式存储的盘
之前的磁盘不需要分区也不需要格式化
列表查看节点上的磁盘
列举磁盘
[root@node1 ceph]#lsblk
[root@node1 ceph]# ceph-deploy disk list node1
[root@node1 ceph]# ceph-deploy disk list node2
[root@node1 ceph]# ceph-deploy disk list node3
列举磁盘
zap表示擦除磁盘上的数据,相当于格式化
[root@node1 ceph]# ceph-deploy disk zap node1 /dev/sdb
[root@node1 ceph]# ceph-deploy disk zap node2 /dev/sdb
[root@node1 ceph]# ceph-deploy disk zap node3 /dev/sdb
创建 OSD
将磁盘创建为osd
[root@node1 ceph]# ceph-deploy osd create --data /dev/sdb node1
[root@node1 ceph]# ceph-deploy osd create --data /dev/sdb node2
[root@node1 ceph]# ceph-deploy osd create --data /dev/sdb node3
[root@node1 ceph]# ceph -s
cluster:
id: c05c1f28-ea78-41b7-b674-a069d90553ac
health: HEALTH_OK
services:
mon: 3 daemons, quorum node1,node2,node3
mgr: node1(active), standbys: node2, node3
osd: 3 osds: 3 up, 3 in 看到这里有3个osd
data:
pools: 0 pools, 0 pgs
objects: 0 objects, 0 B
usage: 41 MiB used, 2.9 GiB / 3.0 GiB avail 大小为3个磁盘的总和
pgs:
osd都创建好了,那么怎么存取数据呢?
集群节点的扩容方法
假设再加一个新的集群节点node4
1, 主机名配置和绑定
2, 在node4上yum install ceph ceph-radosgw -y安装软件
3, 在部署节点node1上同步配置文件给node4. ceph-deploy admin node4
4, 按需求选择在node4上添加mon或mgr或osd等
在node4上安装软件
# yum install ceph ceph-radosgw -y`
同步配置文件给node4
# ceph-deploy admin node4
添加node4 为 mgr实现HA
# ceph-deploy mgr create node4
添加 Monitors
# ceph-deploy mon add node4
Ceph 存储集群需要至少一个 Monitor 才能运行。为达到高可用,典型的 Ceph 存储集群会运行多个 Monitors,这样在单个 Monitor 失败时不会影响 Ceph 存储集群的可用性。Ceph 使用 PASOX 算法,此算法要求有多半 monitors(即 1 、 2:3 、 3:4 、 3:5 、 4:6 等 )形成法定人数。
添加 OSD
# ceph-deploy disk zap node4 /dev/sdb
# ceph-deploy osd create --data /dev/sdb node4
一旦你新加了 OSD , Ceph 集群就开始重均衡,把归置组迁移到新 OSD 。可以用下面的 ceph 命令观察此过程:
# ceph -w
你应该能看到归置组状态从 active + clean 变为 active ,还有一些降级的对象;迁移完成后又会回到 active + clean 状态( Control-C 退出)。
四、RADOS原生数据存取演示
上面提到了RADOS也可以进行数据的存取操作, 但我们一般不直接使用它,但我们可以先用RADOS的方式来深入了解下ceph的数据存取原理。
存取原理
要实现数据存取需要创建一个pool,创建pool要先分配PG。
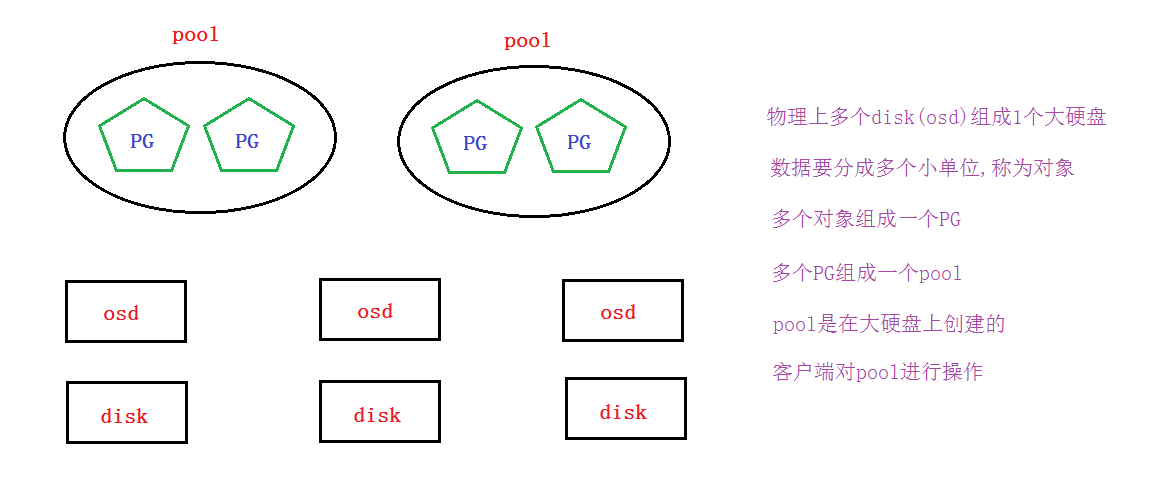
如果客户端对一个pool写了一个文件, 那么这个文件是如何分布到多个节点的磁盘上呢?
答案是通过CRUSH算法。

CRUSH算法
- CRUSH(Controlled Scalable Decentralized Placement of Replicated Data)算法为可控的,可扩展的,分布式的副本数据放置算法的简称。
- PG到OSD的映射的过程算法叫做CRUSH 算法。(一个Object需要保存三个副本,也就是需要保存在三个osd上)。
- CRUSH算法是一个伪随机的过程,他可以从所有的OSD中,随机性选择一个OSD集合,但是同一个PG每次随机选择的结果是不变的,也就是映射的OSD集合是固定的。
小结:
- 客户端直接对pool操作(但文件存储,块存储,对象存储我们不这么做)
- pool里要分配PG
- PG里可以存放多个对象
- 对象就是由客户端写入的数据分离的单位
- CRUSH算法将客户端写入的数据映射分布到OSD,从而最终存放到物理磁盘上(这个具体过程是抽象的,我们运维工程师可不用再深挖,因为分布式存储对于运维工程师来说就一个大硬盘)
创建pool(存储池)
存储池相关操作:http://docs.ceph.org.cn/rados/operations/pools/
创建test_pool,指定pg数为128
[root@node1 ceph]# ceph osd pool create test_pool 128
pool 'test_pool' created
查看pg数量,可以使用ceph osd pool set test_pool pg_num 64这样的命令来尝试调整
[root@node1 ceph]# ceph osd pool get test_pool pg_num
pg_num: 128 存储池拥有的归置组总数
说明: pg数与ods数量有关系
- pg数为2的倍数,一般5个以下osd,分128个PG或以下即可(分多了PG会报错的,可按报错适当调低)
- 可以使用
ceph osd pool set test_pool pg_num 64这样的命令来尝试调整
用此命令创建存储池时:
ceph osd pool create {pool-name} pg_num
确定
pg_num取值是强制性的,因为不能自动计算。下面是几个常用的值:
- 少于 5 个 OSD 时可把
pg_num设置为 128- OSD 数量在 5 到 10 个时,可把
pg_num设置为 512- OSD 数量在 10 到 50 个时,可把
pg_num设置为 4096- OSD 数量大于 50 时,你得理解权衡方法、以及如何自己计算
pg_num取值- 自己计算
pg_num取值时可借助 pgcalc 工具随着 OSD 数量的增加,正确的 pg_num 取值变得更加重要,因为它显著地影响着集群的行为、以及出错时的数据持久性(即灾难性事件导致数据丢失的概率)。
存储测试
存入/检出对象数据 要把对象存入 Ceph 存储集群,客户端必须做到:
- 指定对象名
- 指定存储池
1, 我这里把本机的/etc/fstab文件上传到test_pool,并取名为newfstab
[root@node1 ceph]# rados put newfstab /etc/fstab --pool=test_pool
2, 查看
[root@node1 ceph]# rados -p test_pool ls
newfstab
[root@node1 ceph]# ceph df
3, 删除
[root@node1 ceph]# rados rm newfstab --pool=test_pool
删除pool
1, 在部署节点node1上增加参数允许ceph删除pool
[root@node1 ceph]# vim /etc/ceph/ceph.conf
mon_allow_pool_delete = true
2, 修改了配置, 要同步到其它集群节点
[root@node1 ceph]# ceph-deploy --overwrite-conf admin node1 node2 node3
3, 重启监控服务
[root@node1 ceph]# systemctl restart ceph-mon.target
4, 删除时pool名输两次,后再接--yes-i-really-really-mean-it参数就可以删除了
[root@node1 ceph]# ceph osd pool delete test_pool test_pool --yes-i-really-really-mean-it
[root@node1 ceph]# rados -p test_pool ls
[root@node1 ceph]# ceph df
五、创建Ceph文件存储
要运行Ceph文件系统, 你必须先创建至少带一个mds的Ceph存储集群.
(Ceph块设备和Ceph对象存储不使用MDS)。
Ceph MDS: Ceph文件存储类型存放与管理==元数据metadata(文件的属组,属主,权限,防控列表以及一些其他的描述信息)==的服务
创建文件存储并使用
http://docs.ceph.org.cn/cephfs/
ceph文件系统:https://docs.ceph.com/en/mimic/cephfs/
在管理节点上,进入刚创建的放置配置文件的目录,用 ceph-deploy 执行如下步骤。
第1步: 在node1部署节点上同步配置文件,并创建mds服务(也可以做多个mds实现HA)
Ceph 文件系统要求 Ceph 存储集群内至少有一个 Ceph 元数据服务器。
部署完监视器和 OSD 后,还可以部署元数据服务器。
[root@node1 ceph] cd /etc/ceph
[root@node1 ceph]# ceph-deploy mds create node1 node2 node3
我这里做三个mds
[root@node1 ceph]# ceph -s
[root@node1 ceph]# ceph mds stat
第2步: 一个Ceph文件系统需要至少两个RADOS存储池,一个用于数据,一个用于元数据。所以我们创建它们。
$ ceph osd pool create cephfs_data <pg_num>
$ ceph osd pool create cephfs_metadata <pg_num>
描述:存储池拥有的归置组总数。关于如何计算合适的数值 pg-num
描述:用于归置的归置组总数。此值应该等于归置组总数,归置组分割的情况下除外 pgp-num
查看存储池
[root@node1 ceph]# ceph osd pool ls
[root@node1 ceph]# ceph df
[root@node1 ceph]# ceph osd pool create cephfs_pool 128 128 为存储池拥有的归置组总数
pool 'cephfs_pool' created
[root@node1 ceph]# ceph osd pool create cephfs_metadata 64
pool 'cephfs_metadata' created
[root@node1 ceph]# ceph osd pool ls
[root@node1 ceph]# ceph df
[root@node1 ceph]# ceph osd pool ls |grep cephfs
cephfs_pool
cephfs_metadata
[root@node1 ceph]# ceph -s
第3步: 创建Ceph文件系统,并确认客户端访问的节点
http://docs.ceph.org.cn/start/quick-cephfs/
确认你使用了合适的内核版本,详情见操作系统推荐。
# lsb_release -a
# uname -r
创建好存储池后,你就可以用 fs new 命令创建文件系统了:$ ceph fs new <fs_name> <metadata> <data>
【创建文件系统】
[root@node1 ceph]# ceph fs new cephfs cephfs_metadata cephfs_pool
[root@node1 ceph]# ceph fs ls
name: cephfs, metadata pool: cephfs_metadata, data pools: [cephfs_pool ]
文件系统创建完毕后, 服务器就能达到 active 状态
[root@node1 ceph]# ceph mds stat
cephfs-1/1/1 up {0=ceph_node3=up:active}, 2 up:standby 这里看到node3为up状态
[root@node1 ceph]# ceph -s
第4步: 客户端准备验证key文件
- 说明: ceph默认启用了cephx认证, 所以客户端的挂载必须要验证
在集群节点(node1,node2,node3)上任意一台查看密钥字符串
【创建密钥文件】
ceph 默认开启了cephx 认证,要求客户端的挂载必须要用用户名和密码验证
[root@node1 ~]# cat ceph.conf
[root@node1 ~]# ls /etc/ceph
[root@node1 ~]# cat /etc/ceph/ceph.client.admin.keyring
[client.admin]
key = AQDEKlJdiLlKAxAARx/PXR3glQqtvFFMhlhPmw== 后面的字符串就是验证需要的
caps mds = "allow *"
caps mgr = "allow *"
caps mon = "allow *"
caps osd = "allow *"
使用ceph-authtool 验证工具生成密码key 文件
[root@node1 ~]# ceph-authtool -p /etc/ceph/ceph.client.admin.keyring > admin.key
拷贝给客户端
[root@node1 ~]# scp admin.key 10.1.1.14:/root
在客户端上创建一个文件记录密钥字符串(上面做了就可以省略)
[root@client ~]# vim admin.key # 创建一个密钥文件,复制粘贴上面得到的字符串
AQDEKlJdiLlKAxAARx/PXR3glQqtvFFMhlhPmw==
禁用 Cephx
下述步骤描述了如何禁用 Cephx 。如果你的集群环境相对安全,你可以减免认证耗费的计算资源,然而我们不推荐。但是临时禁用认证会使安装、和排障更简单。
1.把下列配置加入 Ceph 配置文件的 [global] 段下即可禁用 cephx 认证:
auth cluster required = none
auth service required = none
auth client required = none
2.启动或重启 Ceph 集群,具体参考操纵集群。
http://docs.ceph.org.cn/rados/operations/operating/
启动所有守护进程
要启动一 Ceph 节点(任何类型)上的所有守护进程,用下列命令:
sudo start ceph-all
停止所有守护进程
要停止一 Ceph 节点(任何类型)上的所有守护进程,用下列命令:
sudo stop ceph-all
按类型启动所有守护进程
要启动一节点上的某一类守护进程,用下列命令:
sudo start ceph-osd-all
sudo start ceph-mon-all
sudo start ceph-mds-all
按类型停止所有守护进程
要停止一节点上的某一类守护进程,用下列命令:
sudo stop ceph-osd-all
sudo stop ceph-mon-all
sudo stop ceph-mds-all
/etc/init.d/ceph -a start 启动 Ceph 集群
/etc/init.d/ceph -a stop 停止 Ceph 集群
第5步:在node1上部署client节点

[root@client ~]# ceph-deploy install client 失败或太慢
失败或太慢的或用下面命令
[root@client ~]# yum install ceph-common -y
或
[root@client ~]# yum install ceph ceph-radosgw -y
第6步:在客户端安装ceph-fuse,并使用产生的key 进行挂载

第5步: 客户端挂载(挂载ceph集群中跑了mon监控的节点, mon监控为6789端口)
[root@node1 ~]# ceph -s
挂载node1 node2 node3 都可以
[root@client ~]# mount -t ceph node1:6789:/ /mnt -o name=admin,secretfile=/root/admin.key
[root@client ~]# df -h
要卸载 Ceph 文件系统,可以用 unmount 命令,例如:umount /mnt
开机自动挂载:http://docs.ceph.org.cn/cephfs/fstab/
Ceph 文件系统将在启动时自动挂载。
[root@client ~]# vim /etc/fstab
【内核驱动方式】
内核驱动挂载 Ceph FS
{ipaddress}:{port}:/ {mount}/{mountpoint} {filesystem-name} [name=username,secret=secretkey|secretfile=/path/to/secretfile],[{mount.options}]
例如:
10.10.10.10:6789:/ /mnt/ceph ceph name=admin,secretfile=/etc/ceph/secret.key,noatime 0 2
【FUSE方式】
用户空间挂载 Ceph 文件系统 :
#DEVICE PATH TYPE OPTIONS
id={user-ID}[,conf={path/to/conf.conf}] /mount/path fuse.ceph defaults 0 0
例如:
id=admin /mnt/ceph fuse.ceph defaults 0 0
id=myuser,conf=/etc/ceph/cluster.conf /mnt/ceph2 fuse.ceph defaults 0 0
详解cephfs几种挂载方式:https://blog.csdn.net/wylfengyujiancheng/article/details/81102717
挂载cephfs有两种方式,kernel driver和fuse
【内核驱动】
把 Ceph FS 挂载为内核驱动。
sudo mkdir /mnt/mycephfs
sudo mount -t ceph {ip-address-of-monitor}:6789:/ /mnt/mycephfs
Ceph 存储集群默认需要认证,所以挂载时需要指定用户名 name 和创建密钥文件一节中创建的密钥文件 secretfile ,例如:
sudo mount -t ceph 192.168.0.1:6789:/ /mnt/mycephfs -o name=admin,secretfile=admin.secret
【用户空间文件系统( FUSE )】
用户空间文件系统 FUSE (ceph-fuse帮助用户直接在用户空间直接就可以使用文件系统而不是使用内核)
把 Ceph FS 挂载为用户空间文件系统( FUSE )。
sudo mkdir ~/mycephfs
sudo ceph-fuse -m {ip-address-of-monitor}:6789 ~/mycephfs
Ceph 存储集群默认要求认证,需指定相应的密钥环文件,除非它在默认位置(即 /etc/ceph ):
sudo ceph-fuse -k ./ceph.client.admin.keyring -m 192.168.0.1:6789 ~/mycephfs


第6步: 验证
[root@client ~]# df -h |tail -1
node1:6789:/ 3.8G 0 3.8G 0% /mnt # 大小不用在意,场景不一样,pg数,副本数都会影响
设置开机自动挂载/etc/fstab
# cat /etc/fstab
id=admin /mnt/ fuse.ceph defaults 0 0
# mount -a
如要验证读写请自行验证
可以使用两个客户端, 同时挂载此文件存储,可实现同读同写




删除文件存储方法
如果需要删除文件存储,请按下面操作过程来操作
第1步: 在客户端上删除数据,并umount所有挂载
[root@client ~]# rm /mnt/* -rf
[root@client ~]# umount /mnt/
第2步: 停掉所有节点的mds(只有停掉mds才能删除文件存储)
[root@node1 ~]# systemctl stop ceph-mds.target
[root@node2 ~]# systemctl stop ceph-mds.target
[root@node3 ~]# systemctl stop ceph-mds.target
[root@node3 ~]# systemctl status ceph-mds.target
第3步: 回到集群任意一个节点上(node1,node2,node3其中之一)删除
如果要客户端删除,需要在node1上ceph-deploy admin client同步配置才可以
以下操作不想在客户端删除可以到node1 上删除
[root@node1 ~]# cd /etc/ceph
执行以下操作
删除文件系统
[root@client ~]# ceph fs rm cephfs --yes-i-really-mean-it
[root@client ~]# ceph fs ls
删除存储池
要删除一存储池,执行:
ceph osd pool delete {pool-name} [{pool-name} --yes-i-really-really-mean-it]
如果你给自建的存储池创建了定制的规则集,你不需要存储池时最好删除它。如果你曾严格地创建了用户及其权限给一个存储池,但存储池已不存在,最好也删除那些用户
[root@client ~]# ceph osd pool delete cephfs_metadata cephfs_metadata --yes-i-really-really-mean-it
pool 'cephfs_metadata' removed
[root@client ~]# ceph osd pool delete cephfs_pool cephfs_pool --yes-i-really-really-mean-it
pool 'cephfs_pool' removed
第4步: 再次mds服务再次启动
[root@node1 ~]# systemctl start ceph-mds.target
[root@node2 ~]# systemctl start ceph-mds.target
[root@node3 ~]# systemctl start ceph-mds.target
查看存储池统计信息¶
要查看某存储池的使用统计信息,执行命令:
rados df
六、创建Ceph块存储
块是一个字节序列(例如,一个 512 字节的数据块)。基于块的存储接口是最常见的存储数据方法,它们基于旋转介质,像硬盘、 CD 、软盘、甚至传统的 9 磁道磁带。无处不在的块设备接口使虚拟块设备成为与 Ceph 这样的海量存储系统交互的理想之选。
Ceph 块设备是精简配置的、大小可调且将数据条带化存储到集群内的多个 OSD 。 Ceph 块设备利用 RADOS 的多种能力,如快照、复制和一致性。 Ceph 的 RADOS 块设备( RBD )使用内核模块或 librbd 库与 OSD 交互。
http://docs.ceph.org.cn/rbd/rbd/
https://amito.me/2018/Using-RBD-in-Ceph/
https://blog.csdn.net/weixin_666888/article/details/108678117
创建块存储并使用
确认你使用了合适的内核版本,详情见操作系统 推荐。
lsb_release -a
uname -r
在管理节点上,通过 ceph-deploy 把 Ceph 安装到 ceph-client 节点。
ceph-deploy install ceph-client
第1步: 在node1上同步配置文件到client
在管理节点上,用 ceph-deploy 把 Ceph 配置文件和 ceph.client.admin.keyring 拷贝到 ceph-client
ceph-deploy 工具会把密钥环复制到 /etc/ceph 目录,要确保此密钥环文件有读权限(如 sudo chmod +r /etc/ceph/ceph.client.admin.keyring )。
--overwrite-conf 覆盖远程主机上的已有配置文件(若存在)。
[root@node1 ceph]# ceph-deploy --overwrite-conf admin client
第2步:建立存储池,并初始化
注意:在客户端操作
[root@client ~]# ceph osd pool create rbd_pool 128
pool 'rbd_pool' created
初始化pool
[root@client ~]# ceph df
[root@client ~]# rbd pool init rbd_pool
[root@client ~]# rbd ls rbd_pool
第3步:创建一个存储卷(我这里卷名为volume1,大小为5000M)
注意: volume1的专业术语为image, 我这里叫存储卷方便理解
rbd 是个操纵 rados 块设备( RBD )映像的工具 RBD 映像是简单的块设备,它被条带化成小块对象后存储于 RADOS 对象存储集群
-p pool-name, --pool pool-name
在指定存储池下操作,大多数命令都得指定。
[root@client ~]# rbd create volume1 --pool rbd_pool --size 5000
[root@client ~]# rbd ls rbd_pool
volume1
[root@client ~]# rbd info volume1 -p rbd_pool
rbd image 'volume1': 可以看到volume1为rbd image
size 4.9 GiB in 1250 objects
order 22 (4 MiB objects)
id: 149256b8b4567
block_name_prefix: rbd_data.149256b8b4567
format: 2 格式有1和2两种,现在是2
features: layering, exclusive-lock, object-map, fast-diff, deep-flatten 特性
op_features:
flags:
create_timestamp: Sat Aug 17 19:47:51 2019
第4步: 将创建的卷映射成块设备
- 因为rbd镜像的一些特性,OS kernel并不支持,所以映射报错
rbd map {pool-name}/{image-name}
[root@client ~]# rbd map rbd_pool/volume1
rbd: sysfs write failed
RBD image feature set mismatch. You can disable features unsupported by the kernel with "rbd feature disable rbd_pool/volume1 object-map fast-diff deep-flatten".
In some cases useful info is found in syslog - try "dmesg | tail".
rbd: map failed: (6) No such device or address
- 解决方法: disable掉相关特性或升级内核
[root@client ~]# rbd feature disable rbd_pool/volume1 exclusive-lock object-map fast-diff deep-flatten
- 再次映射
[root@client ~]# rbd map rbd_pool/volume1
/dev/rbd0
取消块设备映射 rbd unmap /dev/rbd/{poolname}/{imagename}
第5步: 查看映射(如果要取消映射, 可以使用rbd unmap /dev/rbd0)
[root@client ~]# rbd showmapped
id pool image snap device
0 rbd_pool volume1 - /dev/rbd0
[root@client ~]# lsblk
第6步: 格式化,挂载
[root@client ~]# mkfs.xfs /dev/rbd0
[root@client ~]# rbd list 列出所有的映像
[root@client ~]# mount /dev/rbd0 /mnt/
[root@client ~]# df -h |tail -1
/dev/rbd0 4.9G 33M 4.9G 1% /mnt
可自行验证读写
注意: 块存储是不能实现同读同写的,请不要两个客户端同时挂载进行读写
在远程服务器上挂载 Ceph RBD 块设备
https://amito.me/2020/Map-and-Mount-Ceph-RBD-on-Remote-Servers/
块存储扩容与裁减
块设备命令:http://docs.ceph.org.cn/rbd/rados-rbd-cmds/#id5
在线扩容
经测试,分区后/dev/rbd0p1不能在线扩容,直接使用/dev/rbd0才可以
扩容成8000M
[root@client ~]# rbd resize --size 8000 rbd_pool/volume1
[root@client ~]# rbd info rbd_pool/volume1 |grep size
size 7.8 GiB in 2000 objects
查看大小,并没有变化
[root@client ~]# df -h |tail -1
/dev/rbd0 4.9G 33M 4.9G 1% /mnt
[root@client ~]# xfs_growfs -d /mnt/
再次查看大小,在线扩容成功
[root@client ~]# df -h |tail -1
/dev/rbd0 7.9G 33M 7.9G 1% /mnt
块存储裁减
不能在线裁减.裁减后需重新格式化再挂载,所以请提前备份好数据.
再裁减回5000M
[root@client ~]# rbd resize --size 5000 rbd_pool/volume1 --allow-shrink
重新格式化挂载
[root@client ~]# umount /mnt/
[root@client ~]# mkfs.xfs -f /dev/rbd0
[root@client ~]# mount /dev/rbd0 /mnt/
再次查看,确认裁减成功
[root@client ~]# df -h |tail -1
/dev/rbd0 4.9G 33M 4.9G 1% /mnt
删除块存储方法
[root@client ~]# df -h
[root@client ~]# umount /mnt/
[root@client ~]# rbd unmap /dev/rbd0
[root@client ~]# rbd showmapped
[root@client ~]# ceph osd pool delete rbd_pool rbd_pool --yes-i-really-really-mean-it
pool 'rbd_pool' removed
七、Ceph对象存储
http://docs.ceph.org.cn/radosgw/config/#keyring
RGW同时提供了S3和Swift兼容的接口,因此只要启动了RGW服务,就可以像使用S3或Swift那样访问RGW的object和bucket了。
bucket:存储桶,用来管理对象的容器。https://www.sohu.com/a/120065877_468741
什么是对象存储?
对象存储(云存储)是面向对象/文件的、海量的互联网存储。对象存储里的对象是经过封装了的文件,在对象存储系统里, 不能直接打开/修改文件,但可以像ftp一样上传文件,下载文件等。另外,对象存储没有像文件系统那样有一个很多层级 的文件结构,而是只有一个“桶”的概念(也就是存储空间),“桶”里面全部都是对象,是一种非常扁平化的存储方式。 其最大的特点就是它的对象名称就是一个域名地址,一旦对象被设置为“公开”,所有网民都可以访问到。对象存储最主 流的使用场景,就是存储网站、移动app等互联网/移动互联网应用的静态内容(视频、图片、文件、软件安装包等等)。
user:对象存储的使用者,默认情况下,一个用户只能创建1000个存储桶。
bucket:存储桶,用来管理对象的容器。
object:对象,泛指一个文档、图片或视频文件等,尽管用户可以直接上传一个目录,但是ceph并不按目录层级结构保存对象, ceph所有的对象扁平化的保存在bucket中
安装 Ceph 对象网关
# ceph-deploy install --rgw <client-node> [<client-node> ...]
新建 Ceph 对象网关实例
# ceph-deploy rgw create
测试
第1步: 在node1上创建rgw
[root@node1 ceph]# ceph-deploy rgw create node1
[root@node1 ceph]# ceph -s
[root@node1 ceph]# lsof -i:7480
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
radosgw 6748 ceph 40u IPv4 49601 0t0 TCP *:7480 (LISTEN)

第2步: 在客户端测试连接对象网关
创建一个测试用户,需要在部署节点使用ceph-deploy admin client同步配置文件给client
[root@client ~]# radosgw-admin user create --uid="testuser" --display-name="First User"
{
"user_id": "testuser",
"display_name": "First User",
"email": "",
"suspended": 0,
"max_buckets": 1000,
"auid": 0,
"subusers": [],
"keys": [
{
"user": "testuser",
"access_key": "36ROCI84S5NSP4BPYL01",
"secret_key": "jBOKH0v6J79bn8jaAF2oaWU7JvqTxqb4gjerWOFW"
}
],
"swift_keys": [],
"caps": [],
"op_mask": "read, write, delete",
"default_placement": "",
"placement_tags": [],
"bucket_quota": {
"enabled": false,
"check_on_raw": false,
"max_size": -1,
"max_size_kb": 0,
"max_objects": -1
},
"user_quota": {
"enabled": false,
"check_on_raw": false,
"max_size": -1,
"max_size_kb": 0,
"max_objects": -1
},
"temp_url_keys": [],
"type": "rgw",
"mfa_ids": []
}
上面一大段主要有用的为access_key与secret_key,用于连接对象存储网关
[root@client ~]# radosgw-admin user create --uid='testuser' --display-name='First User' |grep -E 'access_key|secret_key'
"access_key": "36ROCI84S5NSP4BPYL01",
"secret_key": "jBOKH0v6J79bn8jaAF2oaWU7JvqTxqb4gjerWOFW"
然后你得验证一下刚创建的用户是否能访问网关。
测试 S3 访问
你需要写一个 Python 测试脚本,并运行它以验证 S3 访问. S3 访问测试脚本将会连接 radosgw, 然后新建一个新的 bucket 再列出所有的 buckets.aws_access_key_id 和 aws_secret_access_key 的值就是前面radosgw_admin 命令的返回值中的 access_key 和 secret_key.
执行下面的步骤:
首先你需要安装
python-boto包.
对于基于 Debian 的发行版请执行:sudo apt-get install python-boto对于基于 RPM 的发行版请执行:
sudo yum install python-boto新建 Python 脚本:
vi s3test.py添加下面的内容到该文件中:
import boto import boto.s3.connection access_key = 'I0PJDPCIYZ665MW88W9R' secret_key = 'dxaXZ8U90SXydYzyS5ivamEP20hkLSUViiaR+ZDA' conn = boto.connect_s3( aws_access_key_id = access_key, aws_secret_access_key = secret_key, host = '{hostname}', is_secure=False, calling_format = boto.s3.connection.OrdinaryCallingFormat(), ) bucket = conn.create_bucket('my-new-bucket') for bucket in conn.get_all_buckets(): print "{name}\t{created}".format( name = bucket.name, created = bucket.creation_date, )将
{hostname}替换为你配置了网关服务的主机的主机名,比如gateway host.运行这个脚本:
python s3test.py输出类似下面的内容:
my-new-bucket 2015-02-16T17:09:10.000Z
S3连接ceph对象网关
Amazon S3是一种面向Internet的对象存储服务.我们这里可以使用s3工具连接ceph的对象存储进行操作
第1步: 客户端安装s3cmd工具,并编写ceph连接配置文件
[root@client ~]# yum install s3cmd
创建并编写下面的文件,key文件对应前面创建测试用户的key
[root@client ~]# vim /root/.s3cfg
[default]
access_key = 36ROCI84S5NSP4BPYL01
secret_key = jBOKH0v6J79bn8jaAF2oaWU7JvqTxqb4gjerWOFW
host_base = 10.1.1.11:7480
host_bucket = 10.1.1.11:7480/%(bucket)
cloudfront_host = 10.1.1.11:7480
use_https = False
第2步: 命令测试
列出bucket,可以查看到先前测试创建的my-new-bucket
[root@client ~]# s3cmd ls
2019-01-05 23:01 s3://my-new-bucket
再建一个桶
[root@client ~]# s3cmd mb s3://test_bucket
上传文件到桶
[root@client ~]# s3cmd put /etc/fstab s3://test_bucket
upload: '/etc/fstab' -> 's3://test_bucket/fstab' [1 of 1]
501 of 501 100% in 1s 303.34 B/s done
下载到当前目录
[root@client ~]# s3cmd get s3://test_bucket/fstab
更多命令请见参考命令帮助
[root@client ~]# s3cmd --help
https://www.jianshu.com/p/583d880b8a15
八、ceph dashboard(拓展)
ceph luminous版本 新功能之内置dashboard
Ceph Dashboard全功能安装集成: https://blog.51cto.com/renlixing/2487852?source=dra
通过ceph dashboard(仪表盘)完成对ceph存储系统可视化监视。
第1步:查看集群状态确认mgr的active节点
[root@node1 ~]# ceph mgr version
{
ceph version 13.2.10 (564bdc4ae87418a232fc901524470e1a0f76d641) mimic (stable)
}
[root@node1 ~]# ceph -s
cluster:
id: 6788206c-c4ea-4465-b5d7-ef7ca3f74552
health: HEALTH_OK
services:
mon: 3 daemons, quorum node1,node2,node3
mgr: node1(active), standbys: node3, node2 确认mgr的active节点为 node1
osd: 4 osds: 4 up, 4 in
rgw: 1 daemon active
data:
pools: 6 pools, 48 pgs
objects: 197 objects, 2.9 KiB
usage: 596 MiB used, 3.4 GiB / 4.0 GiB avail
pgs: 48 active+clean
[root@node1 ~]# systemctl --all | grep ceph-mrg
查看img module 帮助及模块信息
[root@node1 ~]# ceph mgr module --help
[root@node1 ~]# ceph mgr module ls
第2步:开启dashboard模块
mgr 在哪台主机上面启动的dashboard模块就在哪台主机上面开启
[root@node1 ~]# ceph mgr module enable dashboard
[root@node1 ~]# ceph mgr module ls
第3步:创建自签名证书
[root@node1 ~]# ceph dashboard create-self-signed-cert
Self-signed certificate created
# ceph config set mgr mgr/dashboard/ssl false 禁用SSL。
第4步: 生成密钥对,并配置给ceph mgr
[root@node1 ~]# mkdir /etc/mgr-dashboard
[root@node1 ~]# cd /etc/mgr-dashboard/
[root@node1 mgr-dashboard]# openssl req -new -nodes -x509 -subj "/O=IT-ceph/CN=cn" -days 365 -keyout dashboard.key -out dashboard.crt -extensions v3_ca
Generating a 2048 bit RSA private key
.+++
.....+++
writing new private key to 'dashboard.key'
-----
[root@node1 mgr-dashboard]# ls
dashboard.crt dashboard.key
第5步: 在ceph集群的active mgr节点上(我这里为node1)配置mgr services
使用dashboard服务,主要配置dashboard使用的IP及Port
[root@node1 mgr-dashboard]# ceph mgr services
可修改为
[root@node1 mgr-dashboard]# ceph config set mgr mgr/dashboard/server_addr 10.1.1.11
[root@node1 mgr-dashboard]# ceph config set mgr mgr/dashboard/server_port 8080
第6步: 重启dashboard模块,并查看访问地址
[root@node1 mgr-dashboard]# ceph mgr module disable dashboard
[root@node1 mgr-dashboard]# ceph mgr module enable dashboard
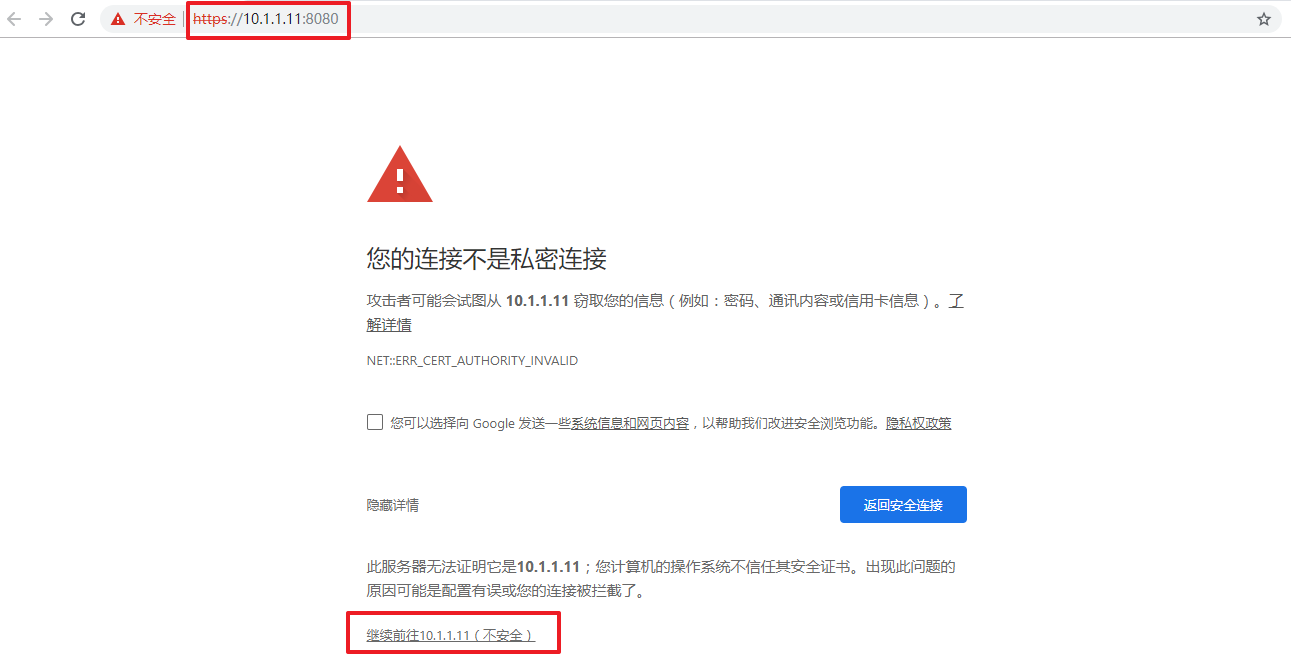
[root@node1 mgr-dashboard]# ceph mgr services
{
"dashboard": "https://10.1.1.11:8080/"
}
第7步:设置访问web页面用户名和密码
[root@node1 mgr-dashboard]# ceph dashboard set-login-credentials daniel daniel123
Username and password updated
第8步:通过本机或其它主机访问
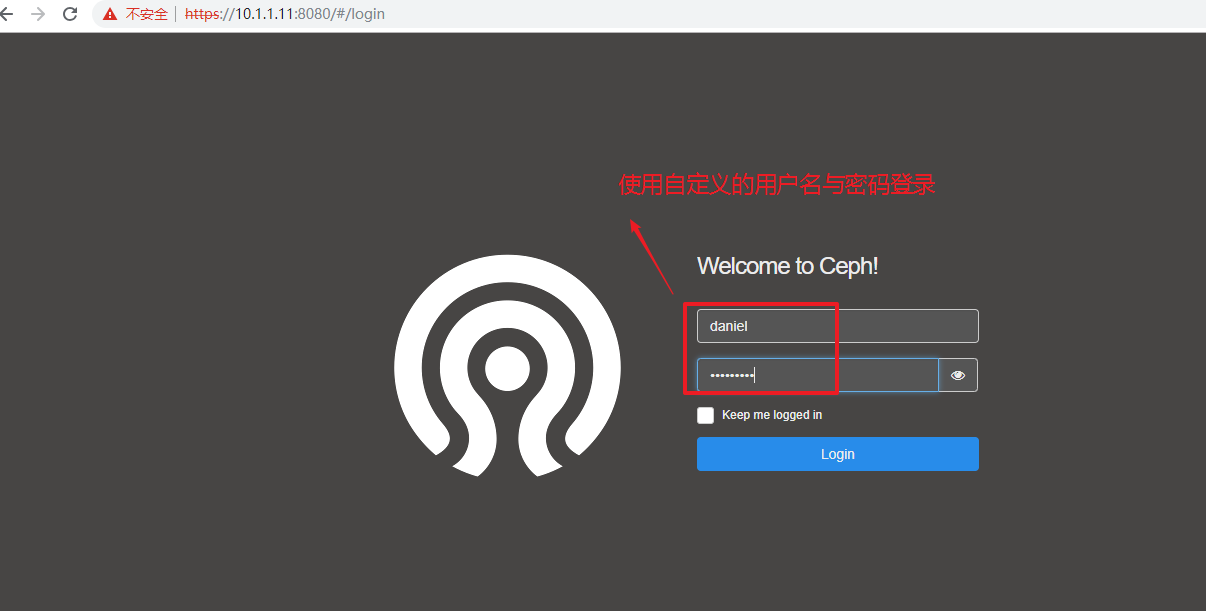

第九步:若通过外网访问,则在有外网IP的机器上配置nginx 服务做https转发(不需要则忽略)

九、ceph对象存储结合owncloud打造云盘(拓展)
https://www.pianshen.com/article/494771191/
ownCloud是一个开源免费专业的私有存储项目,它能帮你快速在个人电脑或服务器上架设一套专属的私有文件同步网盘,可以像百度网盘那样实现跨平台同步、共享、版本控制、团队协作等等。
ownCloud能让你将所有的文件掌握在自己的手中,只要你的设备性能和空间充足,那么用起来几乎没有任何限制。
ownCloud跨平台支持window、mac、android、ios、linux等平台,而且还提供了网页版和WebDAV 形式访问,因此你可以在任何电脑、手机上都能轻松获取你的文件了。

1,在ceph的客户端上准备好bucket和相关的连接key
[root@client ~]# s3cmd mb s3://owncloud
Bucket 's3://owncloud/' created
[root@client ~]# cat /root/.s3cfg
[default]
access_key = 36ROCI84S5NSP4BPYL01
secret_key = jBOKH0v6J79bn8jaAF2oaWU7JvqTxqb4gjerWOFW
host_base = 10.1.1.11:7480
host_bucket = 10.1.1.11:7480/%(bucket)
cloudfront_host = 10.1.1.11:7480
use_https = False
2, 在client端安装owncloud云盘运行所需要的web环境
owncloud需要web服务器和php支持. 目前最新版本owncloud需要php7.x版本,在这里我们为了节省时间,使用rpm版安装
[root@client ~]# yum install httpd mod_ssl php-mysql php php-gd php-xml php-mbstring -y
[root@client ~]# systemctl restart httpd
3, 上传owncloud软件包, 并解压到httpd家目录
[root@client ~]# tar xf owncloud-9.0.1.tar.bz2 -C /var/www/html/
[root@client ~]# chown apache.apache -R /var/www/html/
需要修改为运行web服务器的用户owner,group,否则后面写入会出现权限问题
4, 通过浏览器访问http:10.1.1.14/owncloud,进行配置






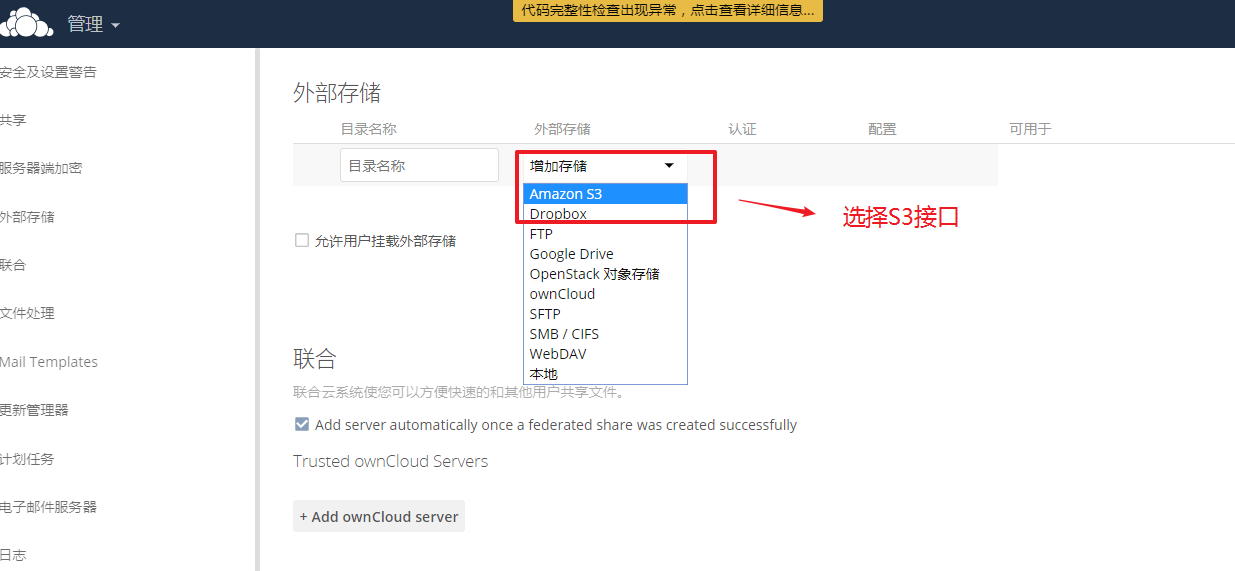


5, 文件上传下载测试
[root@client ~]# s3cmd put /etc/fstab s3://owncloud
upload: '/etc/fstab' -> 's3://owncloud/fstab' [1 of 1]
501 of 501 100% in 0s 6.64 kB/s done
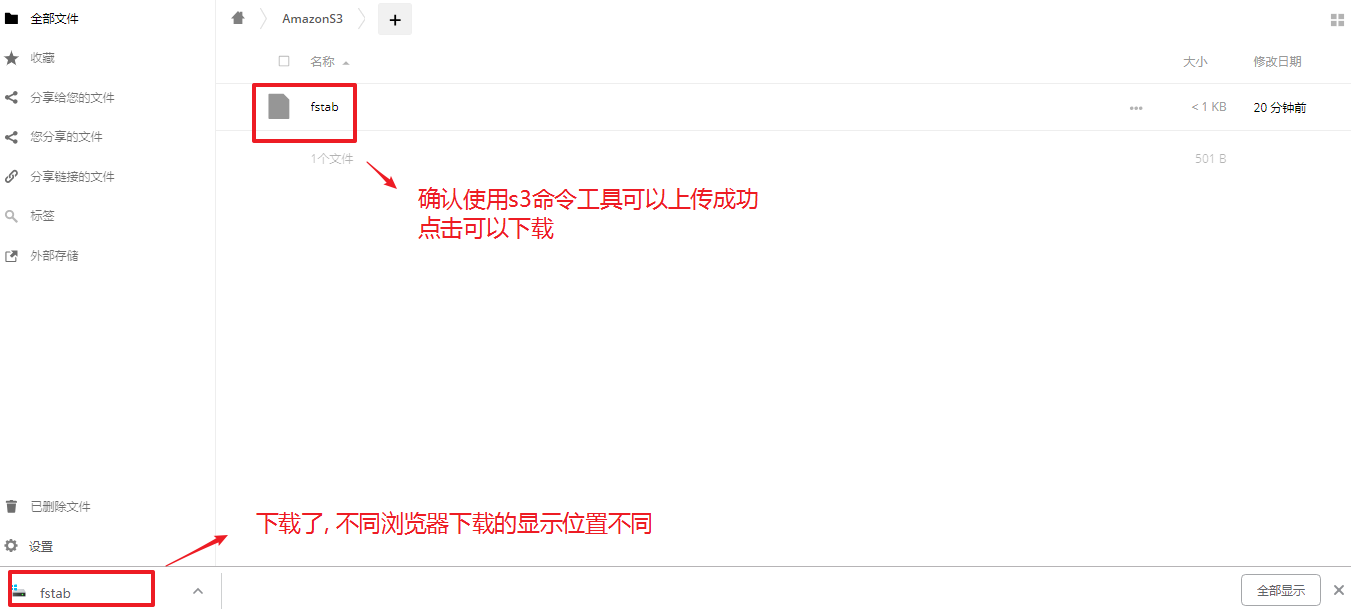

因为默认owncloud上传文件有限制,不能超过2M。所以需要修改
[root@client ~]# vim /var/www/html/owncloud/.htaccess
<IfModule mod_php5.c>
php_value upload_max_filesize 2000M 修改调大
php_value post_max_size 2000M 修改调大
[root@client ~]# vim /etc/php.ini
post_max_size = 2000M 修改调大
upload_max_filesize = 2000M 修改调大
[root@client ~]# systemctl restart httpd

若有收获,就点个赞吧
0 人点赞
