1.BIO
同步阻塞IO(JAVA BIO):
同步并阻塞,服务器实现模式为一个连接一个线程,即客户端有连接请求时服务器端就需要启动一个线程进行处理,如果这个连接不做任何事情会造成不必要的线程开销.
网络服务为了同时响应多个并发的网络请求,必须实现为多线程的。每个线程处理一个网络请求。线程数随着并发连接数线性增长。这的确能奏效。实际上2000年之前很多网络服务器就是这么实现的。
但这带来个问题:
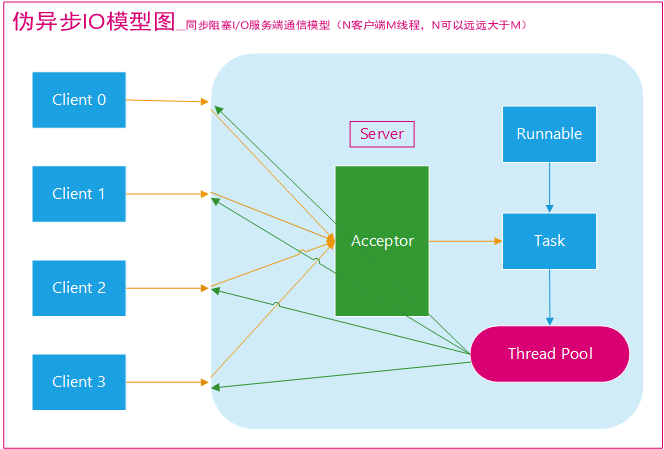
虽然线程池在一定程序上限制了线程的数量,也会造成在海量并发情况下的等待阻塞,这种方式称为伪异步IO。
BIO伪异步
public static void main(String[] args) throws Exception {final ServerSocket server = new ServerSocket(PORT);//最多有THREADPOOLSIZE个线程在accept()方法上阻塞等待连接请求for(int i=0;i<THREADPOOL_SIZE;i++){Thread thread = new Thread(){@Overridepublic void run(){//线程为某连接提供完服务后,循环等待其他的连接请求while(true){//阻塞等待try {Socket client = server.accept();System.out.println("与客户端连接成功");ServerThread.execute(client);} catch (IOException e) {e.printStackTrace();}}}};//开启线程thread.start();}}
BIO伪异步缺点
在读取数据较慢时(比如数据量大、网络传输慢等),大量并发的情况下,其他接入的消息,只能一直等待,这就是最大的弊端。
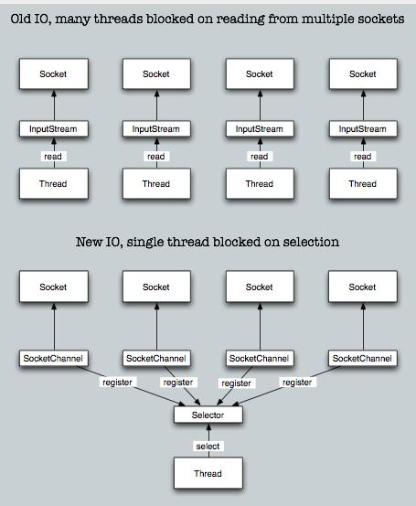
2.NIO
同步非阻塞I/O模型,通过使用多路复用器来解决I/O阻塞。
事件驱动模型避免多线程单线程处理多任务非阻塞I/O,I/O读写不再阻塞,而是返回0基于block的传输,通常比基于流的传输更高效更高级的IO函数,zero-copyIO多路复用大大提高了Java网络应用的可伸缩性和实用性支持文件所
1.缓冲buffer
所有Buffer都是抽象类,无法直接实例化。创建缓冲区要调用xxxBuffer.allocate(capacity),参数是缓冲区容量。
buffer是读写的中介,主要和NIO的通道交互。数据是通过通道读入缓冲区和从缓冲区写入通道的。
其实缓冲区buffer的本质就是一块可以读写的内存块。这块内存块被包装成NIO的Buffer对象,并提供了一组方法方便读写。
使用缓冲区有这么两个好处:
1、减少实际的物理读写次数
2、缓冲区在创建时就被分配内存,这块内存区域一直被重用,可以减少动态分配和回收内存的次数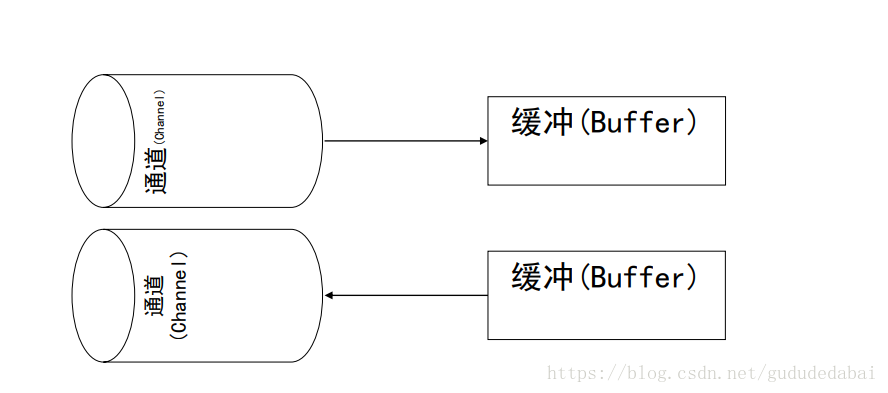
Buffer核心参数说明
| capacity(容量) | 缓冲区支持的最大容量 |
|---|---|
| position(记录指针位置) | 代表下一次的写入位置,初始值是 0,每往 Buffer 中写入一个值,position 就自动加 1 |
| limit(界限) | 表示缓冲区可以操作数据的大小。 (limit后数据不能进行读写) |
| mark(标记) | 表示记录当前position 的位置可以通过reset()来恢复到 mark的位置,初始为 -1 |
Buffer的常用方法
| flip() | 确定缓冲区数据的起始点和终止点,为输出数据做准备(即写入通道)。此时:limit = position,position = 0。在filp之后通常用于读 |
|---|---|
| clear() | 缓冲区初始化,准备再次接收新数据到缓冲区。position = 0,limit = capacity。 |
| compact() | 只清空已读取的数据,未被读取的数据会被移动到buffer的开始位置,写入位置则近跟着未读数据之后 |
| hasRemaining() | 判断postion到limit之间是否还有元素。 |
| mark()与reset()方法 这两个方法成对使用 |
通过调用Buffer.mark()方法,可以标记Buffer中的一个特定position。之后可以通过调用Buffer.reset()方法恢复到这个position。 |
| rewind() | postion设为0,则mark值无效。 |
| limit(int newLt) | 设置界限值,并返回一个缓冲区,该缓冲区的界限和limit()设置的一样。 |
| get()和put() | 获取元素和存放元素。使用clear()之后,无法直接使用get()获取元素,需要使用get(int index)根据索引值来获取相应元素。 |

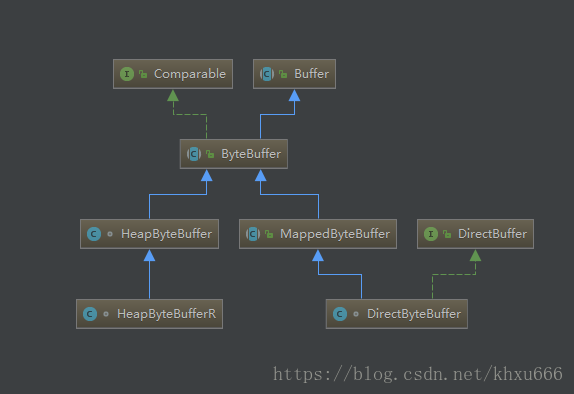
Buffer的实现类有哪些
- ByteBuffer
- CharBuffer
- DoubleBuffer
- FloatBuffer
- IntBuffer
- LongBuffer
- ShortBuffer
- MappedByteBuffer
直接缓冲区和非直接缓冲区
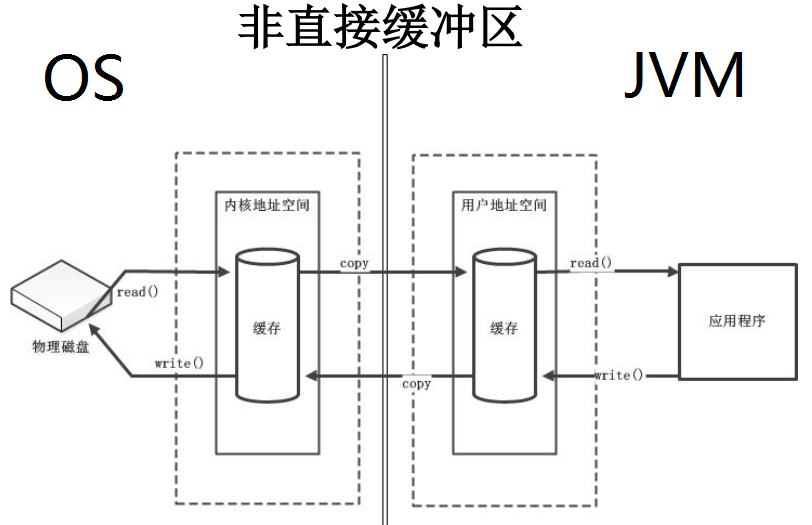
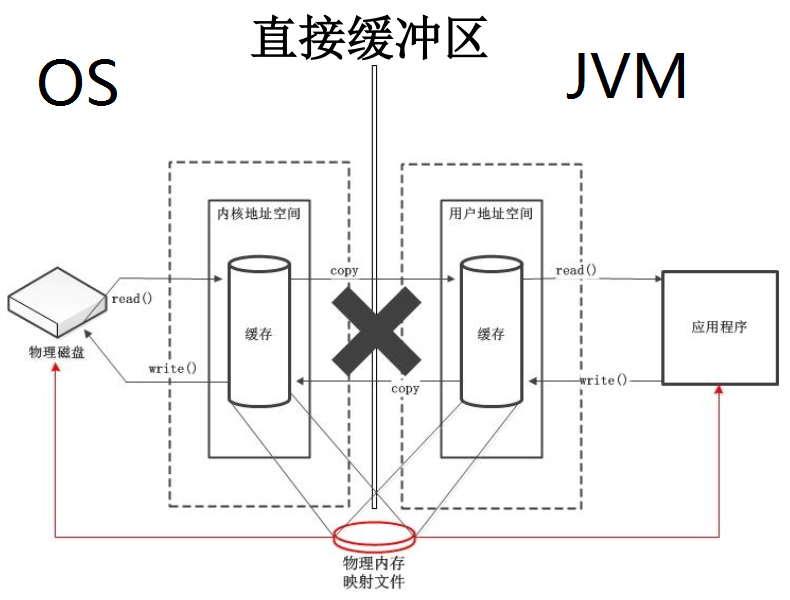
直接缓冲区则不再通过内核地址空间和用户地址空间的缓存数据的复制传递,而是在物理内存中申请了一块空间,这块空间映射到内核地址空间和用户地址空间,应用程序与磁盘之间的数据存取之间通过这块直接申请的物理内存进行。
直接字节缓冲区可以通过调用类的allocateDirect()工厂方法来创建。
直接字节缓冲区可以通过FileChannel的map()方法将文件直接映射到内存中来创建。
优点 :
可以很方便的自主开辟很大的内存空间,对大内存的伸缩性很好
减少垃圾回收带来的系统停顿时间
直接受操作系统控制,可以直接被其他进程和设备访问,减少了原本从虚拟机复制的过程
特别适合那些分配次数少,读写操作很频繁的场景
缺点 :
容易出现内存泄漏,并且很难排查
堆外内存的数据结构不直观,当存储结构复杂的对象时,会浪费大量的时间对其进行串行化。
创建和销毁的成本更高,更不宜维护,通常会用内存池来提高性能。
直接内存的回收过程
当**FullGC发现DirectByteBuffer对象变成垃圾时,会调用cleaner对象clean回收对应的堆外内存**,一定程度上防止了内存泄露。当然,也可以手动的调用该方法,对堆外内存进行提前回收。
**
手动回收,就是由开发手动调用DirectByteBuffer的cleaner的clean方法来释放空间。
1.由于cleaner是private访问权限,所以自然想到使用反射来实现。
2.DirectByteBuffer实现了DirectBuffer接口,这个接口有cleaner方法可以获取cleaner对象。
具体过程:
1.DirectByteBuffer 对象来表示堆外内存在初始化时,都会创建一个对用的 Cleaner 对象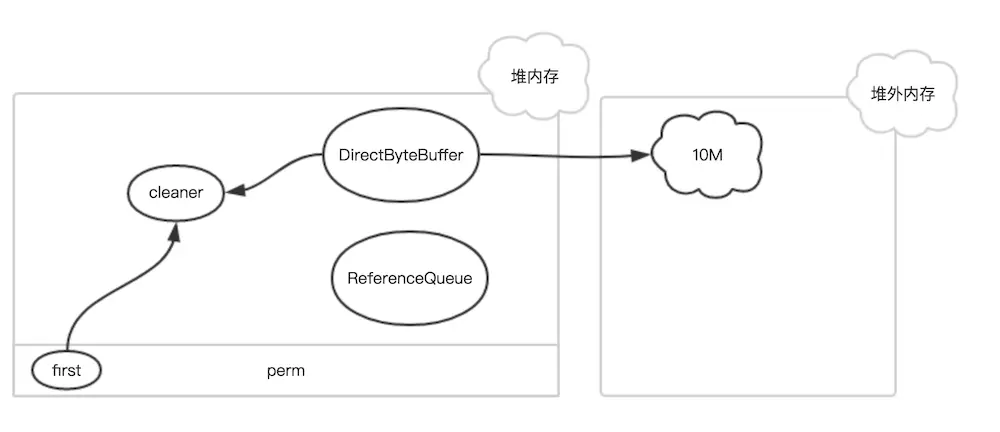
first是Cleaner类的静态变量
Cleaner对象在初始化时会被添加到Clener链表中,和first形成引用关系
ReferenceQueue是用来保存需要回收的Cleaner对象。
2.如果该 DirectByteBuffer 对象在一次GC中被回收了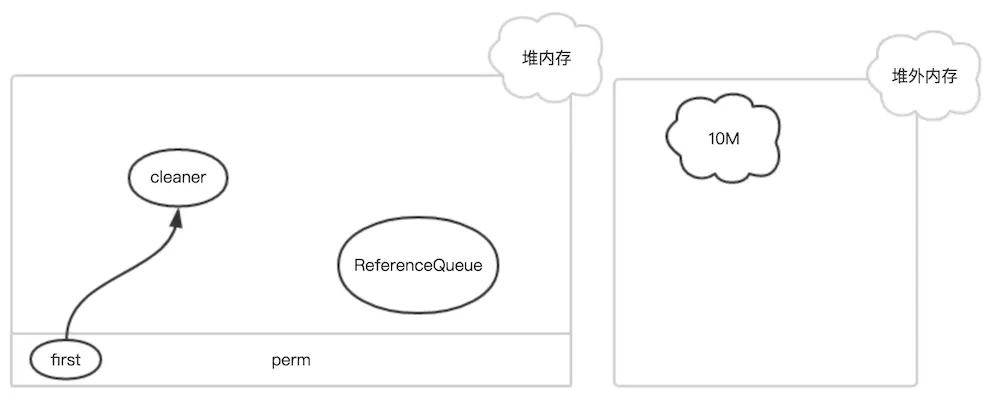
此时,只有 Cleaner 对象唯一保存了堆外内存的数据(开始地址、大小和容量),在下一次FGC时,把该 Cleaner 对象放入到 ReferenceQueue 中,并触发 clean 方法。
Cleaner 对象的 clean 方法主要有两个作用:
1、把自身从 Clener 链表删除,从而在下次GC时能够被回收
2、释放堆外内存
如果JVM一直没有执行FGC的话,无效的Cleaner对象就无法放入到ReferenceQueue中,从而堆外内存也一直得不到释放,内存岂不是会爆?
**其实在初始化DirectByteBuffer对象时,如果当前堆外内存的条件很苛刻时,会主动调用System.gc()强制执行FGC。不过很多线上环境的JVM参数有-XX:+DisableExplicitGC,导致了System.gc()等于一个空函数,根本不会触发FGC,这一点在使用Netty框架时需要注意是否会出问题。
3.通道channel
Channel通过Buffer(缓冲区)进行读写操作。read()表示读取通道数据到缓冲区,write()表示把缓冲区数据写入到通道。
Channel需要节点流作为创建基础,例如FileInputStream和FileOutputStream()的getChannel()。RandomAccessFile也能创建文件通道,支持读写模式。通过IO流创建的通道是单向的,使用RandomAccessFile创建的通道支持双向。
通道可以异步读写,异步读写表示通道执行读写操作时,也能做别的事情,解决线程阻塞。如果使用文件管道(FileChannel),建议用RandomAccessFile来创建管道,因为该类支持读写模式以及有大量处理文件的方法。
Channel实现类
FileChannel //读写文件通道
SocketChannel //通过TCP读写网络数据通道
ServerSocketChannel //监听多个TCP连接
DataChannel //通过UDP读写网络数据通道
Pipe.SinkChannel、Pipe.SourceChannel //线程通信管道传输数据
Channel常用方法
read() //从Buffer中读取数据。
write() //写入数据到Buffer中。
map() //把管道中部分数据或者全部数据映射成MappedByteBuffer,本质也是一个ByteBuffer。map()方法参数(读写模式,映射起始位置,数据长度)。
force() //强制将此通道的元数据也写入包含该文件的存储设备。
内存映射文件
https://www.jianshu.com/p/f90866dcbffc
零拷贝
零拷贝的“零”是指用户态和内核态间copy数据的次数为零。
传统的数据copy(文件到文件、client到server等)涉及到四次用户态内核态切换、四次copy。四次copy中,两次在用户态和内核态间copy需要CPU参与、两次在内核态与IO设备间copy为DMA方式不需要CPU参与。零拷贝避免了用户态和内核态间的copy、减少了两次用户态内核态间的切换。
File file = new File("test.zip");
RandomAccessFile raf = new RandomAccessFile(file, "rw");
FileChannel fileChannel = raf.getChannel();
SocketChannel socketChannel = SocketChannel.open(new InetSocketAddress("", 1234));
// 直接使用了transferTo()进行通道间的数据传输
fileChannel.transferTo(0, fileChannel.size(), socketChannel);
3.多路复用器selector
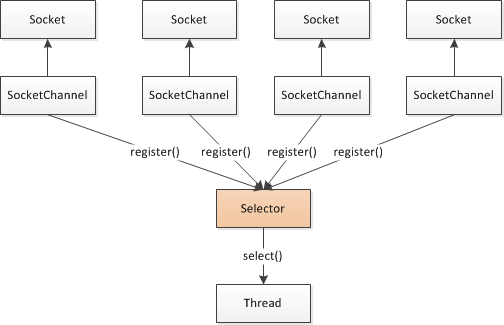
仅用单个线程来处理多个Channels的好处是,只需要更少的线程来处理通道。事实上,可以只用一个线程处理所有的通道。对于操作系统来说,线程之间上下文切换的开销很大,而且每个线程都要占用系统的一些资源(如内存)。因此,使用的线程越少越好。
1.selector的创建
Selector selector = Selector.open();
2.向selector注册通道
与Selector一起使用时,Channel必须处于非阻塞模式下。这意味着不能将FileChannel与Selector一起使用,因为FileChannel不能切换到非阻塞模式。而套接字通道都可以。
channel.configureBlocking(false);
SelectionKey key = channel.register(selector,Selectionkey.OP_READ);
注意register()方法的第二个参数。这是一个“interest集合”,意思是在通过Selector监听Channel时对什么事件感兴趣。可以监听四种不同类型的事件:
Connect
Accept
Read
Write
这四种事件用SelectionKey的四个常量来表示:
SelectionKey.OP_CONNECT
SelectionKey.OP_ACCEPT
SelectionKey.OP_READ
SelectionKey.OP_WRITE
如果你对不止一种事件感兴趣,那么可以用“位或”操作符将常量连接起来,如下:
int interestSet = SelectionKey.OP_READ | SelectionKey.OP_WRITE;
3.通过selector选择通道
NIO与IO的区别
| IO | NIO |
|---|---|
| 面向流 | 面向缓冲 |
| 阻塞IO | 非阻塞IO |
| 无 | 选择器 |

若有收获,就点个赞吧
0 人点赞
