Pre-training
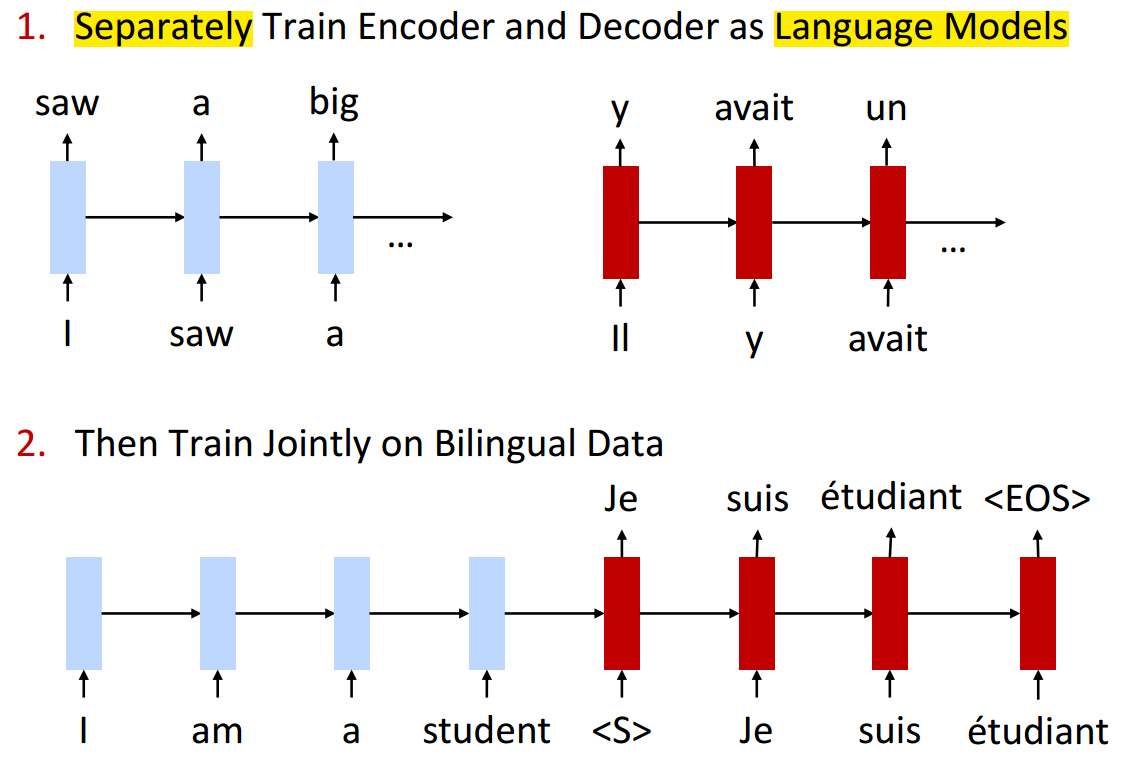
- 利用无标注数据进行预训练,可以提高性能
-
Self-Training
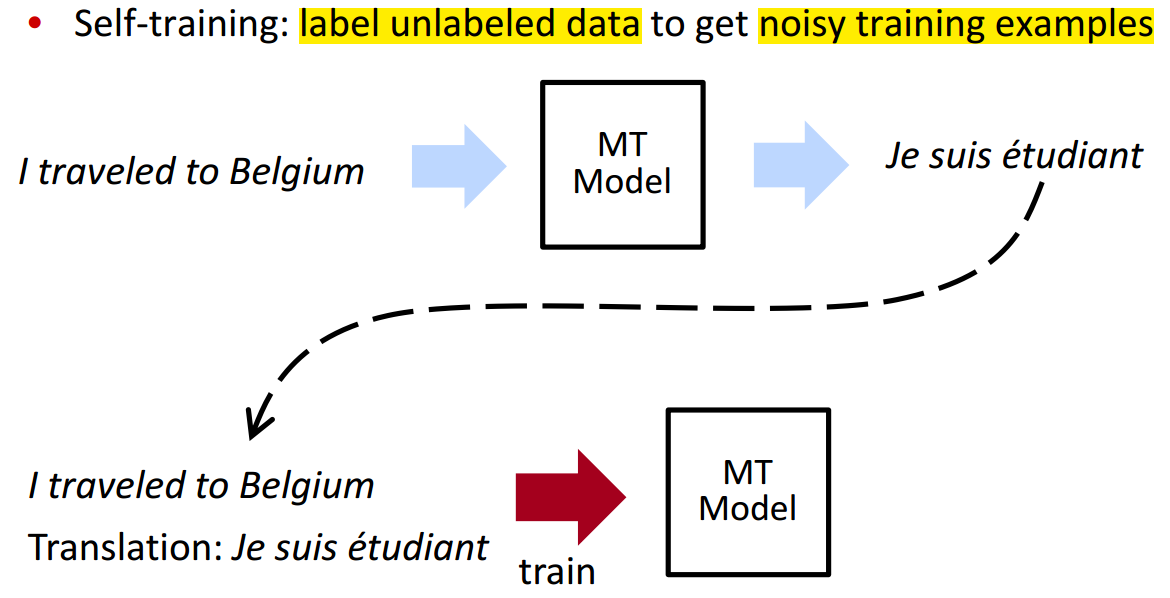
通过标注无标注的数据获得有噪声的训练样本
- 问题:存在循环回路,MT model 学习的是自己已经知道的内容
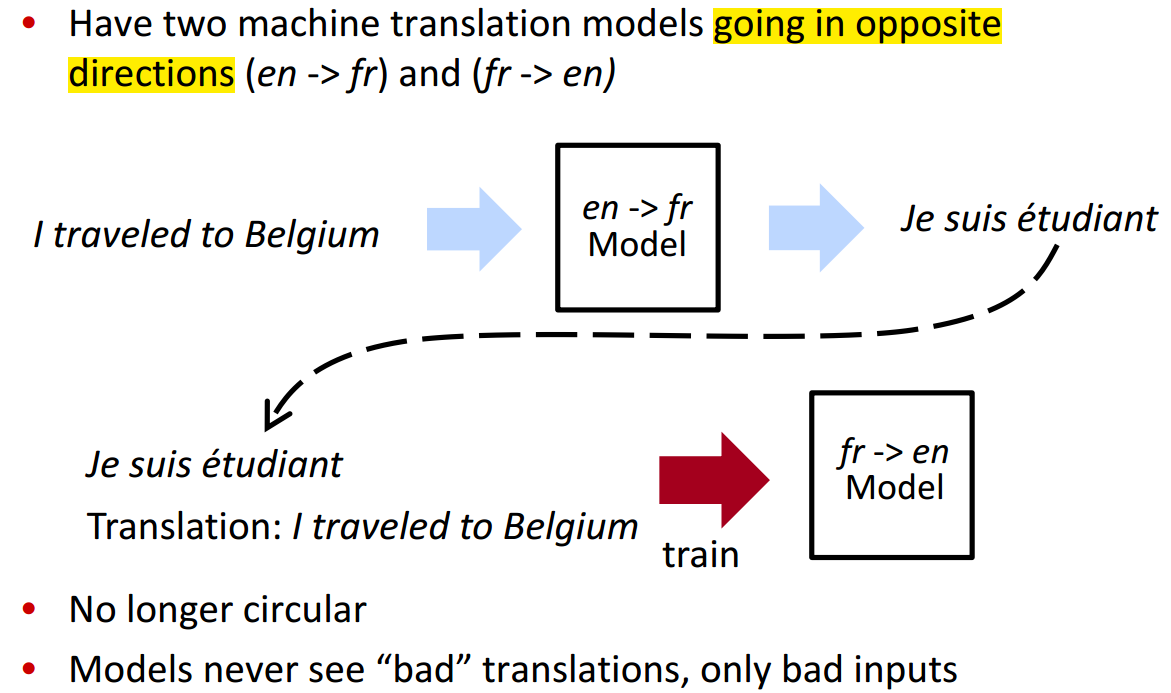
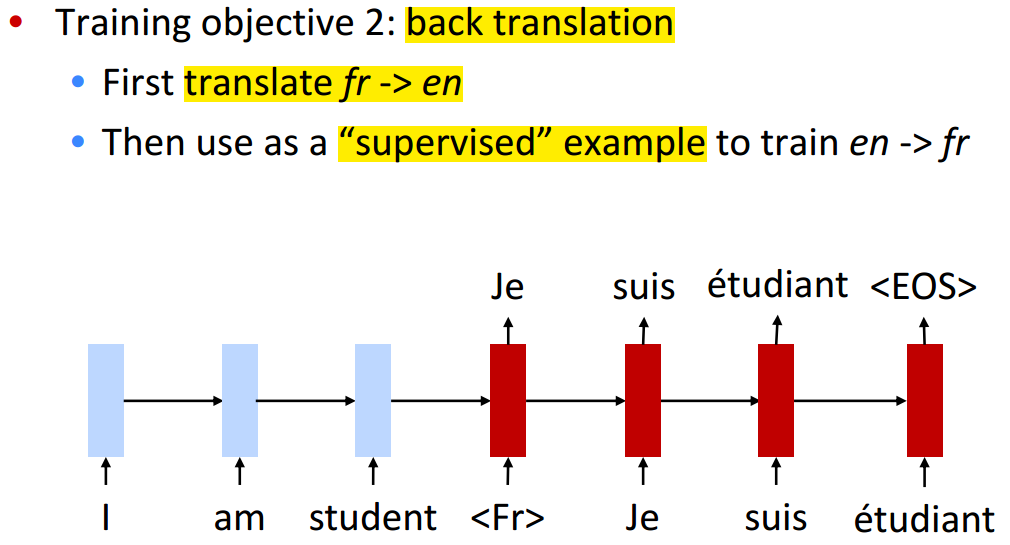
Back-Translation
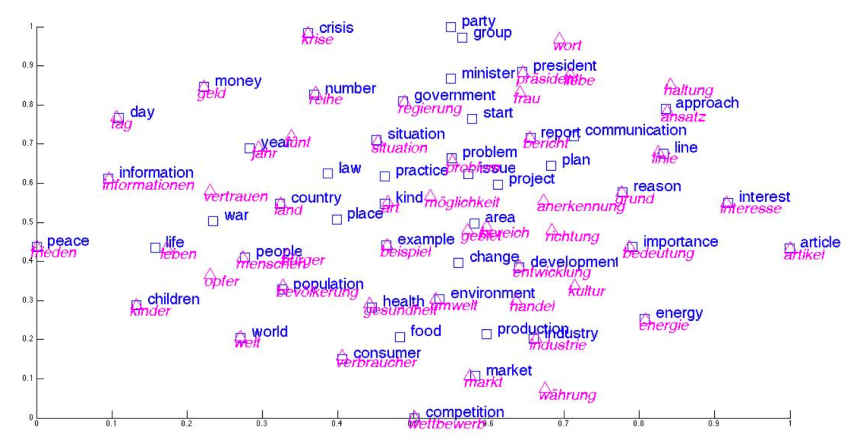
Unsupervised Word Translation
Cross-lingual word embeddings
- shared embedding space for both languages - words close to their translations - learn from monolingual corpora - Assumaption: structure should be similar across languages |
 |
|---|---|
训练方法:对抗训练


Unsupervised Machine Translation
核心思想
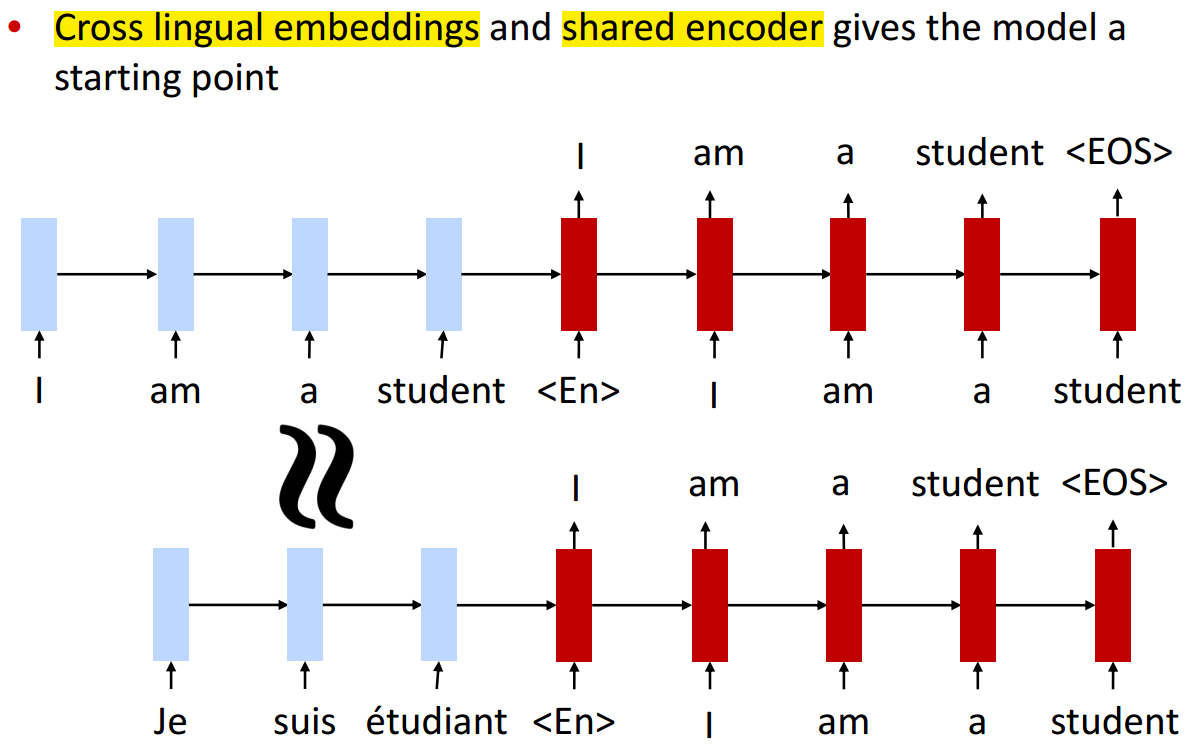
- model: same encoder-decoder used for both languages
- initialize with cross-lingual word embeddings
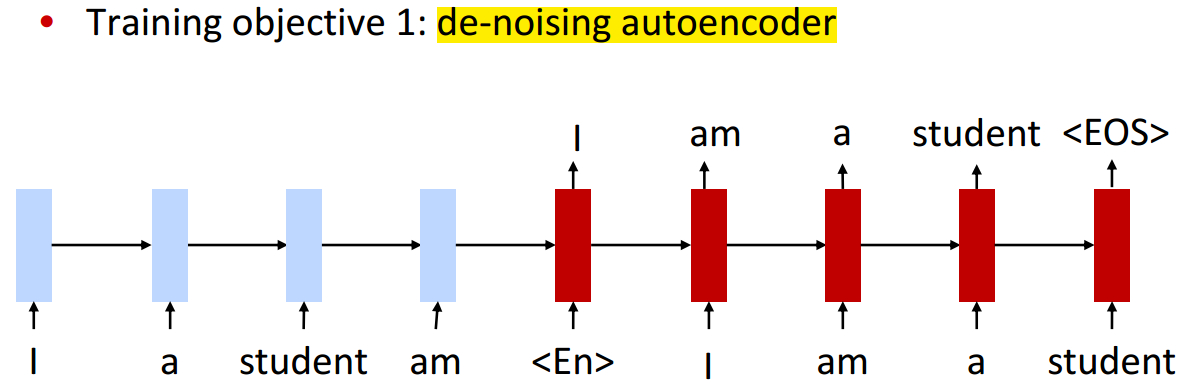
- 会输入一个标识输出的语言类型的字符,如
表示法语, 表示英语 训练目标
 |
 |
|---|---|
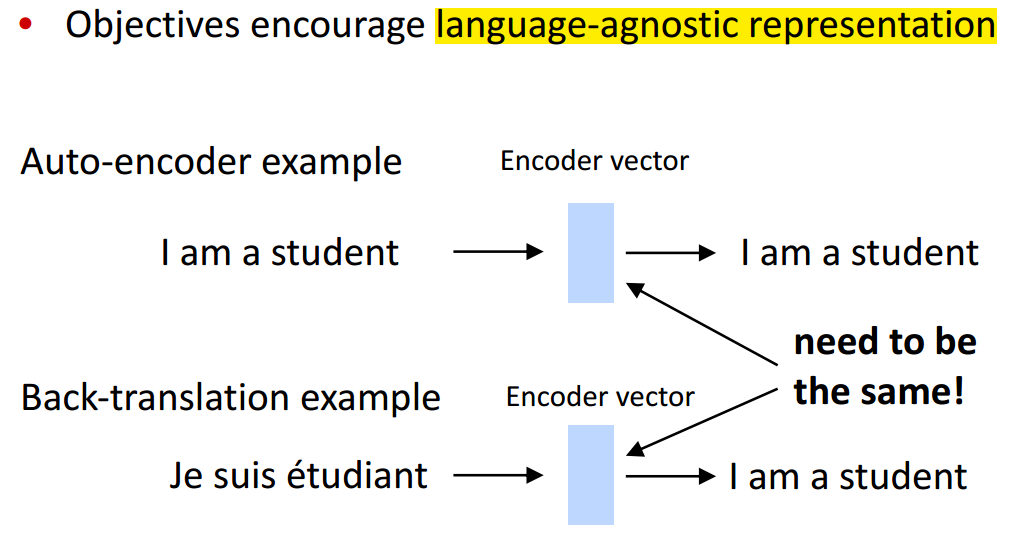
Why does this work?
 |
 |
|---|---|
问题
- 受语言之间的相似性的影响
- 相近的语言上表现较好,如英语、法语
- 相差较大的语言上效果不好,可能因为只有 word translation 效果有限,语法上差异也较大

若有收获,就点个赞吧
0 人点赞
