HashMap
JDK1.7
注:了解即可,毕竟7已经不用了
1.数据结构:数组+链表
2.头插法,因为快
3.数组index存储的是Entry的引用,index=h & (table.length-1),在得到h之前,会对hashcode进行多次扰动(多个位移、异或操作),目的是高位也参与&运算,降低hash碰撞,更加散列
4.inflateTable方法。初始化容量,如果传入了参数不满足2的n次幂,那么就会将参数变为最近的2的n次幂的数字,比如参数传的是10,那么真正得到的容量就是16 为什么要这么做,就是因为满足第3点index的公式,如果不是2的n次幂的数,index=h & (table.length-1)算出来的结果就不是在table.length区间了
5.为什么数组容量一定要是2的n次方呢 方便计算index的值落在区间中,虽然取模%运算也能得到,但是位运算更快
6.put方法中遍历链表,是为了替换掉重复的key的value,这既能保证不会遍历链表全部元素,又能保证覆盖,但最终插入元素还是使用头插法
7.扩容
a.先判断是否满足扩容条件
(1) size > threshHold,threshHold = table.length loadFactory
(2) null != table[bucketIndex],即hash出来的数组index不是null
满足以上两点,才能扩容,JDK8中没有第二个条件
b.原数组容量 2
c.双层循环,遍历数组+链表所有元素,移动到新的数组中,index变化存在规律:新的index存在两种情况(前提条件是没有rehash,JDK8没有这个rehash操作了):
(1) 等于原下标
(2) 等于原下标+oldCapacity
(3) 总结就是,比如原下标是4,容量是16,扩容后下标是4/20
(4) 扩容后,链表的顺序颠倒了
d.多线程扩容会发生循环链表问题
e.既然数组中存储的是Entry的引用,那为什么不直接把头结点引用赋值给扩容后数组的index,这样整个链表就移动完毕了,遍历链表每个移动不是很麻烦么 扩容的目的是为了缩短链表的长度,扩容后,原来一条链上的元素经过hash & table.length-1后,可能会落到新数组的新index上,这样链表长度缩短,get效率提升
f.rehash
与一个JDK变量有关系,会根据这个变量计算出hashSeed。hashSeed默认是0,它的目的是为了让hash算法的结果更加散列,如果开发者认为,在数组capacity超过一定长度后,需要hashSeed增强算法散列性,可以自行配置JDK变量
g.如何防止扩容
如果适用场景能确定一个HashMap中只会存放固定容量的Entry元素,可以调用构造方法时,指定loadFactory,让扩容条件1不满足,那么就不会发生扩容
8.modCount
记录HashMap的修改次数,每次put、remove都是+1
当使用迭代器去遍历元素时,如果在遍历过程中,调用HashMap方法修改了HashMap的元素,比如remove掉一个元素,那么就“有可能”抛出一个ConcurrentModificationException,因为迭代器的遍历方法会去判断modCount==expectedModCount,而expectedModCount是在迭代器的构造方法中初始化的,值是当时状态的HashMap的modCount
解决办法:调用迭代器的remove就可以了
为什么要这么设计? 这是一种fast-fail机制,目的是:当发现HashMap元素发生问题时,能快速抛出异常,不再让程序在错误的轨道上继续执行
9.key==null
a. key==null的entry会固定放到数组index=0的位置
b. 在放入前,会去遍历index=0的链表,看看是否存在key==null的元素,存在就覆盖,所以只会存在一个key==null的元素
c.当然,index=0的链表还可能有其他元素
JDK1.8
重点
1.数据结构——-红黑树
a. 插入和查询时间复杂度都是log(n)
b. 插入逻辑
2.put
a. 树化
b. 扩容
3.remove
a. 去树化
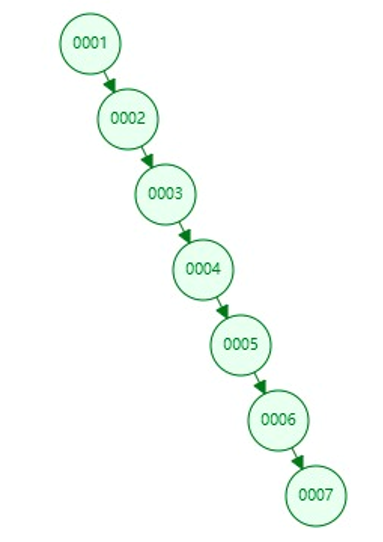
BST(二叉搜索树)
特点
- 若左子树不空,则左子树上所有结点的值均小于或等于它的根节点的值;
- 若右子树不空,则右子树上所有结点的值均大于或等于它的根节点的值;
- 左、右子树也分别为二叉搜索树;
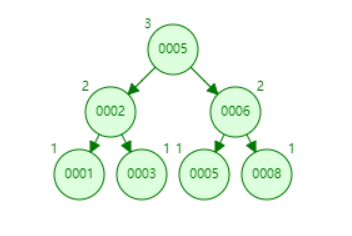
AVL(平衡二叉树)
特点
- 左右子树的高度差小于等于1;
- 其每一个子树均为平衡二叉树;
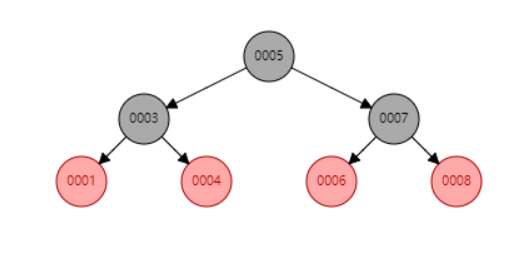
红黑树
特点
- 根节点必须为黑色;
- 父子节点不能同为红色;
- 从任何一个节点出发,到达叶子节点经过的黑色节点的数量一致;
- 每个红色节点的两个子节点都是黑色,叶子节点都是黑色。
注:规则限制 红黑树>AVL>BST,平均查找长度(最坏情况)—-红黑树,AVL都是O(logn) —-BST是(O(n))退化成了链表
AVL是为了避免BST的高度过渡增长,降低BST的性能,从而定了某些规则来限制避免树的高度增长过快
红黑树又相当于AVL树的一个扩展,一个子类,若AVL树频繁的删除或插入节点时,会导致AVL树的不平衡,从而频繁的做旋转,降低了性能,所以说AVL树比较适合做查找操作。而对于红黑树来说,虽然限制比较多一些,但是不会频繁的进行旋转,它有变色的功能,性能有所提升。红黑树旋转次数少,所以对于搜索,插入,删除操作较多的情况下,用红黑树。
因此在JDK8中,选择了红黑树作为链表升级后的数据结构,适合HashMap这个需要频繁插入、删除、查询工具。
put
put过程会涉及到扩容、链表树化。
扩容逻辑可以应用在日常开发中:
根据数据量对HashMap进行初始化,避免默认参数导致的过多扩容次数,如果数据量可以确定,那么可以避免扩容。
- 首先根据key进行hash运算,计算出hash值
与jdk7的区别是,hash算法简化了。jdk7那么复杂(很多位运算)的hash算法目的是为了增强算法结果的散列性,让元素尽可能分布在数组空槽点,每个index处的链表长度尽量小。到了jdk8,查询、插入效率由红黑树进行了保证,所以hash算法就不用那么复杂了,这样可以减少cpu消耗。
- 如果数组是null或table.length==0,初始化/扩容数组
- 插入元素,根据hash & table.length-1计算出index
a. 如果index处没有元素,直接插入
b. 如果有,会有3个分支
1. key等于index的key,hash值也相等,就覆盖value,返回oldValue1. 插入链表
1.创建新节点,使用尾插法插入元素
2.如果发现元素个数>8,即9个元素,将链表升级为红黑树———树化
a. 树化前,优先判断table.length是否>64,满足才扩容,否则先扩容。扩容的目的也是为了缩短链表长度,提升查询效率效率,与树化目的一致。
b. 树化
- 遍历链表每个元素,单链表转换为双向链表
- 遍历双向链表,插入红黑树
1. 首先判断应该插入红黑树的左边还是右边。会依次比较下面的几项:hashcode、compareTo方法、getClass.getName、System.identityHashCode。
1. 插入后,根据红黑树定义重新平衡,此时root节点会发生变化;注意,此时双向链表的prev、next属性并没有变化,意味着双向链表仍然与之前一样,root引用指向双向链表中的元素之一。
- 将root节点重新赋值给table[index],然后把双向链表中的root元素放到链表头部
3. key等于index的key,hash值也相等,就覆盖value,返回oldValue
iii. 插入红黑树
1. 首先判断应该插入红黑树的左边还是右边。会依次比较下面的几项:hashcode、compareTo方法、getClass.getName、System.identityHashCode。
1. key等于index的key,hash值也相等,就覆盖value,返回oldValue
1. 插入后,根据红黑树定义重新平衡,此时root节点会发生变化;注意,此时双向链表的prev、next属性并没有变化,意味着双向链表仍然与之前一样,root引用指向双向链表中的元素之一。
1. 将root节点重新赋值给table[index],然后把双向链表中的root元素放到链表头部
4.扩容
a. 遍历数组每个index元素
- 如果是链表
遍历链表,在JDK7hashMap中,我们知道,移动的元素要么在oldIndex,要么在oldIndex+table.length,它是分别移动每个元素实现扩容。在jdk8中,会去遍历链表,根据hash&oldCap(旧数组容量)将两个位置的元素分类,重新生成两个单独的链表,然后分别把链表的头节点放到新数组的oldIndex或oldIndex+table.length,去完成批量扩容。
- 如果是红黑树
遍历红黑树,类似链表,将红黑树切分为两个长度较小的链表。切分后,判断每个链表的元素个数
1. 如果<6,那么将TreeNode回退为Node,红黑树变成链表
2. 如果>=6
a. 如果切分原红黑树后,发现所有元素都移动到oldIndex或oldIndex+table.length之一,那么就把整棵树移动过去,即只移动原红黑树的root节点即可
b. 如果切分为了2棵树,就需要把新切分出来的半棵树的元素,进行树化,然后移动半棵树到新的index
remove
会包含红黑树退化为链表的过程,简称去树化
- 移除链表中的元素
- 移除红黑树中的元素
a. 先移除红黑树隐含的双向链表中的元素
b. 再移除红黑树中的元素
c. 如果符合一个复杂的条件,那么红黑树会退化为链表

若有收获,就点个赞吧
0 人点赞
