1.Es的分布式架构原理
1.ES对复杂分布式机制的透明隐藏特性
1.1分布式为了应对大数据量,开箱即用
1.2分片机制
1.3集群发现机制
1.4shard负载均衡
1.5shard副本,请求路由,集群扩容,shard重分配等。
2.ES垂直和水平扩容
2.1垂直扩容,采用更强大的服务器
2.2水平扩容,采用更多服务器组成集群
3.增加和删除节点的reblance,保持负载均衡
无论是增加节点,还是移除节点,分片都可以做到无缝的扩展和迁移。
4.master节点管理
5.节点对等的分布架构
1.每个节点都能接受所有请求
2.自动路由请求
3.相应查询结果的收集
2.Es写数据底层原理
es里的写流程,有4个底层的核心概念,refresh、flush、translog、merge
写入数据的流程
1.客户端选择一个node发送请求过去,这个node就是coordinating node(协调节点)
2.coordinating node,对document进行路由,将请求转发给对应的node(有primary shard)
3.实际的node上的primary shard处理请求,然后将数据同步到replica node
4.coordinating node,如果发现primary node和所有replica node都搞定之后,就返回响应结果给客户端
写数据底层原理
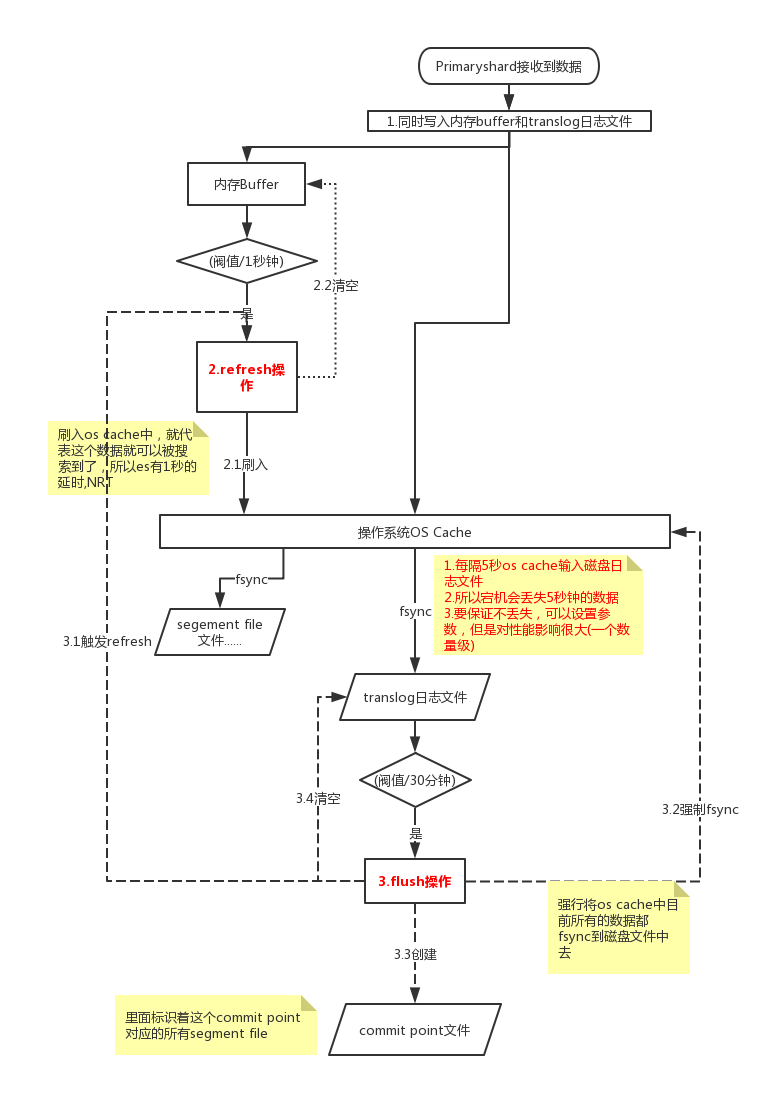
1.写入内存buffer,数据在buffer中的时候es是搜索不到的。同时写入translog日志文件
2.内存buffer满或者默认间隔1秒钟,会触发refresh操作。es将buffer中的数据写入segment file中,每秒钟会产生一个新的segment文件,这segment中就存储1秒钟内buffer中写入的数据。操作系统中磁盘文件都有os cache操作缓存,所以说数据写入磁盘前会进入os cache,只要buffer中的数据被refresh到os cache中es就可以搜索到了。这也就解释了为什么es的NRT近实时查询,写入数据到可以被搜索到有1秒的延迟。可以通过es的restful api或者java api,手动执行一次refresh操作,就是手动将buffer中的数据刷入os cache中,让数据立马就可以被搜索到。
只要数据被输入os cache中,buffer就会被清空了,因为不需要保留buffer了,数据在translog里面已经持久化到磁盘去一份了
3.只要数据进入os cache,此时就可以让这个segment file的数据对外提供搜索了
4。重复1~3步骤,新的数据不断进入buffer和translog,不断将buffer数据写入一个又一个新的segment file中去,每次refresh完buffer清空,translog保留。随着这个过程推进,translog会变得越来越大。当translog达到一定长度的时候,就会触发commit操作。
5.commit操作发生第一步,就是将buffer中现有数据refresh到os cache中去,清空buffer
6.将一个commit point写入磁盘文件,里面标识着这个commit point对应的所有segment file
7.强行将os cache中目前所有的数据都fsync到磁盘文件中去
8.将现有的translog清空,然后再次重启启用一个translog,此时commit操作完成。默认每隔30分钟会自动执行一次commit,但是如果translog过大,也会触发commit。整个commit的过程,叫做flush操作。我们可以手动执行flush操作,就是将所有os cache数据刷到磁盘文件中去。
不叫做commit操作,flush操作。es中的flush操作,就对应着commit的全过程。我们也可以通过es api,手动执行flush操作,手动将os cache中的数据fsync强刷到磁盘上去,记录一个commit point,清空translog日志文件。
9.translog其实也是先写入os cache的,默认每隔5秒刷一次到磁盘中去,所以默认情况下,可能有5秒的数据会仅仅停留在buffer或者translog文件的os cache中,如果此时机器挂了,会丢失5秒钟的数据。但是这样性能比较好,最多丢5秒的数据。也可以将translog设置成每次写操作必须是直接fsync到磁盘,但是性能会差很多。
10.如果是删除操作,commit的时候会生成一个.del文件,里面将某个doc标识为deleted状态,那么搜索的时候根据.del文件就知道这个doc被删除了
11.如果是更新操作,就是将原来的doc标识为deleted状态,然后新写入一条数据
12.buffer每次refresh一次,就会产生一个segment file,所以默认情况下是1秒钟一个segment file,segment file会越来越多,此时会定期执行merge
13.每次merge的时候,会将多个segment file合并成一个,同时这里会将标识为deleted的doc给物理删除掉,然后将新的segment file写入磁盘,这里会写一个commit point,标识所有新的segment file,然后打开segment file供搜索使用,同时删除旧的segment file。
3.ES的搜索工作原理
搜索流程
1.客户端发送请求到一个coordinate node
2.协调节点将搜索请求转发到所有的shard对应的primary shard或replica shard也可以
3.query phase:每个shard将自己的搜索结果(其实就是一些doc id),返回给协调节点,由协调节点进行数据的合并、排序、分页等操作,产出最终结果
4.fetch phase:接着由协调节点,根据doc id去各个节点上拉取实际的document数据,最终返回给客户端
搜索的底层原理
在Elasticsearch中,所有的字段缺省都建了索引。 也就是说每一个字段都有一个倒排索引,用于快速查询。
4.es在数据量很大的情况下如何提高查询性能
es说白了其实性能并没有你想象中那么好的。很多时候数据量大了,特别是有几亿条数据的时候,可能你会懵逼的发现,跑个搜索怎么一下5秒~10秒,坑爹了。第一次搜索的时候,是5~10秒,后面反而就快了,可能就几百毫秒。
1.性能优化的杀手锏——filesystem cache
os cache,操作系统的缓存
你往es里写的数据,实际上都写到磁盘文件里去了,磁盘文件里的数据操作系统会自动将里面的数据缓存到os cache里面去
es的搜索引擎严重依赖于底层的filesystem cache,你如果给filesystem cache更多的内存,尽量让内存可以容纳所有的indx segment file索引数据文件,那么你搜索的时候就基本都是走内存的,性能会非常高。
性能差距可以有大,我们之前很多的测试和压测,如果走磁盘一般肯定上秒,搜索性能绝对是秒级别的,1秒,5秒,10秒。但是如果是走filesystem cache,是走纯内存的,那么一般来说性能比走磁盘要高一个数量级,基本上就是毫秒级的,从几毫秒到几百毫秒不等
比如说,你,es节点有3台机器,每台机器,看起来内存很多,64G,总内存,64 3 = 192g
每台机器给es jvm heap是32G,那么剩下来留给filesystem cache的就是每台机器才32g,总共集群里给filesystem cache的就是32 3 = 96g内存
我就问他,ok,那么就是你往es集群里写入的数据有多少数据量?
如果你此时,你整个,磁盘上索引数据文件,在3台机器上,一共占用了1T的磁盘容量,你的es数据量是1t,每台机器的数据量是300g
你觉得你的性能能好吗?filesystem cache的内存才100g,十分之一的数据可以放内存,其他的都在磁盘,然后你执行搜索操作,大部分操作都是走磁盘,性能肯定差
当时他们的情况就是这样子,es在测试,弄了3台机器,自己觉得还不错,64G内存的物理机。自以为可以容纳1T的数据量。
归根结底,你要让es性能要好,最佳的情况下,就是你的机器的内存,至少可以容纳你的总数据量的一半
比如说,你一共要在es中存储1T的数据,那么你的多台机器留个filesystem cache的内存加起来综合,至少要到512G,至少半数的情况下,搜索是走内存的,性能一般可以到几秒钟,2秒,3秒,5秒
1.es中尽量少放字段,仅放要用户搜索的关键字段即可
2.尽量写入es的数据量跟es机器的filesystem cache是差不多的就可以了
3.建议用es + hbase的这么一个架构
2.数据预热
5.es生产集群的部署架构是什么,每个索引大概的数量,每个索引的分片数量

若有收获,就点个赞吧
0 人点赞
