持久化统计功能是通过将内存中的统计数据存储到磁盘中,使其在数据库重 启时可以快速重新读入这些统计信息而不用重新执行统计,从而使得查询优化器 可以利用这些持久化的统计信息准确地选择执行计划(如果没有这些持久化的统计信息,那么数据库重启之后内存中的统计信息将会丢失,下一次访问到某库某表时,需要重新计算统计信息,并且重新计算可能会因为估算值的差异导致查询计划发生变更,从而导致查询性能发生变化)。
如何启用统计信息的持久化功能呢?
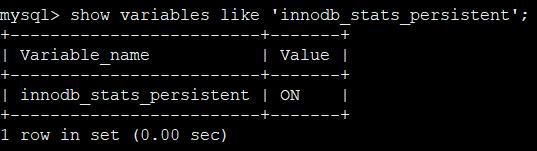
当 innodb_stats_persistent = ON 时全局的开启统计信息的持久化功能,默认是开启的,
show variables like 'innodb_stats_persistent';
如果要单独关闭某个表的持久化统计功能,则可以通过 ALTER TABLE tblname STATS PERSISTENT = 0 语句来修改。
innodb_table_stats
innodb_table_stats 表提供查询与表数据相关的统计信息。
select * from innodb_table_stats where table_name = 'order_exp'\G
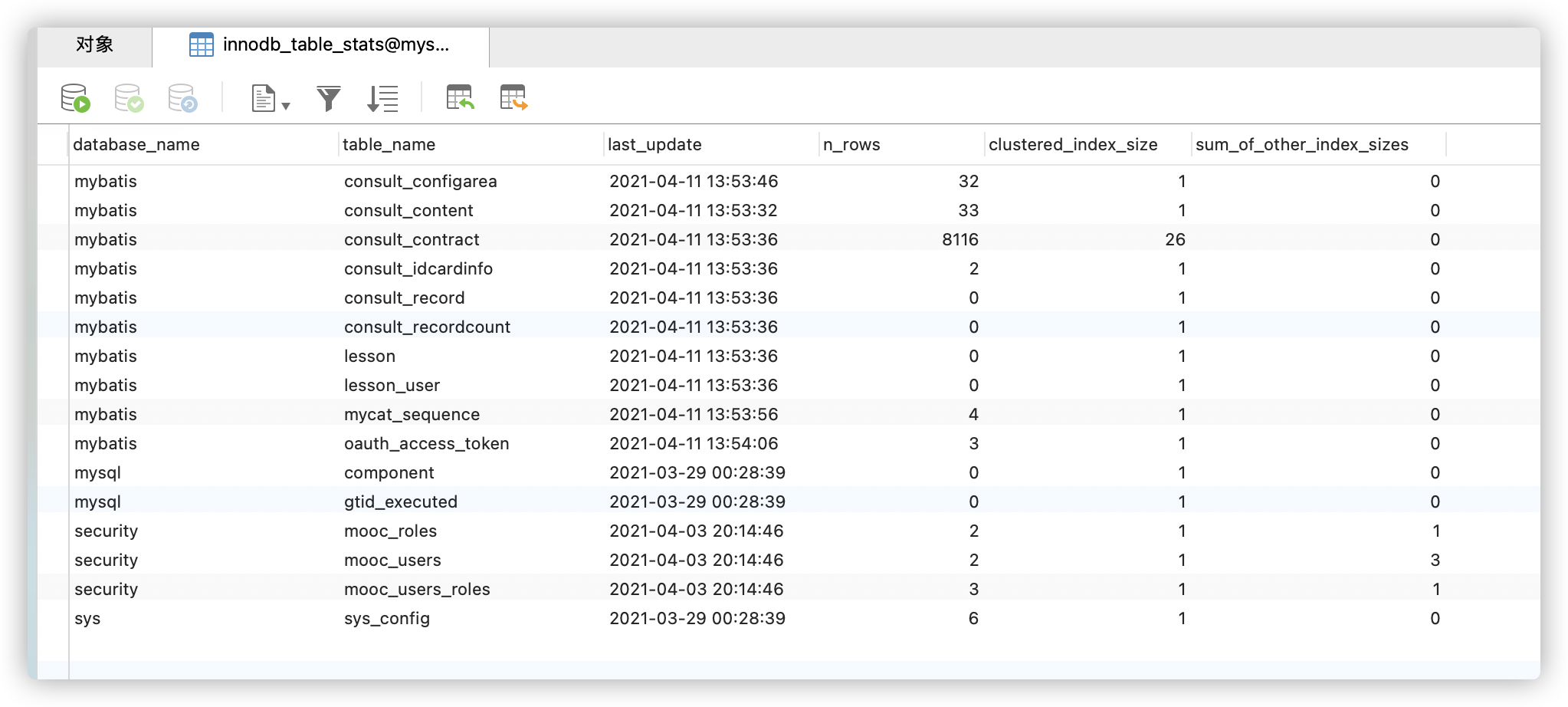
database_name:数据库名称。
• table_name:表名、分区名或子分区名。
• last_update:表示 InnoDB 上次更新统计信息行的时间。
• n_rows:表中的估算数据记录行数。
• clustered_index_size:主键索引的大小,以页为单位的估算数值。
• sum_of_other_index_sizes:其他(非主键)索引的总大小,以页为单位的估算数值。
innodb_index_stats
innodb_index_stats 表提供查询与索引相关的统计信息。
select * from innodb_index_stats where table_name = 'order_exp';
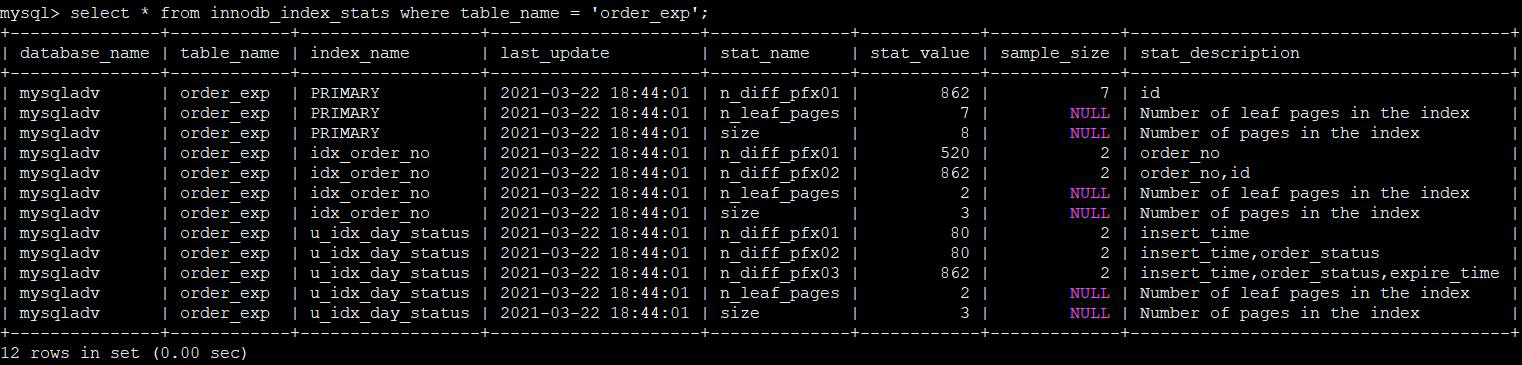
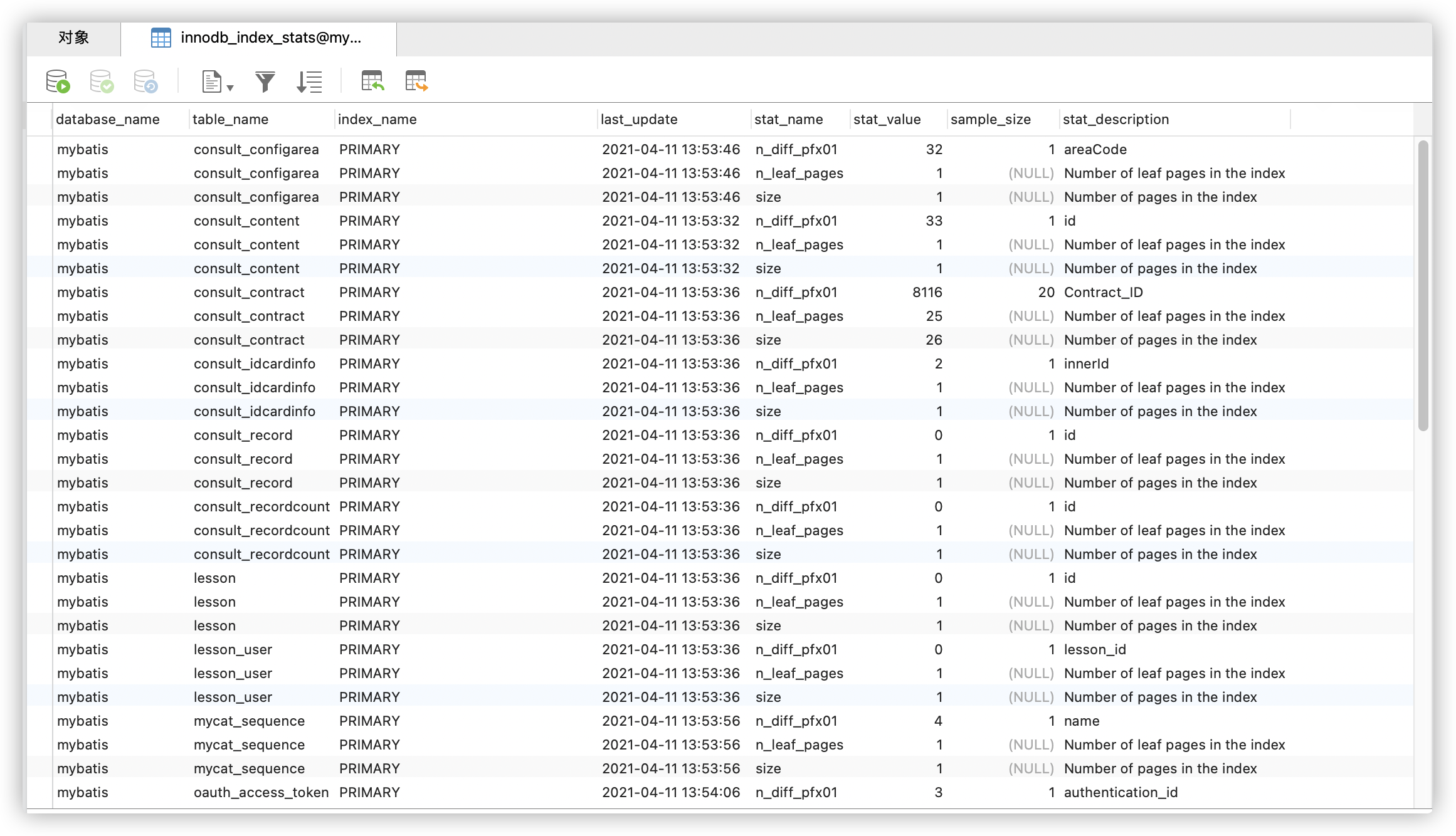
表字段含义如下。
• database_name:数据库名称。
• table_name:表名、分区表名、子分区表名。
• index_name:索引名称。
• last_update:表示 InnoDB 上次更新统计信息行的时间。
• stat_name:统计信息名称,其对应的统计信息值保存在 stat_value 字段中。
• stat_value:保存统计信息名称 stat_name 字段对应的统计信息值。
• sample_size:stat_value 字段中提供的统计信息估计值的采样页数。
• stat_description:统计信息名称 stat_name 字段中指定的统计信息的说明。
从表的查询数据中可以看到:
• stat_name 字段一共有如下几个统计值。
- size:当 stat_name 字段为 size 值时,stat_value 字段值表示索引中的总 页数量。
- n_leaf_pages:当 stat_name 字段为 n_leaf_pages 值时,stat_value 字段 值表示索引叶子页的数量。
- n_diff_pfxNN:NN 代表数字(例如 01、02 等)。当 stat_name 字段为 n_diff_pfxNN 值时,stat_value 字段值表示索引的 first column(即索引的最前索 引列,从索引定义顺序的第一个列开始)列的唯一值数量。例如:当 NN 为 01 时,stat_value 字段值就表示索引的第一个列的唯一值数量;当 NN 为 02 时, stat_value 字段值就表示索引的第一个和第二个列组合的唯一值数量,依此类推。 此外,在 stat_name = n_diff_pfxNN 的情况下,stat_description 字段显示一个以逗 号分隔的计算索引统计信息字段的列表。
• 从 index_name 字段值为 PRIMARY 数据行的 stat_description 字段的描述 信息“id”中可以看出,主键索引的统计信息只包括创建主键索引时显式指定的列。
• 从 index_name 字段值为 u_idx_day_status 数据行的 stat_description 字段的描述信息“insert_time,order_status,expire_time”中可以看出,唯一索引的统 计信息只包括创建唯一索引时显式指定的列。
• 从 index_name 字段值为 idx_order_no 数据行的 stat_description 字段的描 述信息“order_no,id”中可以看出,普通索引(非唯一的辅助索引)的统计信息 包括了显式定义的列和主键列。

若有收获,就点个赞吧
0 人点赞
