CAS
CAS(Compare And Swap,比较与交换),通常指的是这样一种原子操作:针对一个变量,首先比较它的内存值与某个期望值是否相同,如果相同,就给它赋一个新值。
CAS 的逻辑用伪代码描述如下:
if (value == expectedValue) {value = newValue;}
以上伪代码描述了一个由比较和赋值两阶段组成的复合操作,CAS可以看作是它们合并后的整体——一个不可分割的原子操作,并且其原子性是直接在硬件层面得到保障的。
CAS可以看做是乐观锁(对比数据库的悲观、乐观锁)的一种实现方式,Java原子类中的递增操作就通过CAS自旋实现的。CAS是一种无锁算法,在不使用锁(没有线程被阻塞)的情况下实现多线程之间的变量同步。 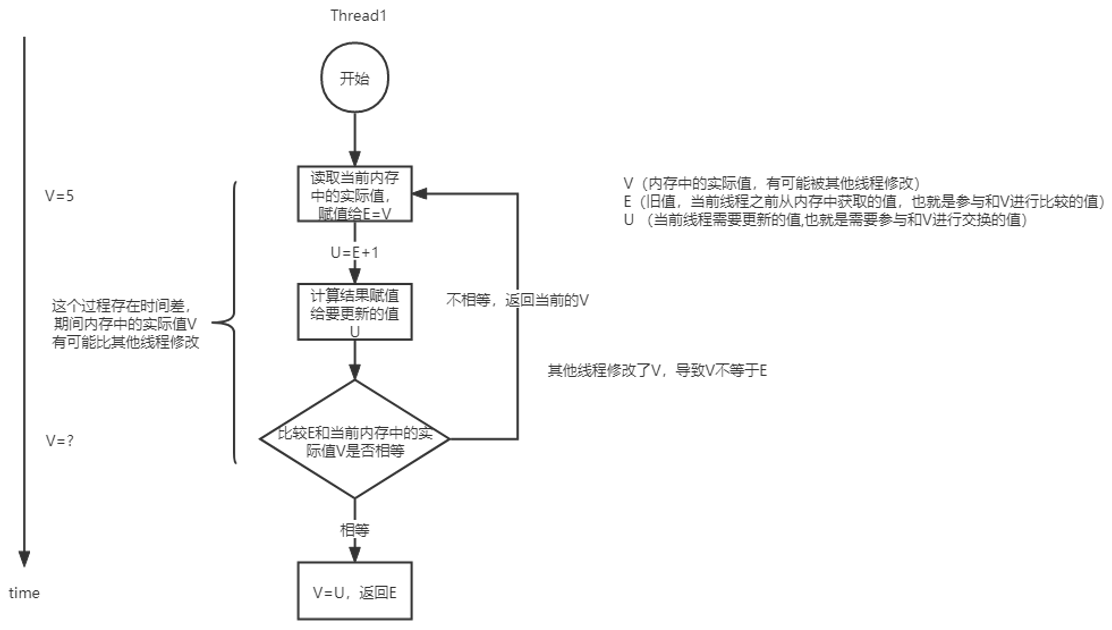
在Java中,CAS操作是由Unsafe类提供支持的,该类定义了三种针对不同类型变量的CAS操作,如图  它们都是native方法,由Java虚拟机提供具体实现,这意味着不同的Java虚拟机对它们的实现可能会略有不同。
它们都是native方法,由Java虚拟机提供具体实现,这意味着不同的Java虚拟机对它们的实现可能会略有不同。
以compareAndSwapInt为例,Unsafe的compareAndSwapInt方法接收4个参数,分别是:对象实例、内存偏移量、字段期望值、字段新值。该方法会针对指定对象实例中的相应偏移量的字段执行CAS操作。
CAS源码分析
Hotspot虚拟机对compareAndSwapInt方法的实现如下:
#unsafe.cppUNSAFE_ENTRY(jboolean, Unsafe_CompareAndSwapInt(JNIEnv *env, jobject unsafe, jobject obj, jlong offset, jint e, jint x))UnsafeWrapper("Unsafe_CompareAndSwapInt");oop p = JNIHandles::resolve(obj);// 根据偏移量,计算value的地址jint* addr = (jint *) index_oop_from_field_offset_long(p, offset);// Atomic::cmpxchg(x, addr, e) cas逻辑 x:要交换的值 e:要比较的值//cas成功,返回期望值e,等于e,此方法返回true//cas失败,返回内存中的value值,不等于e,此方法返回falsereturn (jint)(Atomic::cmpxchg(x, addr, e)) == e;UNSAFE_END
核心逻辑在Atomic::cmpxchg方法中,这个根据不同操作系统和不同CPU会有不同的实现。这里以linux_64x的为例,查看Atomic::cmpxchg的实现
#atomic_linux_x86.inline.hppinline jint Atomic::cmpxchg (jint exchange_value, volatile jint* dest, jint compare_value) {//判断当前执行环境是否为多处理器环境int mp = os::is_MP();//LOCK_IF_MP(%4) 在多处理器环境下,为 cmpxchgl 指令添加 lock 前缀,以达到内存屏障的效果//cmpxchgl 指令是包含在 x86 架构及 IA‐64 架构中的一个原子条件指令,//它会首先比较 dest 指针指向的内存值是否和 compare_value 的值相等,//如果相等,则双向交换 dest 与 exchange_value,否则就单方面地将 dest 指向的内存值交给exchange_value。//这条指令完成了整个 CAS 操作,因此它也被称为 CAS 指令。__asm__ volatile (LOCK_IF_MP(%4) "cmpxchgl %1,(%3)": "=a" (exchange_value): "r" (exchange_value), "a" (compare_value), "r" (dest), "r" (mp): "cc", "memory");return exchange_value;}
Atomic::cmpxchg这个函数最终返回值是exchange_value,也就是说,如果cmpxchgl执行时compare_value和dest指针指向内存值相等则会使得dest指针指向内存值变成exchange_value,最终eax存的compare_value赋值给了exchange_value变量,即函数最终返回的值是原先的compare_value。此时Unsafe_CompareAndSwapInt的返回值(jint) (Atomic::cmpxchg(x, addr, e)) == e就是true,表明CAS成功。如果cmpxchgl执行时compare_value和(dest)不等则会把当前dest指针指向内存的值写入eax,最终输出时赋值给exchange_value变量作为返回值,导致(jint)(Atomic::cmpxchg(x, addr, e)) == e得到false,表明CAS失败。
注:现代处理器指令集架构基本上都会提供CAS指令,例如 x86 和 IA-64 架构中的 cmpxchgl 指令 和 comxchgq 指令,sparc 架构中的 cas 指令和 casx 指令。
不管是Hotspot中的Atomic::cmpxchg方法,还是Java中的compareAndSwapInt方法,它们本质上都是对相应平台的CAS指令的一层简单封装(因此CAS不需要切换到内核态)。CAS指令作为一种硬件原语,有着天然的原子性,这也正是CAS的价值所在。
CAS缺陷
CAS 虽然高效地解决了原子操作,但是还是存在一些缺陷的,主要表现在三个方面:
1.自旋 CAS 长时间地不成功,则会给 CPU 带来非常大的开销
2.只能保证一个共享变量原子操作
3.ABA 问题
ABA问题及其解决方案
CAS算法实现一个重要前提需要取出内存中某时刻的数据,而在下一时刻比较并替换,那么在这个时间差内会导致数据的变化。
什么是ABA问题
当有多个线程对一个原子类进行操作的时候,某个线程在短时间内将原子类的值A修改为B,又马上将其修改为A,此时其他线程不感知,还是会修改成功。 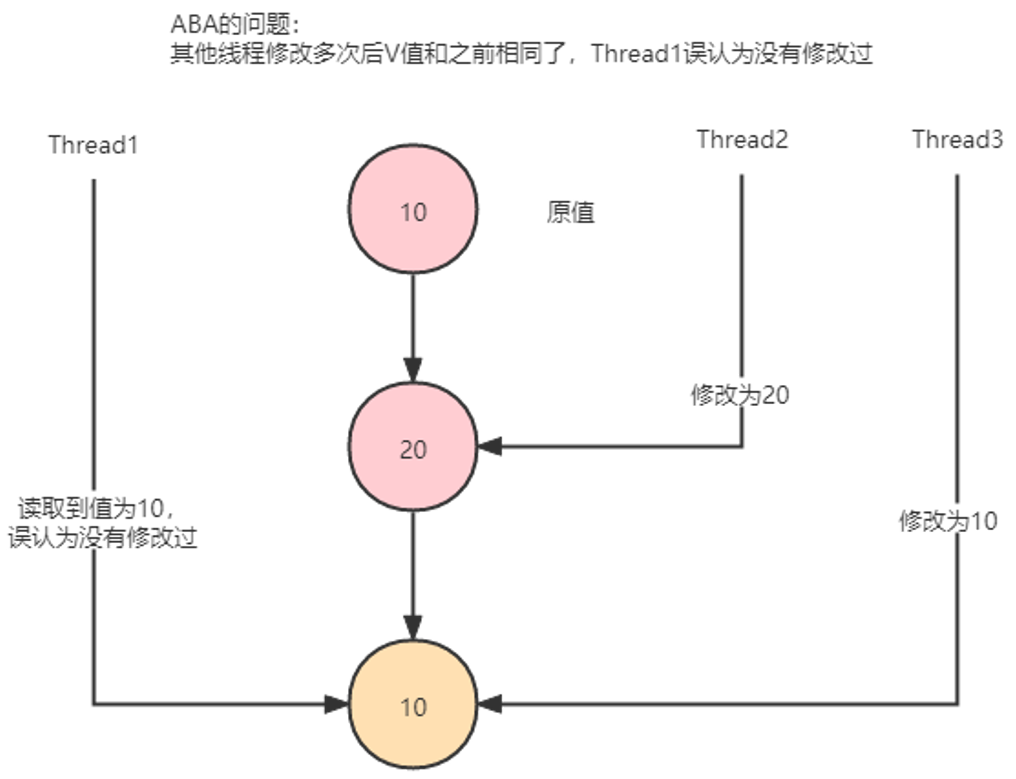
ABA问题解决方案
数据库有个锁称为乐观锁,是一种基于数据版本实现数据同步的机制,每次修改一次数据,版本就会进行累加。 同样,Java也提供了相应的原子引用类AtomicStampedReference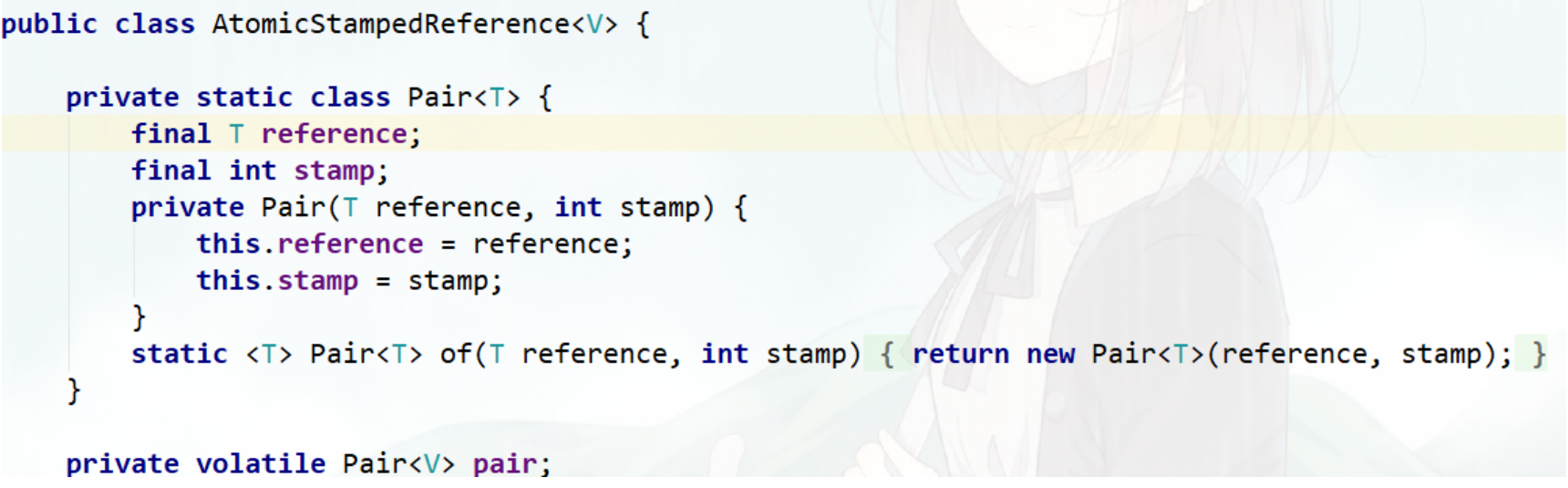
reference即我们实际存储的变量,stamp是版本,每次修改可以通过+1保证版本唯一性。这样就可以保证每次修改后的版本也会往上递增。
补充:AtomicMarkableReference可以理解为上面AtomicStampedReference的简化版,就是不关心修改过几次,仅仅关心是否修改过。因此变量mark是boolean类型,仅记录值是否有过修改。 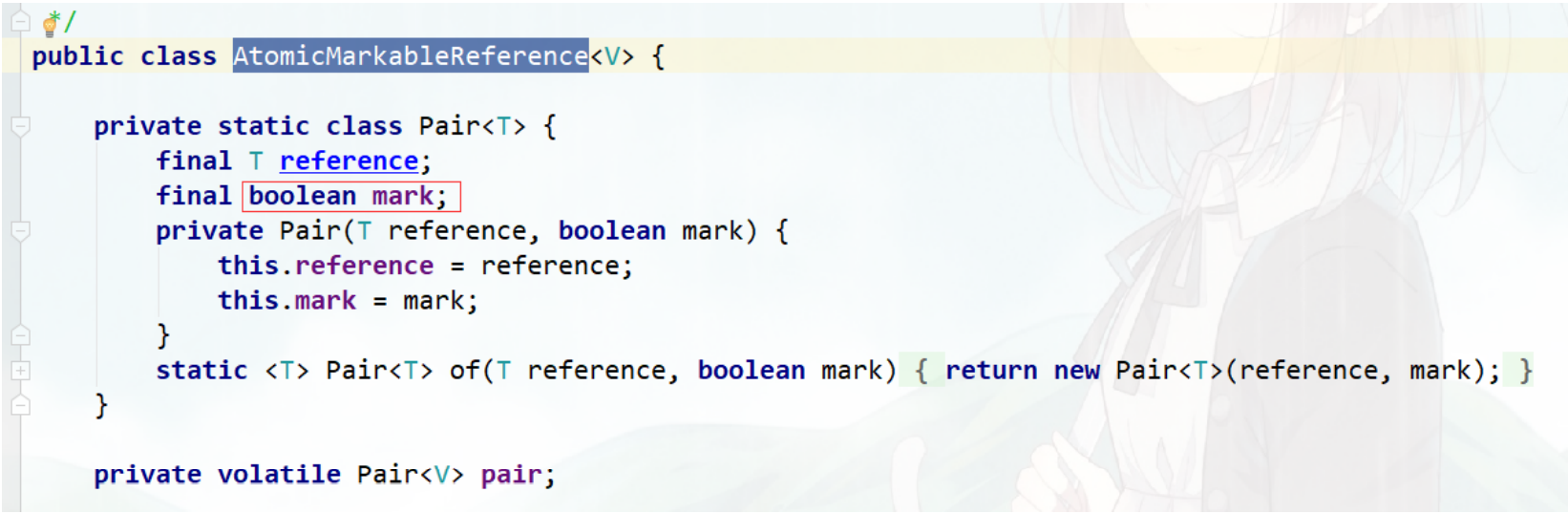
总结
Java关键字volatile:
1.可见性: JVM层面通过lock前缀指令让缓存行锁定,将新值刷回主存,然后这个指令还会触发MESI协议,其中就有让缓存副本失效的功能,这样线程就会重新从主存中读值到缓存副本中.
2.有序性: JVM源码层面通过c++的关键字volatile禁止了重排序的作用保障了有序性
3.原子性: 对非复合操作的单个volatile变量的读写具备原子性,对于创建对象,volatile++等复合操作是保证不了的.其中对于volatile修饰的long,double类型的变量,32位机器下会进行分步操作,无法保证原子性,因为寄存器一次只能放32位.但是64位机器下就能保证.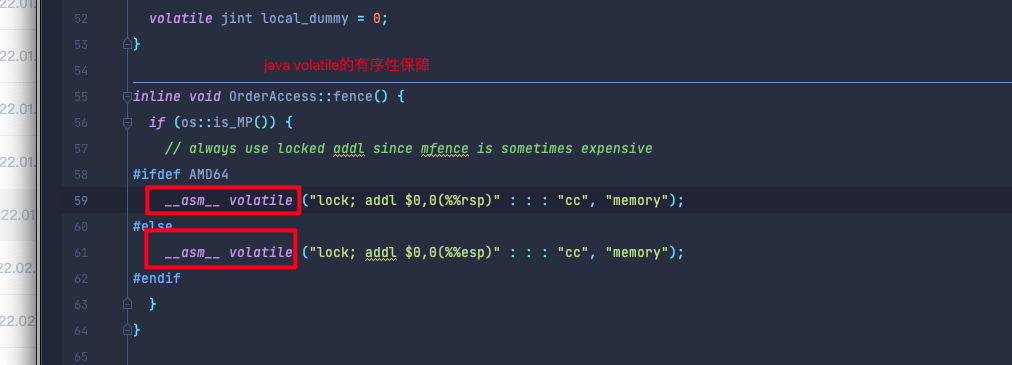
JVM层面的CAS:
原子性: 在单核处理器下是通过cmpxchgl来保证的,在多核处理器下无法保证了,通过lock前缀的加持变为lock cmpxchgl保证了原子性.因为lock前缀指令具有作用就是让后续指令具有原子性.
有序性: 通过C++关键字volatile禁止重排序保证了有序性
其中可见性无法保证,对于Java CAS API层面,比如Atomic类中需要将共享变量通过volatile关键字修饰保证可见性
lock前缀的作用:
1.保证后续指令的原子性,比如lock cmpxchgl
2.缓存行锁定,将新值刷回主存
3.触发MESI协议,结合缓存行锁定保障了可见性
C++关键字volatile作用:
1.禁止重排序
2.防止代码被优化掉
Atomic原子操作类
在并发编程中很容易出现并发安全的问题,有一个很简单的例子就是多线程更新变量i=1,比如多个线程执行i++操作,就有可能获取不到正确的值,而这个问题,最常用的方法是通过Synchronized进行控制来达到线程安全的目的。但是由于synchronized是采用的是悲观锁策略,并不是特别高效的一种解决方案。实际上,在J.U.C下的atomic包提供了一系列的操作简单, 性能高效,并能保证线程安全的类去更新基本类型变量,数组元素,引用类型以及更新对象中的字段类型。atomic包下的这些类都是采用的是乐观锁策略去原子更新数据,在java中则是使用CAS操作具体实现。
在java.util.concurrent.atomic包里提供了一组原子操作类:
基本类型:AtomicInteger、AtomicLong、AtomicBoolean;
引用类型:AtomicReference、AtomicStampedRerence、AtomicMarkableReference;
数组类型:AtomicIntegerArray、AtomicLongArray、AtomicReferenceArray;
对象属性原子修改器:AtomicIntegerFieldUpdater、AtomicLongFieldUpdater、AtomicReferenceFieldUpdater;
原子类型累加器(jdk1.8增加的类):DoubleAccumulator、DoubleAdder、 LongAccumulator、LongAdder、Striped64。
原子更新基本类型
以AtomicInteger为例总结常用的方法
//以原子的方式将实例中的原值加1,返回的是自增前的旧值;public final int getAndIncrement() { //incrementAndGetreturn unsafe.getAndAddInt(this, valueOffset, 1);}//getAndSet(int newValue):将实例中的值更新为新值,并返回旧值;public final boolean getAndSet(boolean newValue) {boolean prev;do {prev = get();} while (!compareAndSet(prev, newValue));return prev;}//incrementAndGet() :以原子的方式将实例中的原值进行加1操作,并返回最终相加后的结果;public final int incrementAndGet() {return unsafe.getAndAddInt(this, valueOffset, 1) + 1;}//addAndGet(int delta) :以原子方式将输入的数值与实例中原本的值相加,并返回最后的结果;public final int addAndGet(int delta) {return unsafe.getAndAddInt(this, valueOffset, delta) + delta;}

incrementAndGet()方法通过CAS自增实现,如果CAS失败,自旋直到成功+1 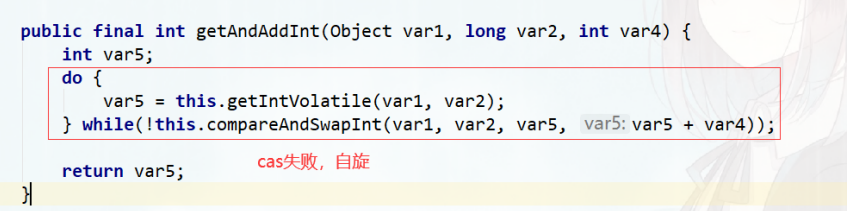
原子更新数组类型
AtomicIntegerArray为例总结常用的方法
//addAndGet(int i, int delta):以原子更新的方式将数组中索引为i的元素与输入值相加;public final int addAndGet(int i, int delta) {return getAndAdd(i, delta) + delta;}//getAndIncrement(int i):以原子更新的方式将数组中索引为i的元素自增加1;public final int getAndIncrement(int i) {return getAndAdd(i, 1);}//compareAndSet(int i, int expect, int update):将数组中索引为i的位置的元素进行更新public final boolean compareAndSet(int i, int expect, int update) {return compareAndSetRaw(checkedByteOffset(i), expect, update);}
原子更新引用类型
AtomicReference作用是对普通对象的封装,它可以保证你在修改对象引用时的线程安全性。
public class AtomicReferenceTest {public static void main( String[] args ) {User user1 = new User("张三", 23);User user2 = new User("李四", 25);User user3 = new User("王五", 20);//初始化为 user1AtomicReference<User> atomicReference = new AtomicReference<>();atomicReference.set(user1);//把 user2 赋给 atomicReferenceatomicReference.compareAndSet(user1, user2);System.out.println(atomicReference.get());//把 user3 赋给 atomicReferenceatomicReference.compareAndSet(user1, user3);System.out.println(atomicReference.get());}}@Data@AllArgsConstructorclass User {private String name;private Integer age;}
对象属性原子修改器
AtomicIntegerFieldUpdater可以线程安全地更新对象中的整型变量。
LongAdder/DoubleAdder
AtomicLong是利用了底层的CAS操作来提供并发性的,比如addAndGet方法: 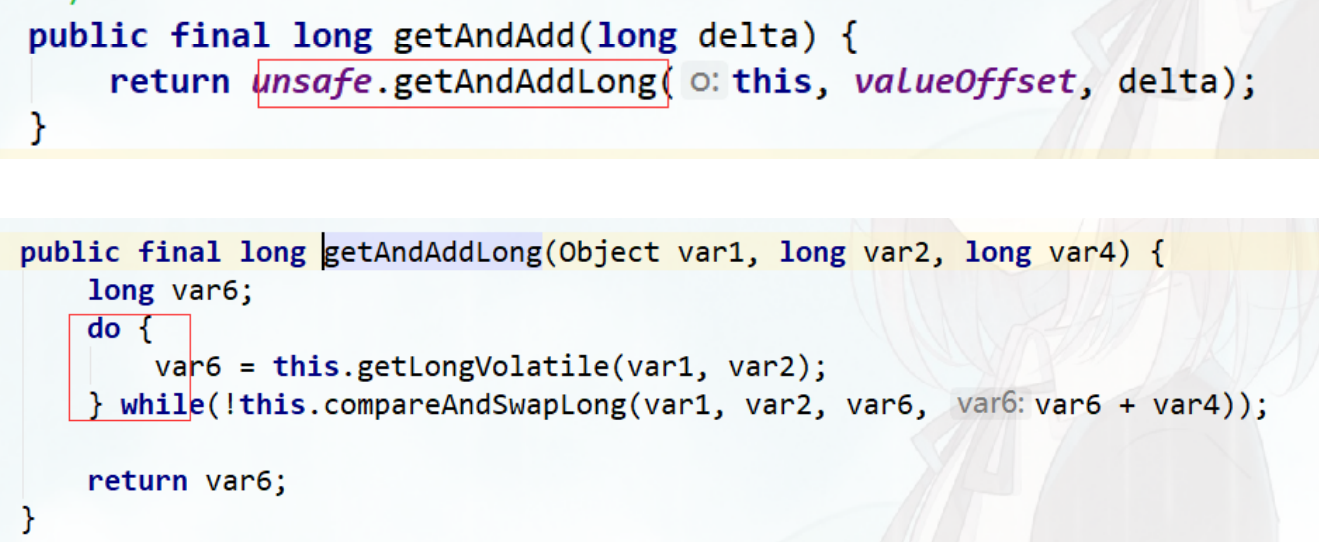
上述方法调用了Unsafe类的getAndAddLong方法,该方法内部是个native方法,它的逻辑是采用自旋的方式不断更新目标值,直到更新成功。
在并发量较低的环境下,线程冲突的概率比较小,自旋的次数不会很多。但是,高并发环境下,N个线程同时进行自旋操作,会出现大量失败并不断自旋的情况,此时AtomicLong的自旋会成为瓶颈。
这就是LongAdder引入的初衷——解决高并发环境下AtomicInteger,AtomicLong的自旋瓶颈问题。
性能测试
public class LongAdderTest {
public static void main(String[] args) {
testAtomicLongVSLongAdder(10, 10000);
System.out.println("==================");
testAtomicLongVSLongAdder(10, 200000);
System.out.println("==================");
testAtomicLongVSLongAdder(100, 200000);
}
static void testAtomicLongVSLongAdder(final int threadCount, final int times) {
try {
long start = System.currentTimeMillis();
testLongAdder(threadCount, times);
long end = System.currentTimeMillis() - start;
System.out.println("条件>>>>>>线程数:" + threadCount + ", 单线程操作计数" + times);
System.out.println("结果>>>>>>LongAdder方式增加计数" + (threadCount * times) + "次,共计耗时:" + end);
long start2 = System.currentTimeMillis();
testAtomicLong(threadCount, times);
long end2 = System.currentTimeMillis() - start2;
System.out.println("条件>>>>>>线程数:" + threadCount + ", 单线程操作计数" + times);
System.out.println("结果>>>>>>AtomicLong方式增加计数" + (threadCount * times) + "次,共计耗时:" + end2);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
static void testAtomicLong(final int threadCount, final int times) throws InterruptedException {
CountDownLatch countDownLatch = new CountDownLatch(threadCount);
AtomicLong atomicLong = new AtomicLong();
for (int i = 0; i < threadCount; i++) {
new Thread(new Runnable() {
@Override
public void run() {
for (int j = 0; j < times; j++) {
atomicLong.incrementAndGet();
}
countDownLatch.countDown();
}
}, "my-thread" + i).start();
}
countDownLatch.await();
}
static void testLongAdder(final int threadCount, final int times) throws InterruptedException {
CountDownLatch countDownLatch = new CountDownLatch(threadCount);
LongAdder longAdder = new LongAdder();
for (int i = 0; i < threadCount; i++) {
new Thread(new Runnable() {
@Override
public void run() {
for (int j = 0; j < times; j++) {
longAdder.add(1);
}
countDownLatch.countDown();
}
}, "my-thread" + i).start();
}
countDownLatch.await();
}
}
结果:线程数越多,并发操作数越大,LongAdder的优势越明显 
低并发、一般的业务场景下AtomicLong是足够了。如果并发量很多,存在大量写多读少的情况,那LongAdder可能更合适。
LongAdder原理
AtomicLong中有个内部变量value保存着实际的long值,所有的操作都是针对该变量进行。也就是说,高并发环境下,value变量其实是一个热点,也就是N个线程竞争 一个热点。LongAdder的基本思路就是分散热点,将value值分散到一个数组中,不 同线程会命中到数组的不同槽中,各个线程只对自己槽中的那个值进行CAS操作,这样热点就被分散了,冲突的概率就小很多。如果要获取真正的long值,只要将各个槽中的变量值累加返回。 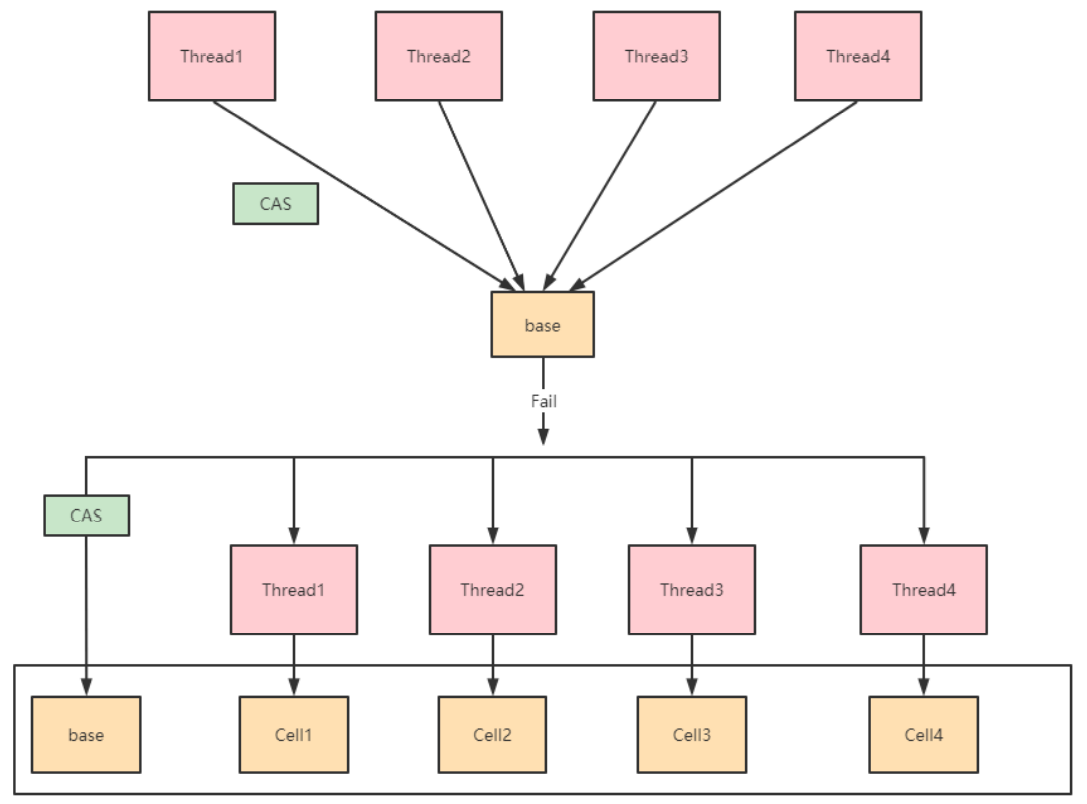
问题一:谈谈你对CAS的理解
CAS(Compare And Swap,比较与交换),通常指的是这样一种原子操作:针对一个变量,首先比较它的内存值与某个期望值是否相同,如果相同,就给它赋一个新值。CAS 是一个不可分割的原子操作,并且其原子性是直接在硬件层面(cas指令)得到保障的。CAS是一种无锁算法,在不使用锁(没有线程被阻塞)的情况下实现多线程之间的变量同步。
问题二:CAS存在哪些缺陷?ABA问题如何解决?
CAS 虽然高效地解决了原子操作,但是还是存在一些缺陷的,主要表现在三个方面:
1.自旋 CAS 长时间不成功,则会给 CPU 带来非常大的开销
解决方案:破坏掉for死循环,当超过一定时间或者一定次数时,return退出。JDK8新增的LongAddr,和ConcurrentHashMap类似的方法。当多个线程竞争时,将粒度变小,将一个变量拆分为多个变量,达到多个线程访问多个资源的效果,最后再调用sum把它合起来。
2.只能保证一个共享变量原子操作
解决方案:CAS操作是针对一个变量的,如果对多个变量操作,
1) 可以加锁来解决。
2) 封装成对象类解决。
3.ABA 问题
解决方案:数据库有个锁称为乐观锁,是一种基于数据版本实现数据同步的机制,每次修改一次数据,版本就会进行累加。同样,Java也提供了相应的原子引用类AtomicStampedReference

若有收获,就点个赞吧
0 人点赞
