GloVe 基本思想
动机
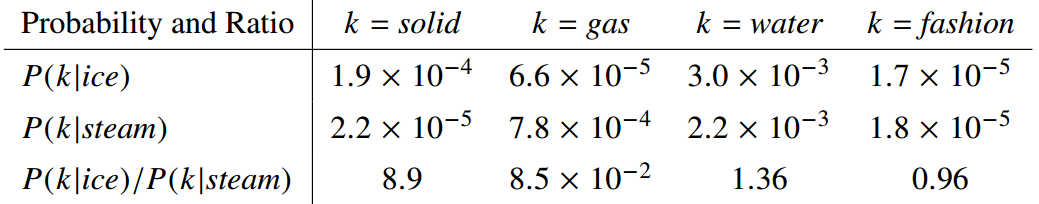
说明 word vector 学习的起点应该是共现概率的比值,而不是共现概率值本身
GloVe 基本概念与符号
共现计数矩阵 X
 :表示单词 j 在单词 i 的上下文中出现的次数
:表示单词 j 在单词 i 的上下文中出现的次数 :表示在单词 i 的上下文中出现的单词的总次数
:表示在单词 i 的上下文中出现的单词的总次数
共现概率
-
构造模型
 涉及到 3 个单词:i, j, k,所以模型可以表示为:
涉及到 3 个单词:i, j, k,所以模型可以表示为:
- 因为想要能够编码两个概率的比值信息,在线性空间中,最自然的方法就是做向量的差,所以模型可以进而考虑构造为

- 又因为最后的结果是一个具体的数值,所以可以进一步构造为:

- 因为交换
 后,值应该变为原来的导数,而且当
后,值应该变为原来的导数,而且当  时,值为 1。
时,值为 1。
 :单词 j 在单词 i 的上下文中出现的概率
:单词 j 在单词 i 的上下文中出现的概率

- 由上述的 F 的性质可知

- 即:
 。
。 - 不过,由于
 应该同样具有对称性,所以,要设法消除
应该同样具有对称性,所以,要设法消除  的影响。由于它与 k 无关,所以可以被放在
的影响。由于它与 k 无关,所以可以被放在  的 bias 项
的 bias 项  。
。 - 在此基础上,再为
 引入一个 bias 项
引入一个 bias 项  即可保持对称性。
即可保持对称性。
- 即:
- 最终得到:

损失函数
基于上述的模型,计算最小均方误差,并对所有的单词取加权和:
权重计算函数 应该满足:
应该满足:
选择的函数: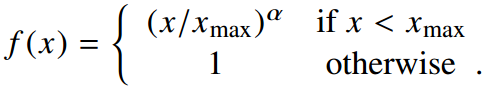
GloVe 与其他方法的关系
Skip-gram 模型
在 Skip-gram 模型中,建模的概率对象为: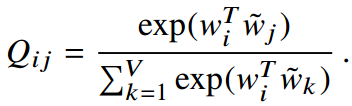
不过,建模的时候,用的是上下文窗口,而不是全部的语料。因此,当考虑全部语料时,隐含的全局损失函数为: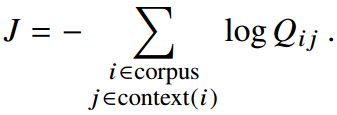
将同样的单词汇总起来,可以得到: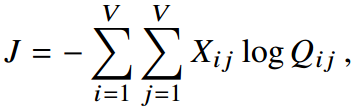
由: 可得:
可得: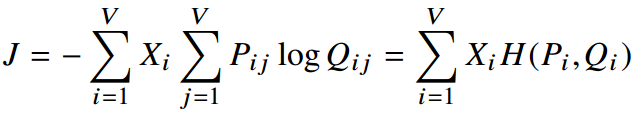
上述损失函数可以看作是全局的 Skip-gram 模型。不过,交叉熵不是唯一的用来衡量误差的方法,可以考虑用最小均方误差作为衡量。
使用一个去除分母的正则项的概率来计算最小均方误差:
因为 通常很大,所以可以考虑取对数后,再优化:
同样,以 为权重不一定是最优的。引入合适的权重函数,得到的损失函数便是 GloVe 方法中的损失函数:
为权重不一定是最优的。引入合适的权重函数,得到的损失函数便是 GloVe 方法中的损失函数:

若有收获,就点个赞吧
0 人点赞
