Word2Vec 基于迭代的方法
- hypothesis: distributional similarity , the idea that similar words have similar context.
- Word2Vec 是一个软件包,包括:
- 两个算法:CBOW,skip-gram
- 两个训练方法:negative sampling,hierarchical sofrmax
核心思路:通过使相似的单词的词向量在词向量空间中尽量接近来最大化目标函数
Language Models
为一串符号赋予概率的模型
需要能赋予语法正确、语义合适的句子较高的概率,反之应该赋予较低的概率
- 数学表达:

一些简单的例子
-
CBOW 中的模型
对每个单词,我们会学习两个词向量
- v: 输入向量 (当单词属于上下文时)
- u: 输出向量 (当单词处于中心时)
- CBOW 中的符号


 第 i 个单词
第 i 个单词 ,输出的中心单词的向量:
,输出的中心单词的向量:

 : 输入单词矩阵、输出单词矩阵,n 是一个任意选择的数,表示嵌入空间的大小。
: 输入单词矩阵、输出单词矩阵,n 是一个任意选择的数,表示嵌入空间的大小。 : V 的第 i 列和 U 的第 i 行,分别为单词
: V 的第 i 列和 U 的第 i 行,分别为单词 - 获得对应上下文的word vectors,并做平均


- 计算
 与每个单词的输出向量的相似度分数
与每个单词的输出向量的相似度分数

- 将与每个单词的输出向量的相似度分数转化为每个单词可能是中心单词的概率


- 希望得到的每个单词是中心单词的概率分布与实际情况一致(也就是中心单词的 one-hot 向量)
CBOW 的损失函数与优化
可以利用交叉熵来衡量两个概率分布之间的距离
交叉熵的定义:
对于 CBOW, 中只有一个元素
中只有一个元素 (中心单词对应的元素)为 1,其他的元素都是 0。有:
(中心单词对应的元素)为 1,其他的元素都是 0。有:
实际上,在这里,以交叉熵作为损失等价于最大似然概率
所以损失函数定义为:
进而:利用梯度下降/随机梯度下降法更新 。
。
Skip-Gram Model
 (中心单词),输出则有多个
(中心单词),输出则有多个 
- 获得中心单词的 word vector

- 计算中心向量的 word vector 与每个单词的 word vector 的相似度分数,获得 score vector

- 通过 score vector 计算出不同单词出现在上下文中的概率:

并且在上下文中每个位置上的单词出现的概率分别为: 。
。
 ,一致。
,一致。
- 假设:朴素贝叶斯假设,条件独立
- 优化目标:希望条件概率最大(最大似然估计),等价于 2m 个位置的分布的交叉熵最小



Negative Sampling
- 动机:CBOW 和 Skip-gram 的计算需要对整个 |V| 求和计算(softmax 过程中),计算量过大。考虑用其他方法来近似计算。
Negative Sampling 实际上改变的是优化目标,即损失函数。
基本思想
随便给定一对单词 (w,c),w 表示中心词,c 表示 w 的上下文,好的词向量应该能够判别出 c 是否的确是 w 的上下文,即这样的 (w,c) 是否存在于语料库中。
如何获取这样的 (w,c):
新的目标函数为:(给定中心单词 c ,观察到上下文单词 c-m+j )

 来表示 (w,c) 存在于语料库中,反之,
来表示 (w,c) 存在于语料库中,反之, 表示不存在于语料库中。具体可用 sigmoid 函数。
表示不存在于语料库中。具体可用 sigmoid 函数。
 表示的是未知参数,即输入向量矩阵与输出向量矩阵
表示的是未知参数,即输入向量矩阵与输出向量矩阵  。
。
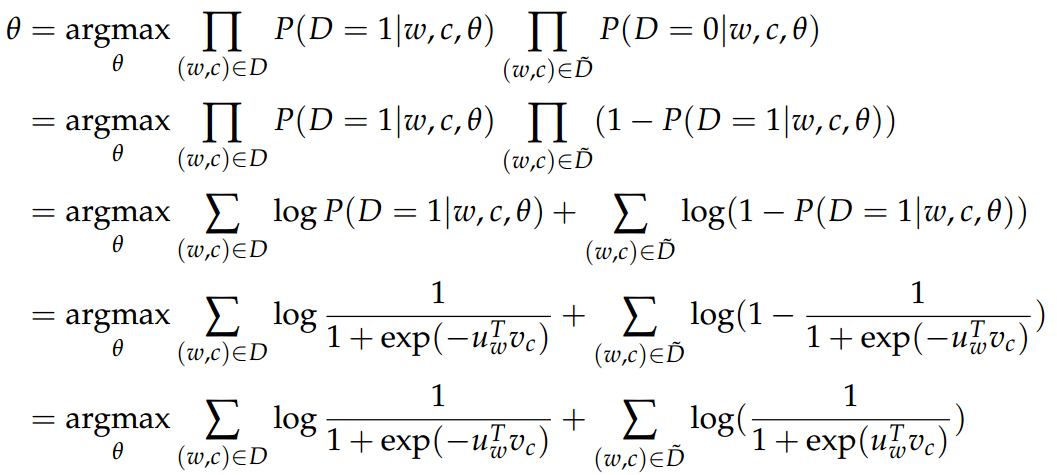
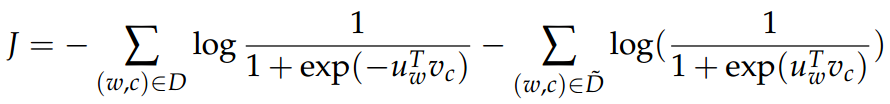
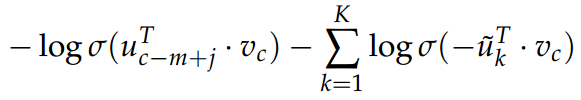
- 旧的目标函数 (softmax) 为:
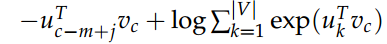
CBOW
- 新的目标函数为:(给定上下文向量 ,观察到中心单词 c)
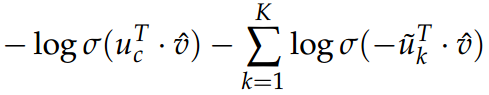
- 旧的目标函数为:
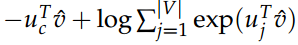
 是由
是由 噪声分布的选择
单词频率 unigram distribution 的3/4次幂
- 可以使低频词被采样更多的次数。
- Z:normalization term
- unigram distribution: 指的是根据单词出现频率得到的概率分布。

若有收获,就点个赞吧
0 人点赞
