泛型赋予容器强大的编译时类型检查能力。很多人不喜欢静态编程,感觉像是法西斯主义。多年以后,他们会发现,他们痛恨的东西,反而恰恰保护了他们。
1. 为什么需要泛型
泛型是后来才有的,Java 1.5 才引入了泛型。
数组是类型安全的,String[] 声明一个存储了 String 对象的数组。而像 List 则不行,可以添加任意类型的数据:
String[] array = new String[2];array[0] = "ok";array[1] = 1; // 报错List list = new ArrayList();list.add(new Object()); // oklist.add(1); // oklist.add(""); // ok
如何保证 List 类型安全或者约束?装饰器模式,如果需要的是 int 呢?复制改改:
pubic class StringList { List list = new ArrayList(); void add(String s) { list.add(s); } int size() { return list.size(); } String get(int i) { return (String) list.get(i); }}// 使用StringList stringList = new StringList();
引入泛型之后:
ArrayList<String> myList = new ArrayList<>();

泛型化的类,其类型声明在类上,通过传递参数 E,使得 ArrayList 变为“全新”的(编译期)类型。ArrayList 和 ArrayList 是完全“独立”的两个类。
new ArrayList<Integer>();new ArrayList<String>();
不同一个类,因为不能互相赋值:
ArrayList<Integer> listt = new ArrayList<String>();

也是同一个类,因为运行时泛型会被擦除。
2. 泛型擦除和问题
2.1 泛型擦除
从没有泛型的世界进化到有泛型的世界(1.4 -> 1.5),Java 选择了向后兼容,而非 Python2 到 Python3 那样断裂,编译成字节码后会被擦除,分别从 IDEA 反编译后的以及 ASM ByteCode Viewer 插件中可以看出:
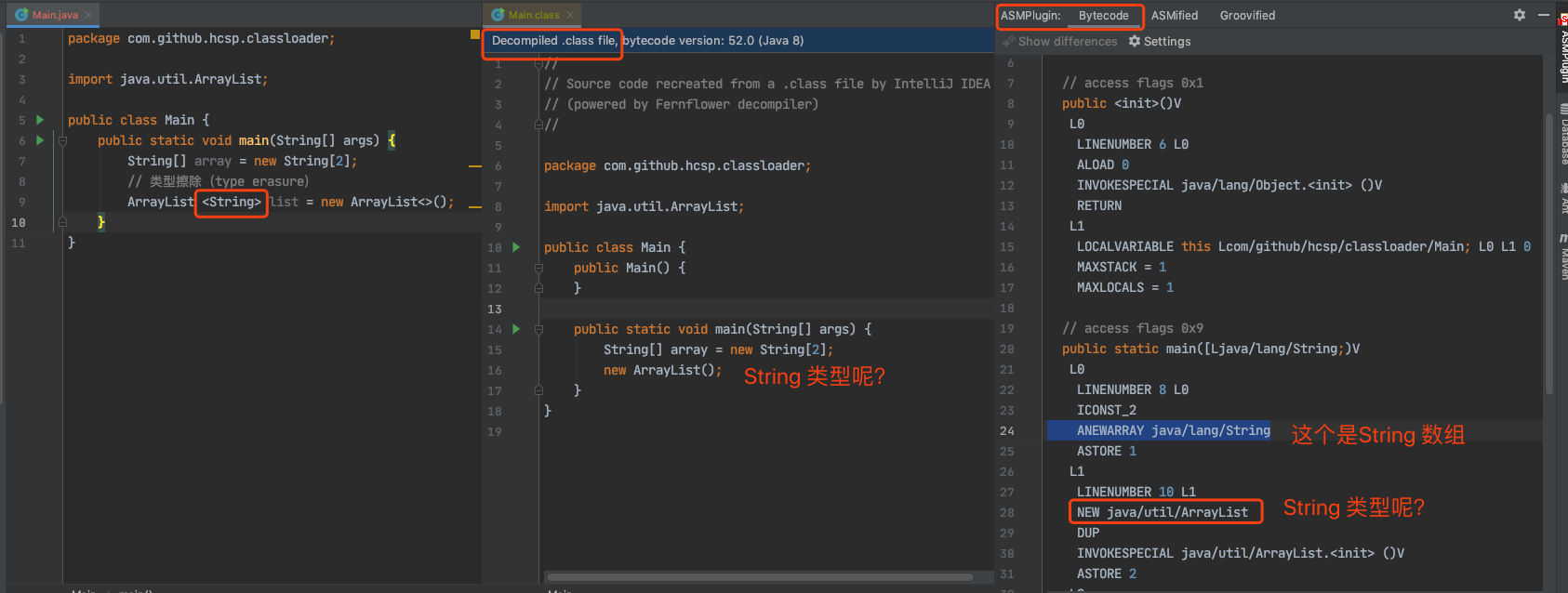
2.1 擦除带来的问题
Java 的泛型是编译期的假泛型,在编译和开发期间约束源代码中的类型,而编译后则完全被擦除,泛型信息在运行期完全不保留。
List 并不是 List

