基本思路
 的形式累计单词的共现次数。
的形式累计单词的共现次数。
 的行向量作为 word vector
的行向量作为 word vector
- 假设: 相关的单词经常出现在同一篇文档中。
构造方法:

构造方法:

- 计算每个单词在感兴趣的单词(目标单词)周围的一个固定大小的窗口中出现的次数
- 例子:窗口大小为 1
 :是词表的大小,
:是词表的大小, 是文档数
是文档数 加 1 。
加 1 。
对矩阵 X 进行 SVD 并降维
- Applying SVD to X
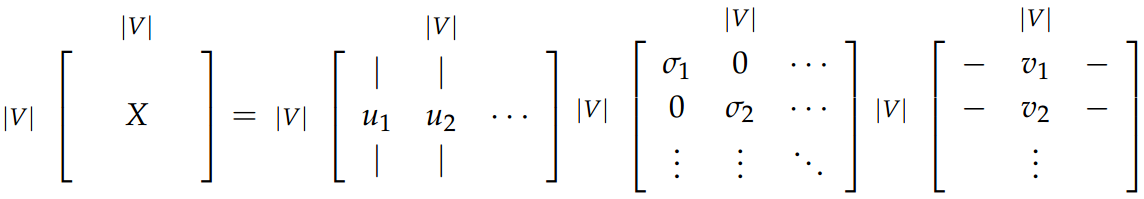
- Reducing dimensionality by selecting first k singular value
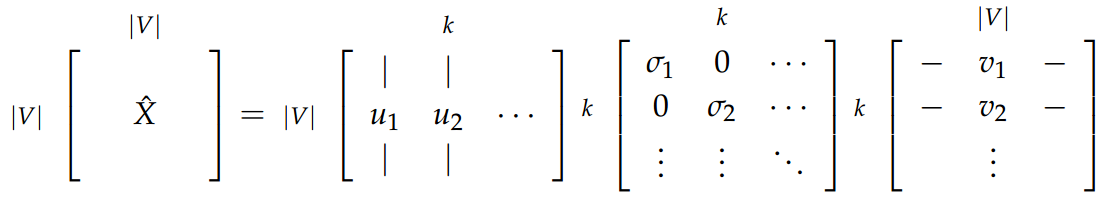
 来确定 k 的值,它指明了被前 k 个维度所捕捉到的方差的比例
来确定 k 的值,它指明了被前 k 个维度所捕捉到的方差的比例
- 矩阵 X 的维度会经常变化,因为经常会有新的单词。
- 矩阵 X 比较稀疏,因为大部分的单词不会同时出现。
- 通常 X 的维度比较高,

- 训练成本是二次的,要进行 SVD 。
- 需要额外的技巧去处理 X 中词频的不平衡性。

若有收获,就点个赞吧
0 人点赞
