String
Redis key-value 都是保存在dict中,数据保存在两个dict中,两个dict的原因是为了做扩容,采用渐进式rehash的方式。每个dict底层是hashtable实现,hashtable底层也是数组实现,而所有的key都会被处理成String类型。
String类型在Redis3.2之前是sds(Simple Dynamic String)数据类型,自定义的数据类型。
Redis3.2之后,key的长度不同,所对应的类型就不同,如下图:
String结构图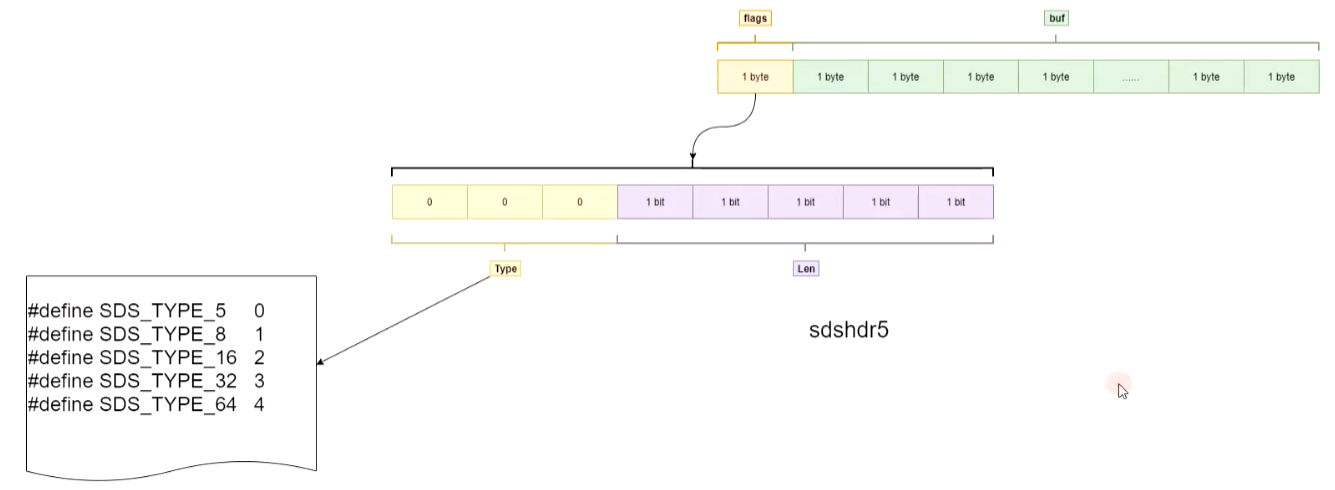
KEY
key是用数组存储,根据key的进行位与运算得出下标位置,如果产生hash冲突,则使用链表存储。
dict代码结构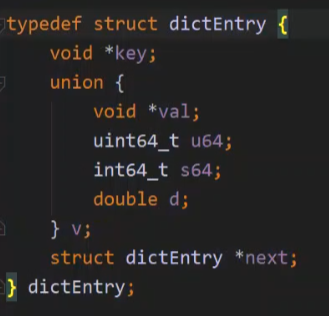
VALUE
*ptr:指向真实的数据Object,如:int、raw、embstr、quickList、hashtable、zipList、intset、skpList。
redis Object 代码结构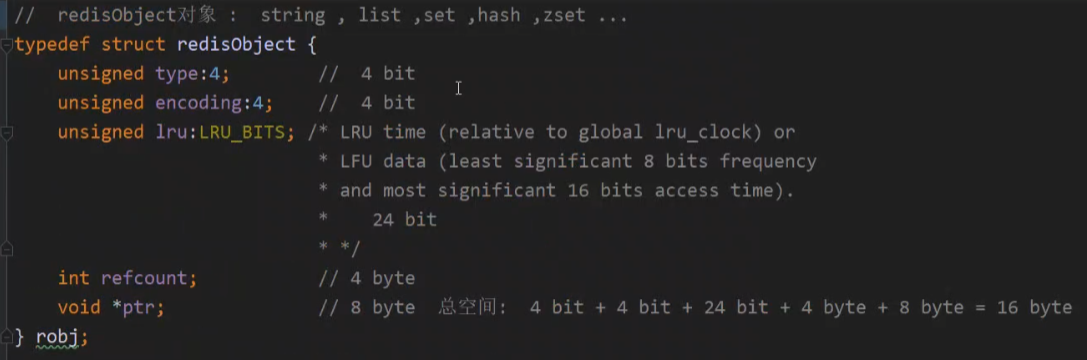
Redis DB
默认16个,可(在redis.conf中)修改默认值。其实数据库在redis底层结构都是一模一样,只是id不同。
Redis DB代码结构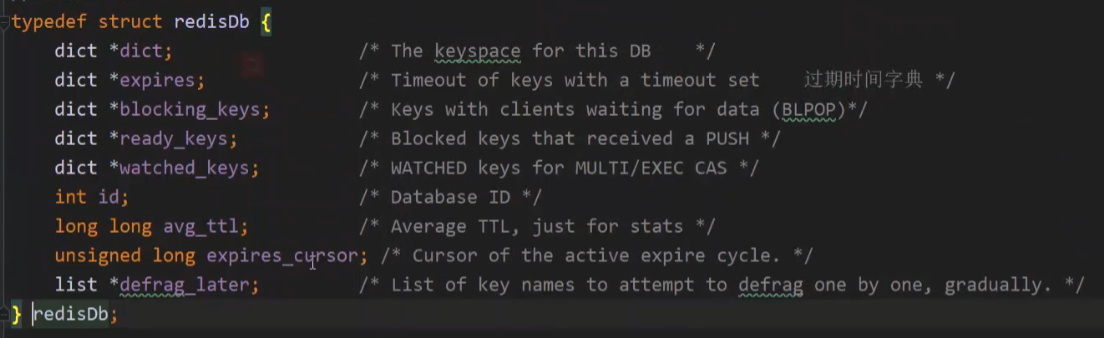
bitmap
即位图,底层是String结构,只不过是用bit保存状态,例:以用户ID(递增ID最好)表示下标位置,用户1有登录,则将值置为1(bitmap默认值为0)。8个用户就是1 byte,也就是说16个用户的登录状态才占用2 byte。
String最大值为2^32 Bit,计算公式:2^32/8(bit)/1024(kb)/1024(mb)=512MB
应用场景:日活量统计。
常量命令
- setbit key offset value
- getbit key offset
- strlen key //查看value的长度
- object encoding key //查看value数据类型
- bitcount key[start end] //统计bitmap中value为1的数量
- bitop and temp login1 login2 //将login1日志和login2日志通过位与运算(类似取并集)
案例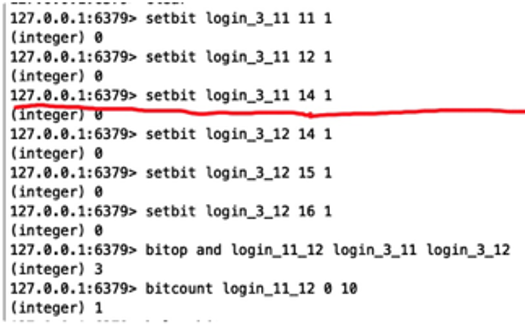
bitmap统计
- 3月11日有3个用户登录,用户id分别是:11、12、14;
- 3月12日有3个用户登录,用户id分别是:14、15、16;
- 将userID作为 offset 下标,登录过就将值设为1;
- 判断11~12日哪些用户都有登录过,则通过“位与运算”得到结果,并保存到新的key中;
- 结果是只有userID为14的用户都曾登录过;
最大的userID位置是第16个bit(setbit login_3_12 16 1),16/8(bit) =2(byte)也就是说key“login_3_12”总共占了 2 byte;
总结
Redis所有类型的key值都是String类型,使用dict实现,其底层是hashtable(数组实现);
- 每个key都会有两个dict,为什么是两个呢?数组扩容时成倍的,如果数据小的话还好,如果数据很大,比如上百万,成倍扩容非常消耗时间,所以redis底层数组扩容采用“渐进式Rehash”,当hash取模定位到某个桶时,就将这个桶挪到新的dict中,这样就不会让所有的数据一次性迁移完而影响性能,所以这就是为什么redis底层存放key会生成两个dict,就是为了扩容;
- Redis的数据库底层是用id分区,如果以为将数据存放在不同的数据库可以缓解Redis的访问压力,这种想法是错误的,因为不管数据存在哪个数据库,都是在一个Redis节点,对数据操作也是单线程处理。如果想将数据分散存放,适合的方案是Redis集群;
- bitmap底层是String结构,通过位(bit)来存放数据,只能通过0 1 来表示状态,也就是说 1 byte可以存放8个数据状态,这样极大的节省了内存空间,且做统计查询时的速度也是相当的快,查询的时间复杂度为0(1);
List
List是⼀个有序(按加⼊的时序排序)的数据结构,Redis采⽤quicklist(双端链表)和ziplist作为List的底层实现。
在redis中,list可以从两端存取数据,⽽且数据是有序的,底层使⽤的是ziplist来实现的,如果使⽤链表来实现,需要额外的保存两个指针pre和next,在64位操作系统中,这两个指针的⼤⼩都是8字节,那么⼀个元素的⼤⼩就是(数据⼤⼩+16字节),这种过⼤的指针也称为胖指针,⽽且链表的元素在内存中并不连续,会造成内存碎⽚问题,如果数据量过⼤,那么显然这对空间来说造成了浪费。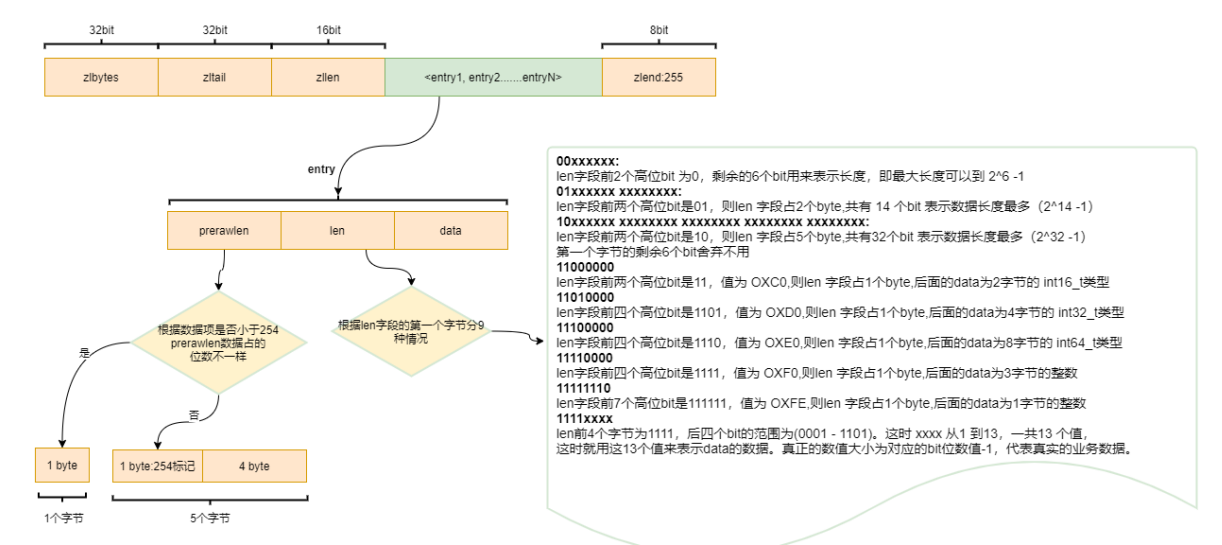
⼀个ziplist是⼀个连续的内存空间,其中包括ziplist中的数据量32位,ziplist的尾部指针32位(⽅便从后往前遍历,最快找到尾节点),ziplist的元素个数16位,在ziplist的最后⼀个元素是固定的8位,恒等于255。
中间的数据部分中,每个元素entry中包含前驱指针,⻓度和数据。前驱指针会判断是否⼤于254,如果⼩于,那么使⽤⼀个字节来保存(⼀个字节最⼤可以保存255)元素个数,如果⼤于则使⽤5个字节记录元素个数。
如果redis仅使⽤ziplist来保存list的数据,那么如果数据量很⼤的情况,在删除和新增元素的时候会出现⼤量的复制。
所以把整个list分成了若⼲个ziplist,每个ziplist在形成链表。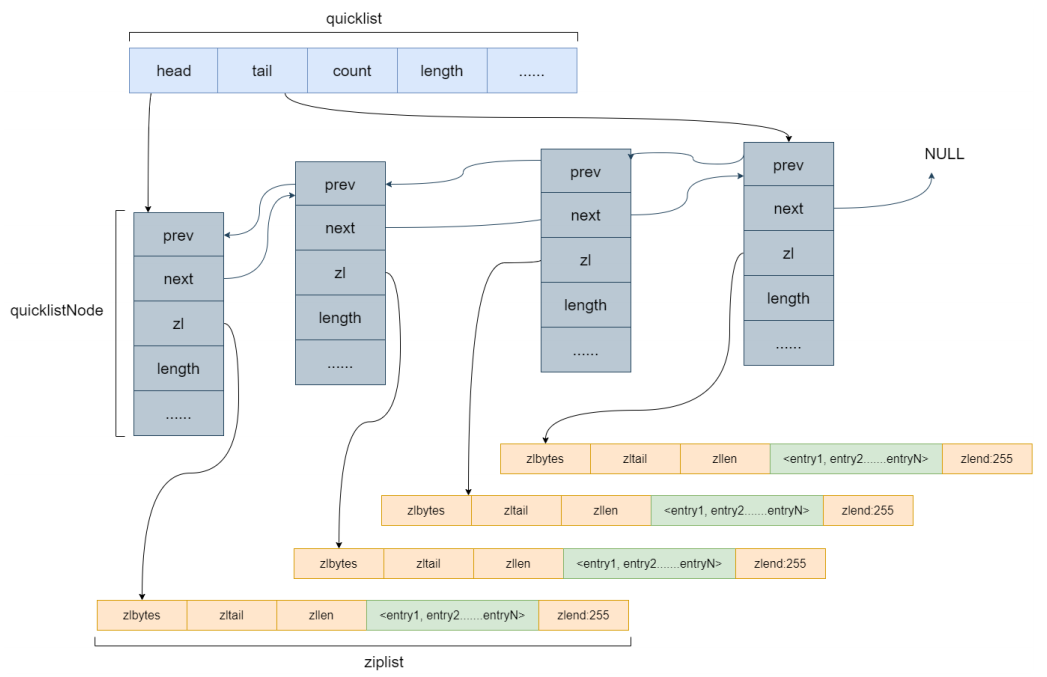
链表的每个节点,都指向了⼀个ziplist,这样使每个ziplist都不会很⼤,过⼤的ziplist会进⾏分列,称为两个节点。
ziplist的⼤⼩是可以配置的,可以通过设置每个ziplist的最⼤容量,quicklist的数据压缩范围,提升数据存取效率。
list-max-ziplist-size-2:单个ziplist节点最⼤能存储8kb,超过则进⾏分裂,将数据存储在新的ziplist节点中。
list-compress-depth1:0代表所有节点,都不进⾏压缩,1,代表从头节点往后⾛⼀个,尾节点往前⾛⼀个不⽤压缩,其他的全部压缩,2,3,4…以此类推。Hash
Hash数据结构底层实现为⼀个字典(dict),也是RedisBb⽤来存储K-V的数据结构,当数据量⽐较⼩,或者单个元素⽐较⼩时,底层⽤ziplist存储,数据⼤⼩和元素数量阈值可以通过如下参数设置。
hash-max-ziplist-entries512:ziplist元素个数超过512,将改为hashtable编码
hash-max-ziplist-value64:单个元素⼤⼩超过64byte时,将改为hashtable编码
当使⽤命令hsetkeyfieldvaluefieldvalue时,如果数量较⼩或元素较⼩时,查询hset的数据hgetall的查询结果是有序的,⽽字典是⽆序的,当插⼊⼀个很⼤的值时,数据结构就会发⽣变化,使⽤字典来保存,在查询数据就是⽆序的,使⽤objectencodingkey也可以看出,从ziplist变成了hashtable。
对⽐String和Hash两种类型,String类型是保存key-value在⼀个数组中,如果数据量⽐较⼤,那么会频繁的rehash进⾏扩容,⽽Hash只会把外层的key保存在⼀个桶中,内层的field会单独保存在另⼀个⼩桶。
Hash不能对field单独设置有效期,只能对外层的key设置Set
Set为⽆序的,⾃动去重的集合数据类型,Set数据结构底层实现为⼀个value为null的字典(dict),当数据可以⽤整形表示时,Set集合将被编码为intset数据结构,把数据保存在数组中。
两个条件任意满⾜时Set将⽤hashtable存储数据:
1、元素个数⼤于set-max-intset-entries
2、元素⽆法⽤整形表示
set-max-intset-entries512:intset能存储的最⼤元素个数,超过则⽤hashtable编码
对于有序的数据结构,查询效率是⾮常⾼的,例如⼆分查找,所以redis做了这个优化。如果⽆法⽤整形表示,那么会使⽤hashtable进⾏编码。
encoding:编码类型typedef struct intset {uint32_t encoding;uint32_t length;int8_t contents[];} intset;#define INTSET_ENC_INT16 (sizeof(int16_t))#define INTSET_ENC_INT32 (sizeof(int32_t))#define INTSET_ENC_INT64 (sizeof(int64_t))
length:元素个数
contents[]:元素存储
整数集合是⼀个有序的,存储整型数据的结构。整型集合在Redis中可以保存int16_t,int32_t,int64_t类型的整型数据,并且可以保证集合中不会出现重复数据。
intset数据类型⽀持多种⻓度,如果当前的⻓度满⾜不了,就会进⾏升级,直到64位以上就会使⽤hashtable来储存ZSet
ZSet为有序的,⾃动去重的集合数据类型,ZSet数据结构底层实现为字典(dict)+跳表(skiplist),当数据⽐较少时,⽤ziplist编码结构存储。
zset-max-ziplist-entries128:元素个数超过128,将⽤skiplist编码
zset-max-ziplist-value64:单个元素⼤⼩超过64byte,将⽤skiplist编码
zset的插⼊命令包含key、分值、元素,zaddkeyscorevalue,是根据score来排序的,当数据量不到配置的值时,使⽤ziplist来保存。
如果当数据量较⼤的时候,使⽤链表,那么效率不⾼,需要每个节点都遍历⼀遍,所以使⽤了跳表。
就是在数据层的上层,把部分数据的索引提出⼀个索引层,按照折半查找的逻辑,数据量为N,每⼀层都提出N/2个索引,第⼀层提出N/2个索引,第⼆层提出N/2^2个索引,那么提出K层时,第K层会提出N/2^K个索引,假设第K层只有两个索引时,查找⼀个元素每层的索引的查找都是常数,所以时间复杂度是O(logN)。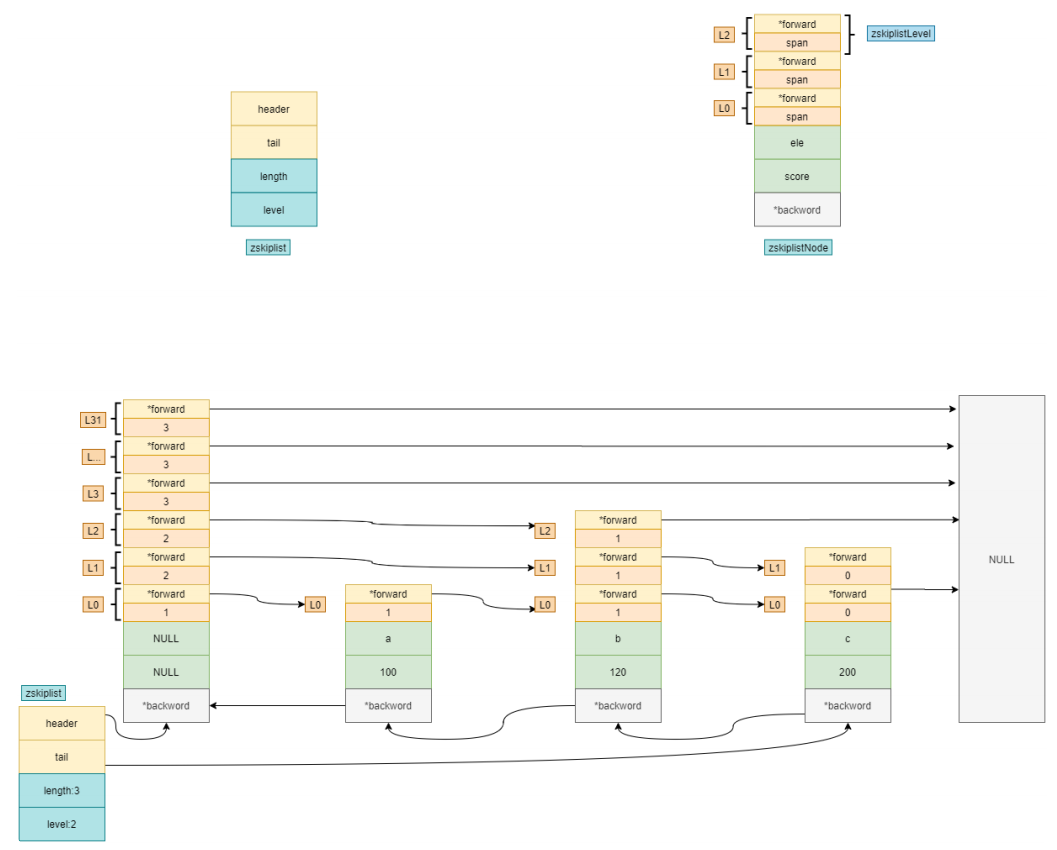
在redis中没有严格按照跳表来实现,图中的结构中,头节点不保存数据,仅保存跳表的⾼度,有三个元素,100,120,200,每个元素都有⼀个backword指针,指向前⼀个节点,可以从后往前遍历整个链表,在zskiplist中保存了头节点和尾节点,⻓度和最⾼的层⾼,查询时是从上往下遍历的。问题一:如何实现从20G文件中,查出年龄相同的人有多少个(文件中只存年龄)?
通过数组实现,因为年龄最大也不超过100岁,也就是说可以将年龄作为下标,如果下标重复,则+1,而且数组查询的时间复杂度是O(n),效率非常高,不用任何中间件和算法就能实现。问题二:简单描述一下Redis渐进式rehash及动态扩容机制
在Redis中,键值对(Key-Value Pair)存储方式是由字典(Dict)保存的,而字典底层是通过哈希表来实现的。通过哈希表中的节点保存字典中的键值对。我们知道当HashMap中由于Hash冲突(负载因子)超过某个阈值时,出于链表性能的考虑,会进行Resize的操作。
Redis也一样
在redis的具体实现中,使用了一种叫做渐进式哈希(rehashing)的机制来提高字典的缩放效率,避免 rehash 对服务器性能造成影响,渐进式 rehash 的好处在于它采取分而治之的方式, 将 rehash 键值对所需的计算工作均摊到对字典的每个添加、删除、查找和更新操作上, 从而避免了集中式 rehash 而带来的庞大计算量。
字典扩容需要同时满足如下两个条件:
(1)哈希表中保存的key数量超过了哈希表的大小(可以看出size既是哈希表大小,同时也是扩容阈值)
(2)当前没有子进程在执行aof文件重写或者生成RDB文件;或者保存的节点数与哈希表大小的比例超过了安全阈值(默认值为5)
也可以如下理解:
当以下条件中的任意一个被满足时, 程序会自动开始对哈希表执行扩展操作:
服务器目前没有在执行 BGSAVE 命令或者 BGREWRITEAOF 命令, 并且哈希表的负载因子大于等 1
服务器目前正在执行 BGSAVE 命令或者 BGREWRITEAOF 命令, 并且哈希表的负载因子大于等于 5问题三:MySQL支持的分区类型有哪些?
RANGE分区:这种模式允许将数据划分不同范围。例如可以将一个表通过年份划分成若干个分区
LIST分区:这种模式允许系统通过预定义的列表的值来对数据进行分割。按照List中的值分区,与RANGE的区别是,range分区的区间范围值是连续的。
HASH分区 :这中模式允许通过对表的一个或多个列的Hash Key进行计算,最后通过这个Hash码不同数值对应的数据区域进行分区。例如可以建立一个对表主键进行分区的表。
KEY分区 :上面Hash模式的一种延伸,这里的Hash Key是MySQL系统产生的。问题四:说下Redis过期键的删除策略
Redis对于过期键有三种清除策略:
a)被动删除:当读/写一个已经过期的key时,会触发惰性删除策略,直接删除掉这个过期key
b)主动删除:由于惰性删除策略无法保证冷数据被及时删掉,所以Redis会定期(默认每100ms)主动淘汰一批已过期的key,这里的一批只是部分过期key,所以可能会出现部分key已经过期但还没有被清理掉的情况,导致内存并没有被释放
c)当前已用内存超过maxmemory限定时,触发主动清理策略
主动清理策略在Redis 4.0 之前一共实现了 6 种内存淘汰策略,在 4.0 之后,又增加了 2 种策略,总共8种:
a) 针对设置了过期时间的key做处理:
volatile-ttl:在筛选时,会针对设置了过期时间的键值对,根据过期时间的先后进行删除,越早过期的越先被删除。
volatile-random:就像它的名称一样,在设置了过期时间的键值对中,进行随机删除。
volatile-lru:会使用 LRU 算法筛选设置了过期时间的键值对删除。
volatile-lfu:会使用 LFU 算法筛选设置了过期时间的键值对删除。
b) 针对所有的key做处理:
allkeys-random:从所有键值对中随机选择并删除数据。
allkeys-lru:使用 LRU 算法在所有数据中进行筛选删除。
allkeys-lfu:使用 LFU 算法在所有数据中进行筛选删除。
c) 不处理:
noeviction:不会剔除任何数据,拒绝所有写入操作并返回客户端错误信息”(error) OOM command not allowed when used memory”,此时Redis只响应读操作。
问题五:表分区有什么好处?
分表:指的是通过一定规则,将一张表分解成多张不同的表。比如将用户订单记录根据时间成多个表。
分表与分区的区别在于:分区从逻辑上来讲只有一张表,而分表则是将一张表分解成多张表。
1、存储更多数据。分区表的数据可以分布在不同的物理设备上,从而高效地利用多个硬件设备。和单个磁盘或者文件系统相比,可以存储更多数据
2、优化查询。在where语句中包含分区条件时,可以只扫描一个或多个分区表来提高查询效率;涉及sum和count语句时,也可以在多个分区上并行处理,最后汇总结果。
3、分区表更容易维护。例如:想批量删除大量数据可以清除整个分区。
4、避免某些特殊的瓶颈,例如InnoDB的单个索引的互斥访问,ext3问价你系统的inode锁竞争等。
问题六:Redis缓存与数据库双写不一致有什么方案解决?
a、对于并发几率很小的数据(如个人维度的订单数据、用户数据等),这种几乎不用考虑这个问题,很少会发生缓存不一致,可以给缓存数据加上过期时间,每隔一段时间触发读的主动更新即可。
b、就算并发很高,如果业务上能容忍短时间的缓存数据不一致(如商品名称,商品分类菜单等),缓存加上过期时间依然可以解决大部分业务对于缓存的要求。
c、如果不能容忍缓存数据不一致,可以通过加分布式读写锁保证并发读写或写写的时候按顺序排好队,读读的时候相当于无锁。
d、也可以用阿里开源的canal通过监听数据库的binlog日志及时的去修改缓存,但是引入了新的中间件,增加了系统的复杂度。

若有收获,就点个赞吧
0 人点赞
