AR概念
AR:增强现实(Augmented Reality,简称AR)。是将虚拟的物体放在我们周边的现实环境,增强现实世界的感官体验。
维基百科的定义:
“Augmented reality (AR) is a live direct or indirect view of a physical, real-world environment whose elements are augmented (or supplemented) by computer-generated sensory input such as sound, video, graphics or GPS data. As a result, the technology functions by enhancing one’s current perception of reality.”
AR与VR的区别:
AR里面的信息是叠加到真实的场景里面的,而不是虚拟的场景(即VR)里面的。
VR基于虚拟生成,AR则基于对现实的加工
ar模型无需左右移动寻找平面
此类ar模型对平面的要求低,只要摄像头里出现平面即可。例子:Ikea place、wow ar
ar模型免加载
此类ar模型已打包在app安装包中,会使得安装包变大,但加载迅速无需等待。例子:wow ar
反之,从服务器云端下载的模型受到模型大小与网络条件的约束,加载过程容易耗时较长,带来不好的用户体验。但可使得安装包体积较小。例子:vuforia view、jigspace、civilization
图:模型在安装包中,安装包大 图:模型从云端下载,安装包小
技术
AR的技术中,最主要的技术点主要有三个:
- 捕获特征图像(识别)
- 跟踪特征图像的移动
- 计算捕获的特征图像相对于原特征图像的偏移向量
AR物体叠加技术过程
- 事先将目标物体的特征点采集好,并将预置体放在某些特征点上。
- 手机传感器(摄像头、陀螺仪、深度…)采集并返回环境特征点,经过算法、xx融合后,将特征点传给AR SDK中的slam
- AR SDK中封装的slam技术根据特征点寻找平面,建立目标物体点云
- AR SDK找到点云中的目标特征点作为锚定点,加载出叠加预置体
平面图像检测法
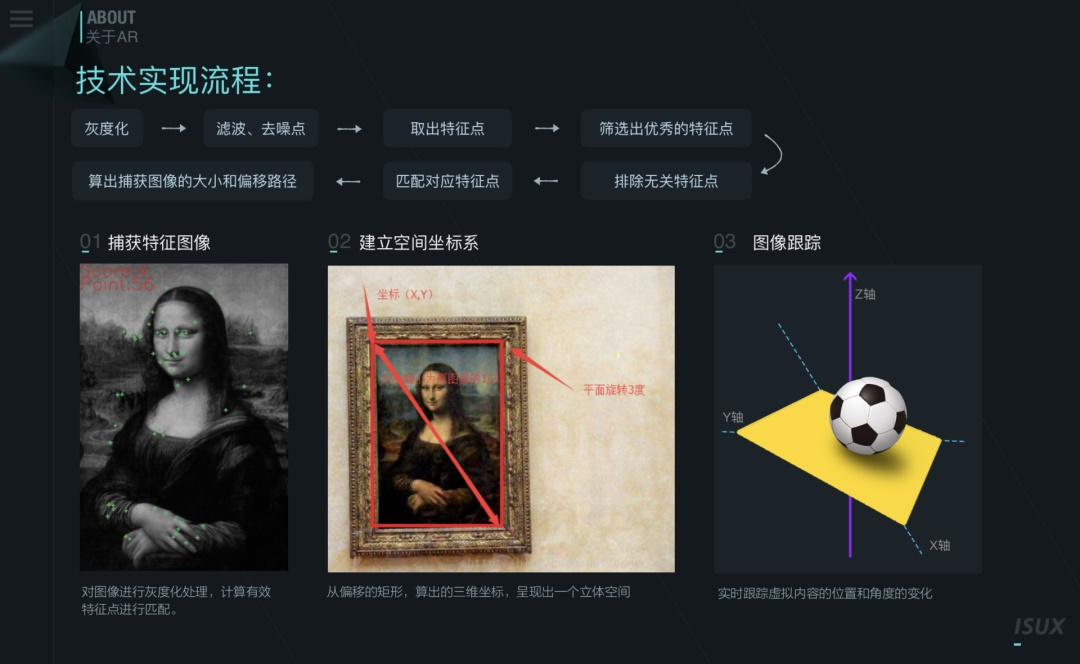
特征点:顾名思义,就是图像中或者全局或者局部的一种能够描述图片特征的具有标识性的点。一般情况下,特征点是指的是图像灰度值发生剧烈变化的点或者在图像边缘上曲率较大的点(即两个边缘的交点)。听起来有点像是角点,但是实际是角点只是特征点中的一类。
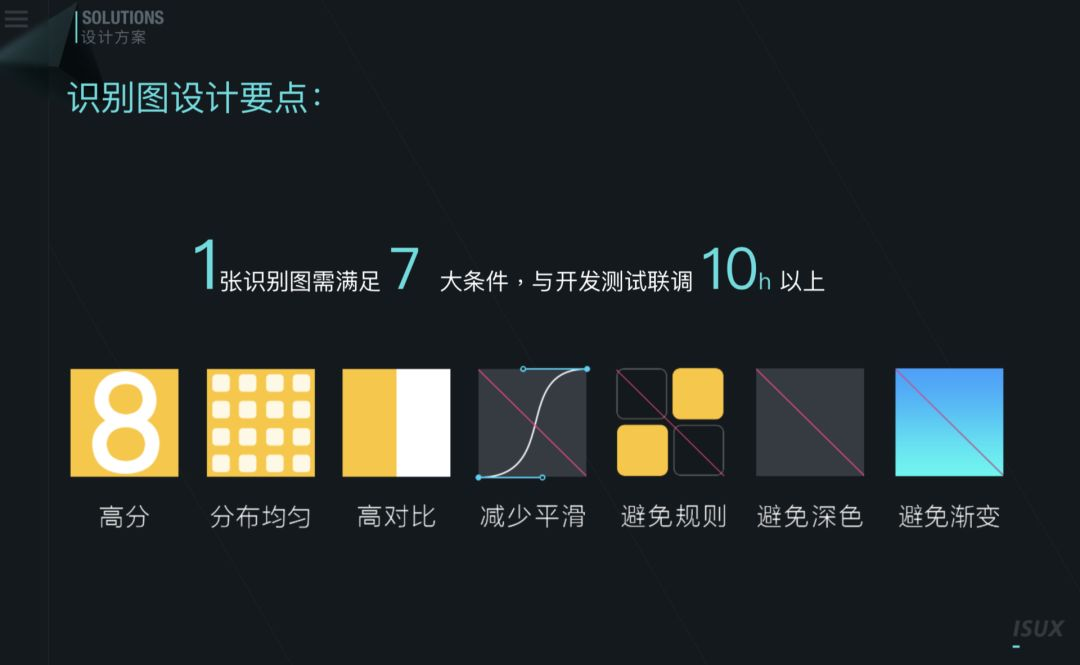
分布均匀:特征点需要平均分布在每一个角落
高对比:算法在灰度对比度高的情况下会形成更多的有效特征点
减少平滑:算法会排除掉一些比较平滑的曲线或元素,视为无效特征点
避免规则和重复:重复出现的规则图形会被算法判定为无效特征点并排除掉
我们的手机对于深色还有渐变颜色进行对焦时会较慢显现

应用场景:美颜相机特效
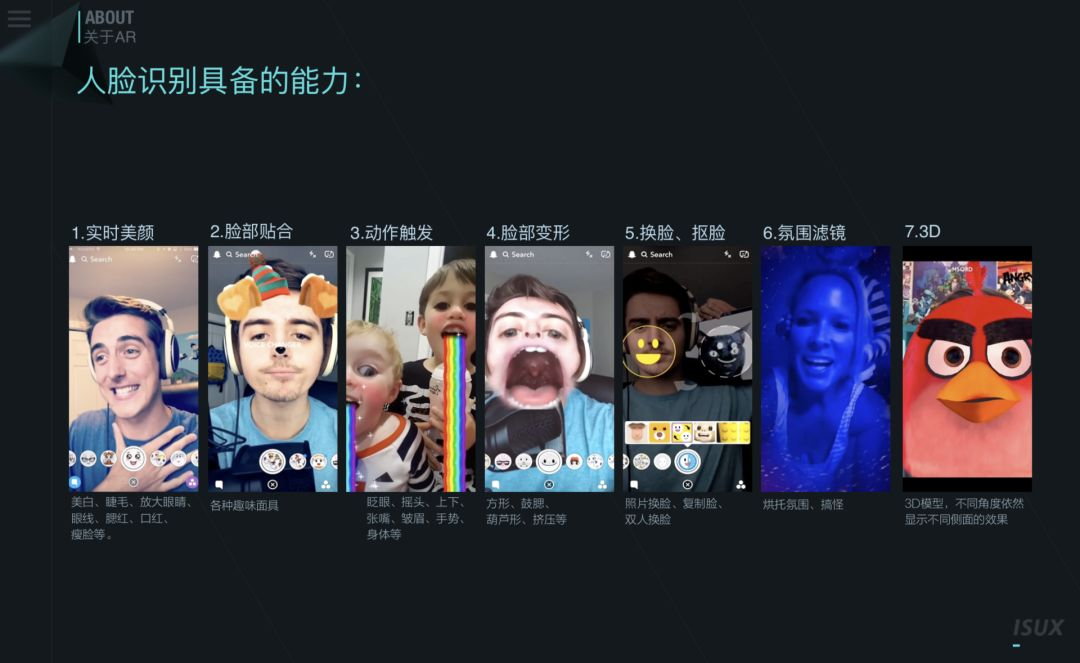
两种实现路径:
| 技术 | 简单ar(平面图像追踪) | 物体检测+深度学习 |
|---|---|---|
| 举例 | 人民币、可乐瓶、二维码 | - 美颜相机:人脸、人体、手势特效 - 硬装辅助:插拔线缆、防尘塞,依然可正常叠加预置体 |
| 原理 | 识别特征点 | 机器学习大量目标图片 |
| 优势 | - 识别快,叠加准 - 仿射变换(2D->2D),计算快,无需计算Z坐标值 |
- 适应性强(物体有变化也可识别) - 可检测(认识)80-100类物体 |
| 劣势 | - 适应性差,对象不能有变化 - 对被贴图对象要求高,形状要规则 |
- 训练机器耗时长 - 计算映射耗时长(叠加物坐标->世界坐标,需计算Z坐标值) - 容易叠加不准(因计算耗时长,截取帧t与当前帧t+n会有一个n时差,而用户手持不能保持完全稳定,导致两帧不一致) |
简单AR叠加(平面图像追踪)
后台只采集了特定图像的的特征点,手机采集并生成的特征点需与后台完全一致才能ar贴图成功
增加深度学习的AR叠加
针对某类物体(eg:人脸)进行大量的图片学习,系统有了积累了某类图像的大量特征点信息。当手机采集到物体特征点,哪怕和后台特征点不完全一致,也可以识别出来成功贴图
此方法容易叠加不准,是因为计算耗时长,截取帧时间 t 与当前帧时间 t+n 之间会有一个时差n。而用户手持不能保持完全稳定,在n时间段内会抖动,使得两帧图像不完全一致。使得针对截取帧生成的叠加图叠加在当前帧上时,发生叠加不准错位的问题。
优化思路:引导用户尽量保持稳定,减小抖动幅度。
优化方法:在界面上画一个目标位置框,引导用户将物体尽量稳定的放在框中。

叠加不准的问题会在美颜相机人脸特效这块出现吗 ?原因和我们这个一样吗?要求不精准,错位也看不出来?
——一样的,但人脸检测计算技术成熟,计算一次若在30ms内,可达到实时效果
银行人脸验证的时候出现人脸框也是为了解决这个问题?
——精度高,准确度好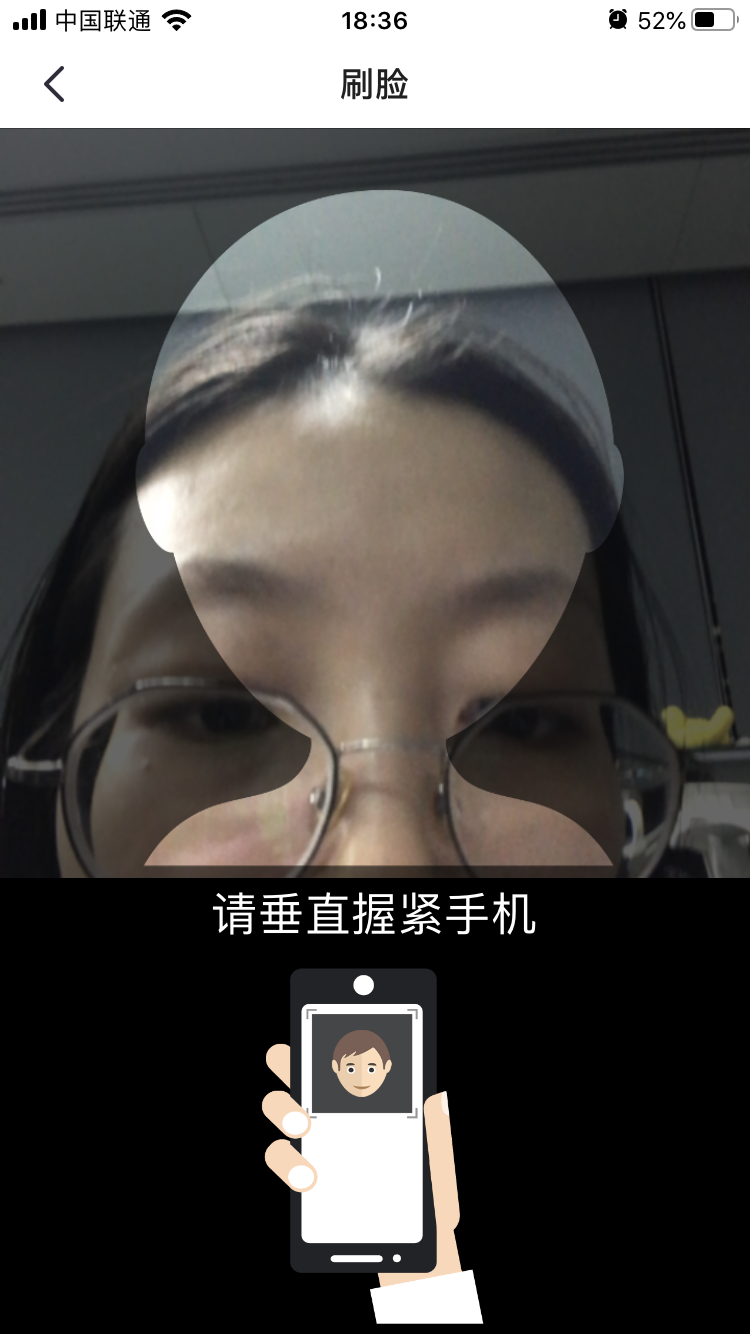
环境ar
使用激光扫描仪采集环境特征点(工作量很大),针对特征点叠加好预置体。当手机对准环境采集到特征点后,后台进行比对,相合后,叠加出预置体。
例子:圆明园修复图、华为河图
异常情况原因
发生叠加的预置体位置偏移、消失等异常情况,是因为步骤2发生错误,而步骤2出错的原因是步骤1。其中不论是手机传感器返回的特征点错位,还是算法、融合过程出错,都有可能导致错误发生。
slam会实时采集环境数据,更新点云,1秒30帧以上,所以人眼看起来图像是稳定贴在目标物体上而不会发生闪动现象。
安卓与unity配合流程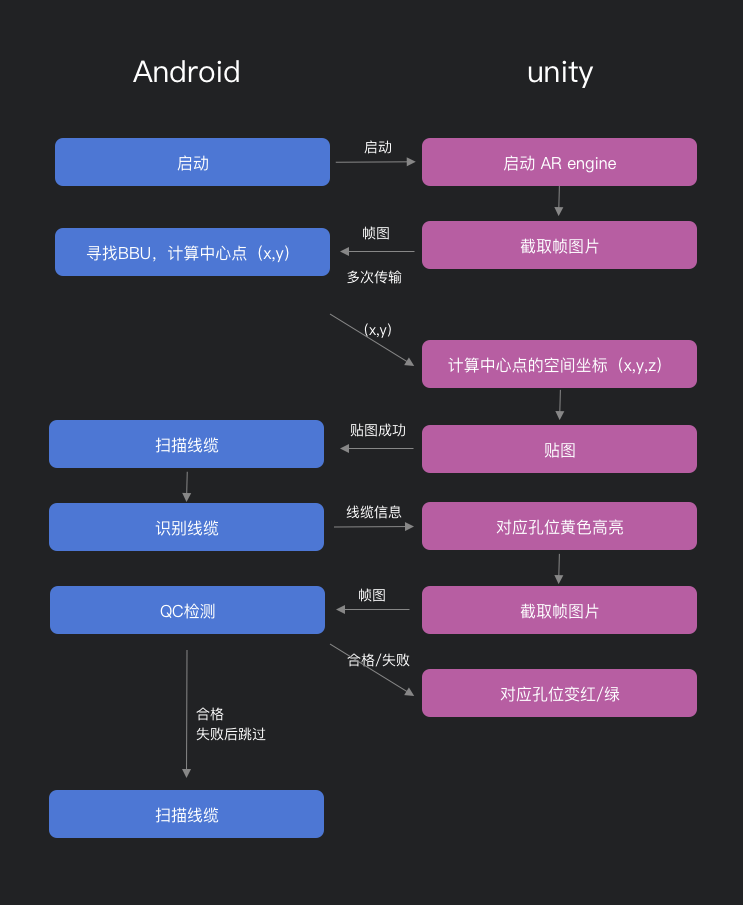
AR环境叠加
- 识别平面,放置虚拟物体到环境中
- 全球卫星定位系统法
全球卫星定位系统法是利用 GPS 去定位我们所处的位置,在真实的空间里寻找一个平面,可以现实世界中跟虚拟物体进行互动和观赏。
优点是适合于室外的跟踪,可以克服在室外场景中光照,还有聚焦等不确定因素,而缺点是很考验设备的性能,包括当前网络的环境。
应用案例:日本游戏,寻找梦可宝
AR sdk
AR sdk:开发工具包(封装了slam等技术)
常见AR sdk:
- AR kit(苹果)
- AR core(谷歌安卓)
- AR engine(华为)
- Vuforia
-
ARCore 使用三个主要功能将虚拟内容与通过手机摄像头看到的现实世界整合: 运动跟踪让手机可以理解和跟踪它相对于现实世界的位置。
- 环境理解让手机可以检测各类表面(例如地面、咖啡桌或墙壁等水平、垂直和倾斜表面)的大小和位置。
光估测让手机可以估测环境当前的光照条件。
平面图像跟踪——对目标图片有些要求(见上面平面图像检测法)
- EasyAR 3D 物体跟踪
- EasyAR 表面跟踪
EasyAR表面跟踪(surface tracking)实现轻量级的持续跟踪设备相对于空间中选定表面点的位置和姿态的能力,可用于小型AR交互游戏、AR短视频拍摄以及产品放置展示等场景。 相比较与EasyAR运动跟踪(motion tracking), 表面跟踪无需初始化且支持更多机型。
Surface Tracking的世界坐标系和相机坐标系都采用右手坐标系,y轴向上,z轴指向屏幕观测者,x轴指向屏幕观测者的右侧。
表面跟踪的工作原理
为了在真实空间和虚拟空间之间建立对应关系,表面跟踪利用相机和惯性测量单元的数据。表面跟踪识别相机图像中的重要特征,使用连续视频帧和IMU数据跟踪这些特征的位置。 虚拟物体被放置在相应的特征点的位置并持续跟踪。启动时虚拟物体默认被放置在屏幕中间附近的特征点表面,并将虚拟物体的位置视为世界坐标系的原点。在移动设备期间,相机图像中的特征深度不断更新,虚拟物体持续贴合在相应的特征点表面。如果虚拟物体所对应的特征点丢失,系统自动选择新的特征点并输出设备相对于该特征点的位置和姿态。注意这种情况下可能导致虚拟物体的位置发生漂移。
最佳体验和限制
- 只能放置一个虚拟物体,且虚拟物体的底部要放置在坐标系原点。
- 运行设备需要有相机,加速度计和陀螺仪。
CPU达到或超过Snapdragon 410计算能力。
EasyAR 运动跟踪
功能简介
Motion Tracking用于持续追踪设备在空间中的六自由度位置和姿态,可用于AR展示,AR游戏,AR视频或拍照等应用。
通过运动跟踪,虚拟物体和真实场景实时对齐与同一坐标系,可以体验到虚拟内容和真实场景融合在一起的感受。如果有持久化AR需求,建议配合EasyAR稀疏空间地图(SparseSpatialMap)使用。如果有遮挡碰撞需求,建议配合EasyAR稠密空间地图(DenseSpatialMap)使用。
Motion Tracking中的世界坐标系和相机坐标系都采用右手坐标系,y轴向上,z轴指向屏幕观测者,x轴指向屏幕观测者的右侧。
运动跟踪的工作原理
运动跟踪通过视觉惯性同步定位和建图(VISLAM)技术,计算设备相对于真实空间的位姿关系。在设备移动过程中,通过识别相机图像中显著特征点并跟踪其位置变化,结合设备的IMU数据信息,实时计算当前设备相对于真实世界的位置和姿态。
- 真实尺度
利用设备的惯导传感器和相机图像数据融合,恢复真实物理尺度,位置的单位是米。
- 鲁棒准确的运动跟踪
VISLAM算法相比纯视觉SLAM能极大降低长时间跟踪的漂移,且对于光照变化、弱纹理区域和动态物体等更鲁棒。
- 快速初始化
只需要相机对着应用场景横移1-2次即可实现初始化。初始化完成时的位置定义为世界坐标系的原点,根据重力方向和屏幕朝向,将初始化姿态朝向屏幕。初始化完成后自动开启位姿跟踪。
- 快速重定位
在设备跟踪丢失后/跟踪不佳后快速准确地恢复设备相对于世界坐标系的位姿,重定位前后世界坐标系原点不变,保证跟踪的持续性和准确性。在初始化区域附近具有位姿校正能力从而消除长距离运动产生的累计误差。
- 点击碰撞
拓展了解
SLAM技术
- SLAM,全称是Simultaneous Localization and Mapping,即同时定位与建图,指机器人在自身位置不确定的条件下,在完全未知环境中创建地图,同时利用地图进行自主定位和导航。因此可知SLAM的主要工作是定位以及建图。
- 目前SLAM有很多实现方法,根据使用传感器不同,主要分为:
(1)激光雷达传感器;
(2)视觉传感器;
- 视觉SLAM(Visual SLAM 简称VSLAM)包括使用单目SLAM、双目SLAM和以Kinect为代表的深度摄像头的RGB-D SLAM。相比使用激光雷达传感器,视觉传感器的成本更低,因此也越来越受青睐。
目前SLAM被广泛应用于无人驾驶汽车、无人机、VR和AR等领域。
三维环境的AR跟踪
对于三维环境的动态的实时的理解是当前AR在技术研究方面最活跃的问题。其核心就是最近火热的“即时定位与地图构建”(SLAM,Simultaneously Localization And Mapping)。AR中的SLAM比其他领域中一般难度要大很多,主要是因为AR赖以依存的移动端的计算能力和资源比起其他领域来说要弱很多。目前在AR中还是以视觉SLAM为主,其他传感器为辅的局面,尽管这个情况正在改变。下面的讨论主要局限于视觉SLAM。
标准的视觉SLAM问题可以这么描述为:把你空投到一个陌生的环境中,你要解决“我在哪”的问题。这里的“我”基本上等同于相机或者眼睛(因为单目,即单相机,请把自己想象成独眼龙),“在”就是要定位(就是localization),“哪”需要一张本来不存在的需要你来构建的地图(就是mapping)。你带着一只眼睛一边走,一边对周边环境进行理解(建图),一边确定在所建地图中的位置(定位),这就是SLAM了。换句话说,在走的过程中,一方面把所见到(相机拍到)的地方连起来成地图,另一方面把走的轨迹在地图上找到。下面我们看看这个过程大致需要哪些技术。
从图像序列反算出三维环境的过程,即mapping,在计算机视觉里面属于三维重建的范畴。在SLAM中,我们要从连续获取的图像序列来进行重建,而这些图像序列是在相机的运动过程中采集的,所以相关的技术就叫基于运动的重建(SfM,Structure from Motion)。题外话,SfX是视觉中泛指从X中进行三维重建的技术,X除了运动以外还可以有别的(比如Structure from Shading)。如果相机不动怎么办?很难办,独眼龙站着不动怎么能知道周围三维的情况呢?原理上来说,一旦获取的两张图像之间有运动,就相当与有两个眼睛同时看到了场景(注意坑,这里假设场景不动),不就可以立体了吗?这样一来,多视几何的东西就派上用场了。再进一步,运动过程中我们得到的实际是一系列图像而不只是两张,自然可以用他们一起来优化提高精度,这就是令小白们不明觉厉的集束约束(Bundle Adjustment)啦。
那么localization又是怎么回事呢?如果有了地图,即有了一个坐标系,定位问题和前述2D跟踪在目的上基本一致(当然更复杂一些)。让我们考虑基于控制点的方法,那么现在就需要在三维空间找到并跟踪控制点来进行计算了。很巧的是(真的很巧吗?),上面的多视几何中也需要控制点来进行三维重建,这些控制点就经常被共用了。那么可不可以用直接法呢?Yes we can!但是,如后面会讲到的,由于目前AR中计算资源实在有限,还是控制点法经济实惠些。
从三维重建的方法和结果,SLAM大致可以分为稀疏、半稠密和稠密三类。图10中给出的典型的示例。
稠密SLAM:简单的说,稠密SLAM的目的是对所相机所采集到的所有信息进行三维重建。通俗的说,就是对看见的每一个空间上的点算出它到相机的方位和距离,或者知道它在物理空间的位置。在AR相关的工作里面最近的影响力较大的有DTAM和KinectFusion,前者是纯视觉的,后者则使用了深度相机。由于需要对几乎所有采集到的像素进行方位计算,稠密SLAM的计算量那是杠杠的,所以不是平民AR(比如一般的手机,手握6S/S7/Mate8的朋友不要侧漏傲气,这些统统都算“一般”)。
稀疏SLAM:稀疏SLAM的三维输出是一系列三维点云。比如三维立方体的角点。相对于实心的三维世界(比如立方体的面和中腹),点云所提供的对于三维环境的重建是稀疏的,是以得名。实际应用中,在这些点云的基础上提取或推理出所需要的空间结构(比如桌面),然后就可以根据这些结构进行AR内容的渲染叠加了。和稠密SLAM版本相比,稀疏SLAM关心的点数低了整整两个维度(从面堕落到点),理所当然地成为平民AR的首选。目前流行的稀疏SLAM大多是基于PTAM框架的一些变种,比如最近被热捧的ORB-SLAM。
半稠密SLAM:顾名思义,半稠密SLAM的输出密度在上述二者之间,但其实也没有严格的界定。半稠密SLAM最近的代表是LSD-SLAM,不过对于在AR中的应用,目前还没有稀疏SLAM热门。
由于稀疏SLAM在AR中的流行度,下面我们简单介绍一下PTAM和ORB-SLAM。在PTAM之前,由A. Davison在2003年提出的单目SLAM开创了实时单目SLAM的先河。这个工作的基本思想还是基于当时机器人等领域的主流SLAM框架的。简单地说,对于每一帧新到来的图像,进行“跟踪-匹配-制图-更新”的流程。然而这个框架在移动端(手机)上的效果和效率都不尽人意。针对移动端AR的SLAM需求,Klein和Murray在 2007年的ISMAR(AR领域的旗舰学术会议)展示了效果惊艳的PTAM系统,从而成为单目视觉AR SLAM的最常用框架,暂时还是之一。
PTAM的全称是Parallel Tracking And Mapping,上面已经暗示过了,PTAM和之前的SLAM在框架是不同的。我们知道,SLAM对每一帧同时(Simultaneously)进行两个方面的运算:定位(Localization)和建图(Mapping)。由于资源消耗巨大,这两种运算很难实时的对每一帧都充分地实现。那我们一定要每一帧都同时定位和建图吗?先看定位,这个是必须每帧都做,不然我们就不知道自己的位置了。那么制图呢?很幸运,这个其实并不需要每帧都做,因为隔上几帧我们仍然可以通过SfM来感知场景。试想一下,把你扔到一个陌生的场景,让你边走边探索周边环境,但是每秒钟只让你看10眼,只要你不是在飞奔,相信这个任务还是可以完成的。PTAM的核心思想就在这里,不是simultaneously定位和制图,而是把他们分开,parallel地各自奔跑。这里的定位以逐帧跟踪为主,所以就有了tracking。而制图则不再逐帧进行,而是看计算能力而定,啥时候处理完当前的活,再去拿一帧新的来看看。在这个框架下,再配合控制点选取匹配等各项优化组合,PTAM一出场就以其在华丽丽的demo亮瞎观众(这可是近10年前啊)。
故事显然没有这样结束。我们都知道,demo和实用是有差距滴,何况还是学术界的demo。但是在PTAM思想的指引下,研究人员不断的进行改进和更新。这其中的佼佼者就有上面提到的ORB-SLAM。ORB-SLAM由Mur-Artal, Montiel和Tardos在2015年发表在IEEE Transaction on Robotics上,由于其优异的性能和贴心的源码迅速获得工业界和学术界两方面的青睐。不过,如果打算通读其论文的话,请先做好被郁闷的心理准备。不是因为有太多晦涩的数学公式,恰恰相反,是因为基本上没有啥公式,而是充满了让人不明觉厉的名词。为什么会这样?其实和ORB-SLAM的成功有很大关系。ORB-SLAM虽然仍然基于PTAM的基本框架,不过,做了很多很多改进,加了很多很多东西。从某个角度看,可以把它看作一个集大成的且精心优化过的系统。所以,区区17页的IEEE双栏论文是不可能给出细节的,细节都在参考文献里面,有些甚至只在源码里。在众多的改进中,比较大的包括控制点上使用更为有效的ORB控制点、引入第三个线程做回环检测矫正(另外两个分别是跟踪和制图)、使用可视树来实现高效的多帧优化(还记得集束约束吗)、更为合理的关键帧管理、等等。
有朋友这里会有一个疑问:既然ORB-SLAM是基于PTAM的框架,那为啥不叫ORB-PTAM呢?是酱紫的:尽管从框架上看PTAM已经和传统SLAM有所不同,但是出于各种原因,SLAM现在已经演变成为这一类技术的统称。也就是说,PTAM一般被认为是SLAM中的一个具体算法,确切些说是单目视觉SLAM的一个算法。所以呢,ORB-PTAM就叫ORB-SLAM了。
尽管近年来的进展使得单目SLAM已经能在一些场景上给出不错的结果,单目SLAM在一般的移动端还远远达不到随心所欲的效果。计算机视觉中的各种坑还是不同程度的存在。在AR中比较刺眼的问题包括:初始化问题:单目视觉对于三维理解有着与生俱来的歧义。尽管可以通过运动来获得有视差的几帧,但这几帧的质量并没有保证。极端情况下,如果用户拿着手机没动,或者只有转动,算法基本上就挂掉了。
- 快速运动:相机快速运动通常会带来两方面的挑战。一是造成图像的模糊,从而控制点难以准确的获取,很多时候就是人眼也很难判断。二是相邻帧匹配区域减小,甚至在极端情况下没有共同区域,对于建立在立体匹配之上的算法造成很大的困扰。
- 纯旋转运动:当相机做纯旋转或近似纯旋转运动时,立体视觉无法通过三角化来确定控制点的空间位置,从而无法有效地进行三维重建。
- 动态场景:SLAM通常假设场景基本上是静止的。但是当场景内有运动物体的时候,算法的稳定性很可能会受到不同程度的干扰。
对AR行业动态有了解的朋友可能会有些疑惑,上面说的这么难,可是Hololens一类的东西好像效果还不错哦?没错,不过我们上面说的是单目无传感器的情况。一个Hololens可以买五个iPhone 6S+,那么多传感器不是免费的。不过话说回来,利用高质量传感器来提高精度必然是AR SLAM的重要趋势,不过由于成本的问题,这样的AR可能还需要一定时间才能从高端展会走到普通用户中。
SMART: 语义驱动的多模态增强现实和智能交互
单目AR(即基于单摄像头的AR)虽然有着很大的市场(想想数亿的手机用户吧),但是如上文所忧,仍然需要解决很多的技术难题,有一些甚至是超越单目AR的能力的。任何一个有理想有追求有情怀的AR公司(比如我亮风台J),是不会也不能局限于传统的单目框架上的。那么除了单目AR已经建立的技术基础外,AR的前沿上有哪些重要的阵地呢?纵观AR和相关软硬方向的发展历史和事态,横看今天各路AR诸侯的技术风标,不难总结出三个主要的方向:语义驱动,多模态融合,以及智能交互。遵循业界性感造词的惯例,我们将他们总结成:
SMART:Semantic Multi-model AR inTeraction
即“语义驱动的多模态增强现实和智能交互”。由于这三个方面都还在飞速发展,技术日新月异,我下面就勉强地做一个粗浅的介绍,表意为主,请勿钻牛角尖。
语义驱动:语义驱动在传统的几何为主导的AR中引入语义的概念,其技术核心来源于对场景的语义理解。为什么要语义信息?答案很简单,因为我们人类所理解的世界是充满语义的。如图11所列,我们所处的物理世界不仅是由各种三维结构组成的,更是由诸如透明的窗、砖面的墙、放着新闻的电视等等组成的。对于AR来说,只有几何信息的话,我们可以“把虚拟菜单叠加到平面上”;有了语义理解后,我们就可以“把虚拟菜单叠加到窗户上”,或者邪恶地“根据正在播放的电视节目显示相关广告”。
相比几何理解,对于视觉信息的语义理解涵盖广得多的内容,因而也有着广得多的应用。广义的看,几何理解也可以看作是语义理解的一个子集,即几何属性或几何语义。那么,既然语义理解这么好这么强大,为啥我们今天才强调它?难道先贤们都没有我们聪明?当然不是,只是因为语义理解太难了,也就最近的进展才使它有广泛实用的可能性。当然,通用的对任意场景的完全语义理解目前还是个难题,但是对于一些特定物体的语义理解已经在AR中有了可行的应用,比如AR辅助驾驶和AR人脸特效(图12)。
多模态融合:随着大大小小的AR厂家陆续推出形形色色的AR硬件,多模态已经是AR专用硬件的标配,双目、深度、惯导、语音等等名词纷纷出现在各个硬件的技术指标清单中。这些硬件的启用显然有着其背后的算法用心,即利用多模态的信息来提高AR中的对环境和交互的感知理解。比如,之前反复提到,作为AR核心的环境跟踪理解面临着五花八门的技术挑战,有些甚至突破了视觉算法的界限,这种情况下,非视觉的信息就可以起到重要的补充支持作用。比如说,在相机快速运动的情况下,图像由于剧烈模糊而丧失精准性,但此时的姿态传感器给出的信息还是比较可靠的,可以用来帮助视觉跟踪算法度过难关。
智能交互:从某个角度来看,人机交互的发展史可以看作是追求自然交互的历史。从最早的纸带打孔到如今窗口和触屏交互,计算机系统对使用者的专业要求越来越低。近来,机器智能的发展使得计算机对人类的自然意识的理解越来越可靠,从而使智能交互有了从实验室走向实用的契机。从视觉及相关信息来实时理解人类的交互意图成为AR系统中的重要一环。在各种自然交互中,基于手势的技术是目前AR的热点。一方面由于手势的技术比较成熟,另一方面也由于手势有很强的可定制性。关于手势需要科普的一个地方是:手势估计和手势识别是两个紧密相关但不同的概念。手势估计是指从图像(或者深度)数据中得到手的精确姿势数据,比如所有手指关节的3D坐标(图13);而手势识别是指判断出手的动作(或姿态)说代表的语义信息,比如“打开电视”这样的命令。前者一般可以作为后者的输入,但是如果手势指令集不大的情况下,也可以直接做手势识别。前者的更准确叫法应该是手的姿势估计。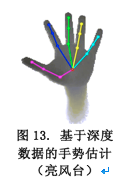
FOV:全称 Field of View,视场角。
摘自:
从计算机视觉的角度漫谈增强现实 (亮风台信息科技,凌海滨)
腾讯 AR 基础知识和设计实战案例复盘
阅读书目:
《增强现实技术导论》王涌天(AR的详细严谨的导论)
《视觉slam14讲》(博客笔记:https://blog.csdn.net/qq_23225073/article/details/88902650)

若有收获,就点个赞吧
0 人点赞
