概述
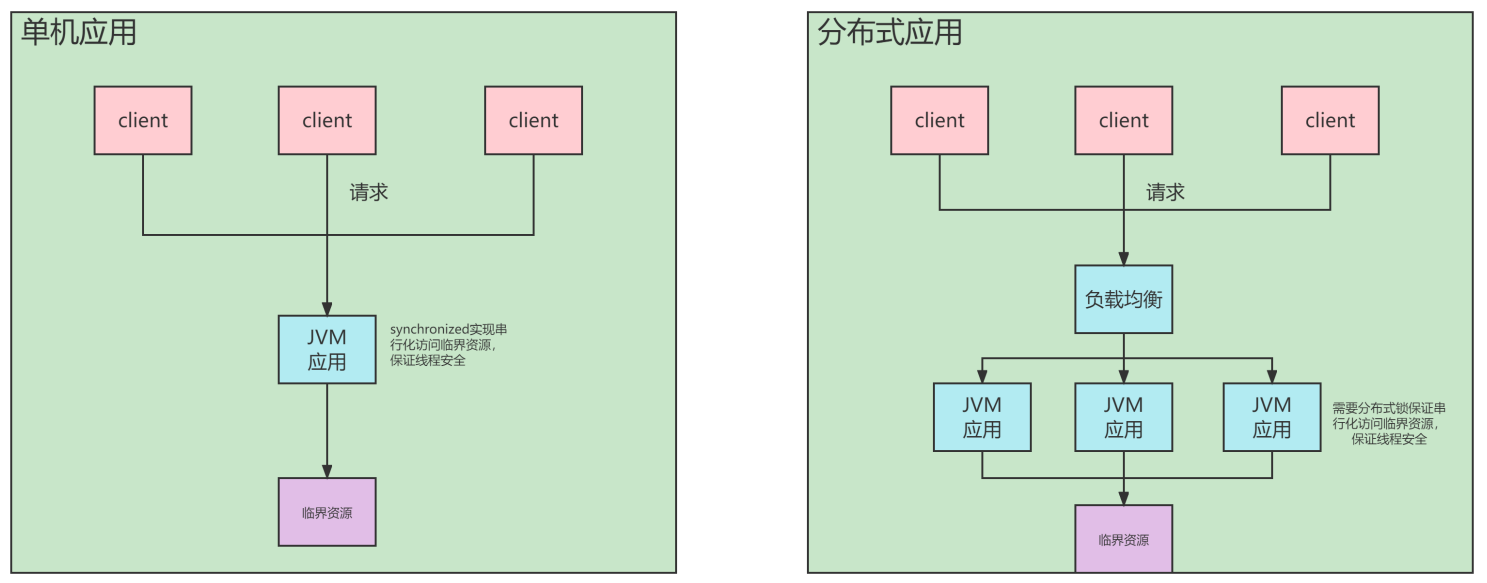
应用场景
- 互联网秒杀
- 抢优惠券
-
使用Redis实现
version-1
业务代码出现异常,锁无法释放
public String deductStock() {String lockKey = "product:001";Boolean result = stringRedisTemplate.opsForValue().setIfAbsent(lockKey, lockKey, 30, TimeUnit.SECONDS);if (!result) {}int stock = Integer.parseInt(stringRedisTemplate.opsForValue().get("stock"));if (stock > 0) {// 可能是复杂的业务处理代码int realStock = stock - 1;stringRedisTemplate.opsForValue().set("stock", realStock + "");System.out.println("扣减成功,剩余库存" + realStock);} else {System.out.println("扣减失败,库存不⾜");}stringRedisTemplate.delete(lockKey);return "end";}
version-2
业务代码执⾏到⼀半,JVM宕机了,锁⽆法释放
public String deductStock() {String lockKey = "product:001";try {Boolean result = stringRedisTemplate.opsForValue().setIfAbsent(lockKey, lockKey, 30, TimeUnit.SECONDS);if (!result) {return "error";}int stock = Integer.parseInt(stringRedisTemplate.opsForValue().get("stock"));if (stock > 0) {// 可能是复杂的业务处理代码int realStock = stock - 1;stringRedisTemplate.opsForValue().set("stock", realStock + "");System.out.println("扣减成功,剩余库存" + realStock);} else {System.out.println("扣减失败,库存不⾜");}} finally {stringRedisTemplate.delete(lockKey);}return "end";}
version-3
- 假设超时时间设置为30秒,业务代码执⾏完需要35秒,在业务代码执⾏期间,Redis把锁释放了, 那么其他线程⼜能继续访问临界资源了,⾼并发场景下,会存在锁失效问题。
2. 另外,由于当前线程释放了锁,假如其他线程执⾏这段代码,只需要3秒,那么他就可以在3秒后把 锁删除掉,即其他线程删除了当前线程的锁。public String deductStock() {String lockKey = "product:001";try {Boolean result = stringRedisTemplate.opsForValue().setIfAbsent(lockKey, lockKey, 30, TimeUnit.SECONDS);if (!result) {return "error";}int stock = Integer.parseInt(stringRedisTemplate.opsForValue().get("stock"));if (stock > 0) {// 可能是复杂的业务处理代码int realStock = stock - 1;stringRedisTemplate.opsForValue().set("stock", realStock + "");System.out.println("扣减成功,剩余库存" + realStock);} else {System.out.println("扣减失败,库存不⾜");}} finally {stringRedisTemplate.delete(lockKey);}return "end";}
version-final
如果集群架构下,master节点没有同步锁到slaver,那么即使选举出最新的slaver,锁仍然失效了。public String deductStock() {String lockKey = "product:001";String clientId = UUID.randomUUID().toString();// try-catch 防⽌异常⽆法释放锁try {// 超时时间防⽌宕机⽆法释放分布式锁Boolean result = stringRedisTemplate.opsForValue().setIfAbsent(lockKey, clientId, 30, TimeUnit.SECONDS);if (!result) {return "error";}// 续命,防⽌业务执⾏过久,提前释放分布式锁new Timer().scheduleAtFixedRate(new TimerTask() {@Overridepublic void run() {String result = stringRedisTemplate.opsForValue().get(lockKey);if (result != null) {stringRedisTemplate.opsForValue().setIfAbsent(lockKey, clientId, 30, TimeUnit.SECONDS);}}}, 10, 10);int stock = Integer.parseInt(stringRedisTemplate.opsForValue().get("stock"));if (stock > 0) {// 可能是复杂的业务处理代码int realStock = stock - 1;stringRedisTemplate.opsForValue().set("stock", realStock + "");System.out.println("扣减成功,剩余库存" + realStock);} else {System.out.println("扣减失败,库存不⾜");}} finally {// 防⽌其他线程删除当前线程分布式锁String value = stringRedisTemplate.opsForValue().get(lockKey);if (value.equals(clientId))stringRedisTemplate.delete(lockKey);}return "end";}
总结
实现⼀把完善的Redis锁需要考虑各种异常情况,⽐如代码异常、系统宕机、锁过期、集群master 重新选举。
2. Redis作为简单架构下的分布式锁实现已经⾜够,但是集群架构下,Redis设计初衷是为了实现缓存 功能,如果硬是为了实现CP架构实现分布式锁,本身会与AP架构的⾼性能冲突,另外代码为了完善分布式锁的各种异常处理,还会增加复杂性,复杂性再次带来了性能的损耗。
3. ⼀个系统的设计是要结合:组件架构、代码异常处理、性能、复杂性各个因素进⾏权衡,最终完成⼀个适合业务的软件。使用Redisson实现
使用
```java @Autowired private Redisson redisson; @Bean public Redisson redisson() { // 单机模式 Config config = new Config();
config.useSingleServer().setAddress(“redis://localhost:6379”).setDatabase(0); return ((Redisson) Redisson.create(config)); }
public String deductStock2() { String lockKey = “product:001”; RLock lock = redisson.getLock(lockKey); try { // 默认设置了超时时间 lock.lock(); //setIfAbsent(lockKey, clientId, 30, TimeUnit.SECONDS); int stock = Integer.parseInt(stringRedisTemplate.opsForValue().get(“stock”)); if (stock > 0) { // 可能是复杂的业务处理代码 int realStock = stock - 1; stringRedisTemplate.opsForValue().set(“stock”, realStock + “”); System.out.println(“扣减成功,剩余库存” + realStock); } else { System.out.println(“扣减失败,库存不⾜”); } } finally { lock.unlock(); /if (clientId.equals(stringRedisTemplate.opsForValue().get(lockKey))) { stringRedisTemplate.delete(lockKey); }/ } return “end”; } ```
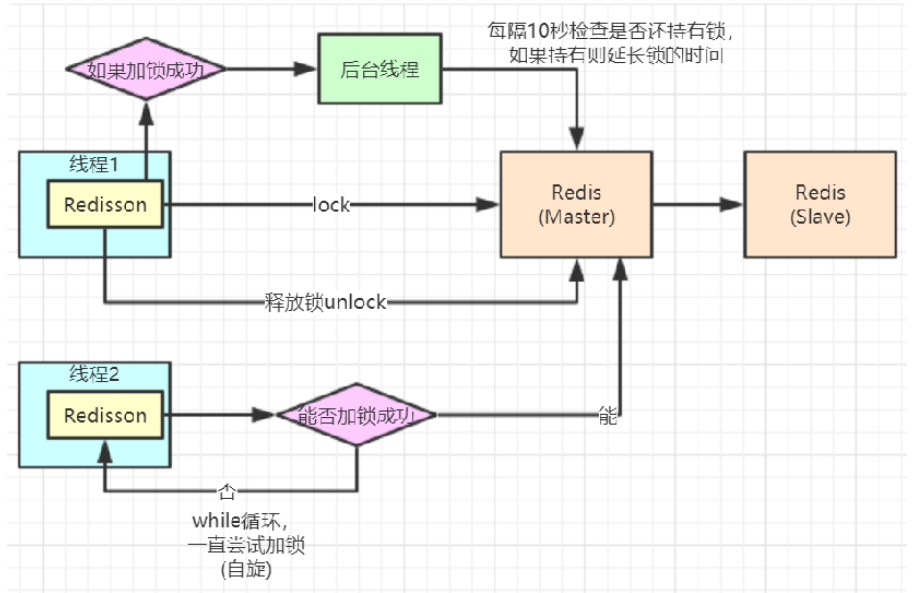
原理
重点总结
- 为什么需要分布式锁? synchronized
2. try-catch异常,处理解锁失败
3. 设置超时保证宕机时,锁也能失效
4. 客户端唯⼀标识:防⽌其他客户端删除当前客户端的锁
5. 这时候,分布式锁已经差不多很完善了,但仍然会有业务执⾏时间超过锁存活时间的问题,这种概率很低。在系统设计中,如果要保证所有问题都可以被完美的解决,付出的代价很⼤,可能造成系统性能极度降低、复杂度极度上升。系统设计需要权衡业务实现与系统性能、复杂性之间的关系。⼀般场景的分布式锁就这么⽤了。
6. 锁续命:开启定时任务,间隔⼀段时间去检查锁是否存在,如果存在,延⻓锁时间,不存在就结束任务。
7. redisson
a. 使⽤⽅式
b. 加锁原理——lua脚本保证原⼦操作、看⻔狗续命
c. 可重⼊锁
8. 看源码
a. 第⼀遍抓住主脉络——连蒙带猜、静态看源码/注释
b. 后⾯再扣细节
9. 主从架构下,锁没有同步到slave,主节点挂了,slave没有该锁,业务线程会加锁成功,这种情况 导致的原因是Redis并不是CP架构,⽽是AP架构,可以⽤ZK实现分布式锁,或者将Redis调整为CP 架构,但这⼜违背了缓存的初衷。
a. 如果技术架构中本身不存在ZK,使⽤了Redis,那么没必要为了实现分布式锁⽽添加⼀个ZK组 件,增加整个系统的复杂性。可以在业务中增加⼀些⽇志,当发⽣并发问题时,由⼈⼯去处理 造成的影响——⽐如超卖。
b. redlock——集群半数Redis加锁成功才算加锁成功。这种使⽤⽅式⼜会造成分布式redis使⽤的 复杂性,⽐如数据⼀致性保证,另外还会带来分拆——聚合的性能损耗,本身与redis设计理念 相违背,所以不建议使⽤。
10. ⾼并发分布式锁如何实现?
a. 集群:不同key分布到不同的redis实例上
b. 分段锁:相同key分段,使其分布到不同redis实例上——redlock,借ConcurrentHashMap
问题一:redis的分布式锁加锁失败怎么处理?
1.抛出异常,通知用户稍后重试
2.Sleep 一会重试
3.将请求转移到延时队列。稍后重试
问题二:MySQL哈希索引不适用哪些场景?
不支持范围查询
不支持索引完成排序
不支持联合索引的最左前缀匹配规则
通常,B+树索引结构适用于绝大多数场景,像下面这种场景用哈希索引才更有优势:
在HEAP表中,如果存储的数据重复度很低(也就是说基数很大),对该列数据以等值查询为主,没有范围查询、没有排序的时候,特别适合采用哈希索引,例如这种SQL:
# 仅等值查询
select id, name from table where name=’李明’;
而常用的 InnoDB 引擎中默认使用的是B+树索引,它会实时监控表上索引的使用情况。
如果认为建立哈希索引可以提高查询效率,则自动在内存中的“自适应哈希索引缓冲区”建立哈希索引(在InnoDB中默认开启自适应哈希索引)。
通过观察搜索模式,MySQL会利用index key的前缀建立哈希索引,如果一个表几乎大部分都在缓冲池中,那么建立一个哈希索引能够加快等值查询。
注意:在某些工作负载下,通过哈希索引查找带来的性能提升远大于额外的监控索引搜索情况和保持这个哈希表结构所带来的开销。
但某些时候,在负载高的情况下,自适应哈希索引中添加的read/write锁也会带来竞争,比如高并发的join操作。like操作和%的通配符操作也不适用于自适应哈希索引,可能要关闭自适应哈希索引。
问题三:redis的分布式锁如何实现?
正常情况下redis使用setnx lock加锁,使用del lock释放锁就可以了。但是如果还没释放锁,服务中途就挂了,这样锁得不到释放造成死锁。可以加上超时时间,等服务启了在释放锁。
因为setnx和expire指令不是原子性,redis在2.8以后加入set扩展命令,使得这两个命令能一起执行
问题四:什么情况下应不建或少建索引?
1、表记录太少
2、经常插入、删除、修改的表
3、数据重复且分布平均的表字段,假如一个表有10万行记录,有一个字段A只有T和F两种值,且每个值的分布概率大约为50%,那么对这种表A字段建索引一般不会提高数据库的查询速度。
4、经常和主字段一块查询但主字段索引值比较多的表字段

若有收获,就点个赞吧
0 人点赞
