所谓的锁其实是一个内存中的结构,在事务执行前本来是没有锁的,也就是说一开始是没有锁结构和记录进行关联的,当一个事务想对这条记录做改动时, 首先会看看内存中有没有与这条记录关联的锁结构,当没有的时候就会在内存中生成一个锁结构与之关联。比方说事务 E1 要对记录做改动,就需要生成一个锁结构与之关联。锁结构里至少要有两个比较重要的属性:
- trx 信息:代表这个锁结构是哪个事务生成的。
- is_waiting:代表当前事务是否在等待。
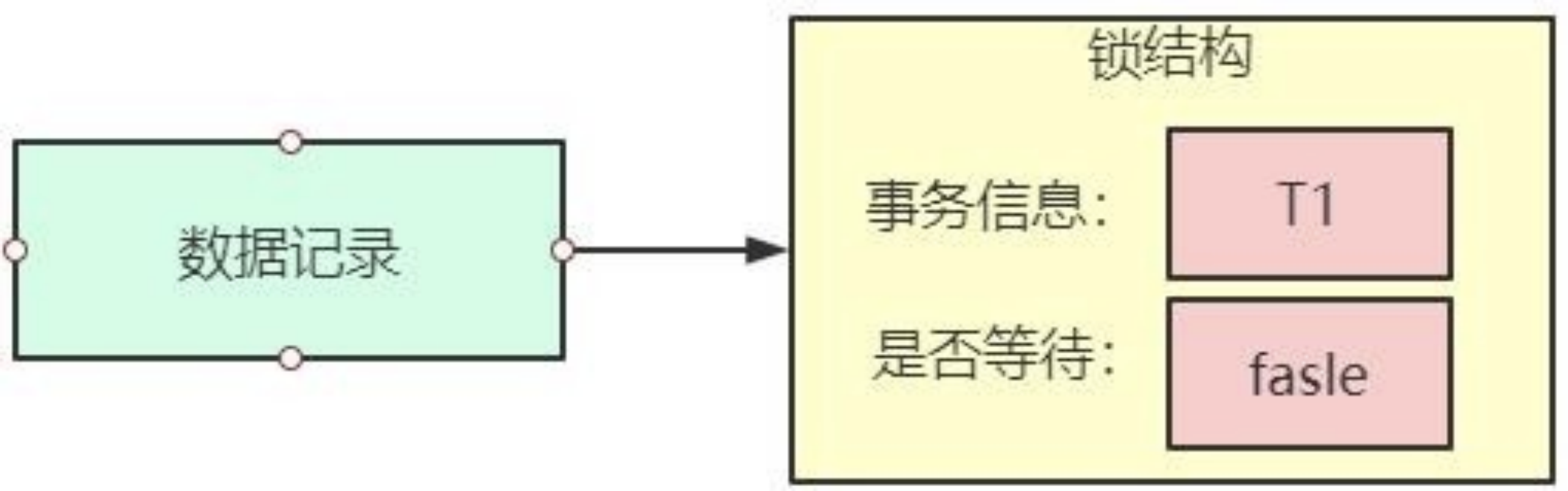
当事务 T1 改动了条记录后,就生成了一个锁结构与该记录关联,因为之前没有别的事务为这条记录加锁,所以 is_waiting 属性就是 false,我们把这个场景就称之为获取锁成功,或者加锁成功,然后就可以继续执行操作了。
在事务 T1 提交之前,另一个事务 T2 也想对该记录做改动,那么先去看看有没有锁结构与这条记录关联,发现有一个锁结构与之关联后,然后也生成了一个锁结构与这条记录关联,不过锁结构的 is_waiting 属性值为 true,表示当前事务需要等待,我们把这个场景就称之为获取锁失败,或者加锁失败,或者没有成功的获取到锁: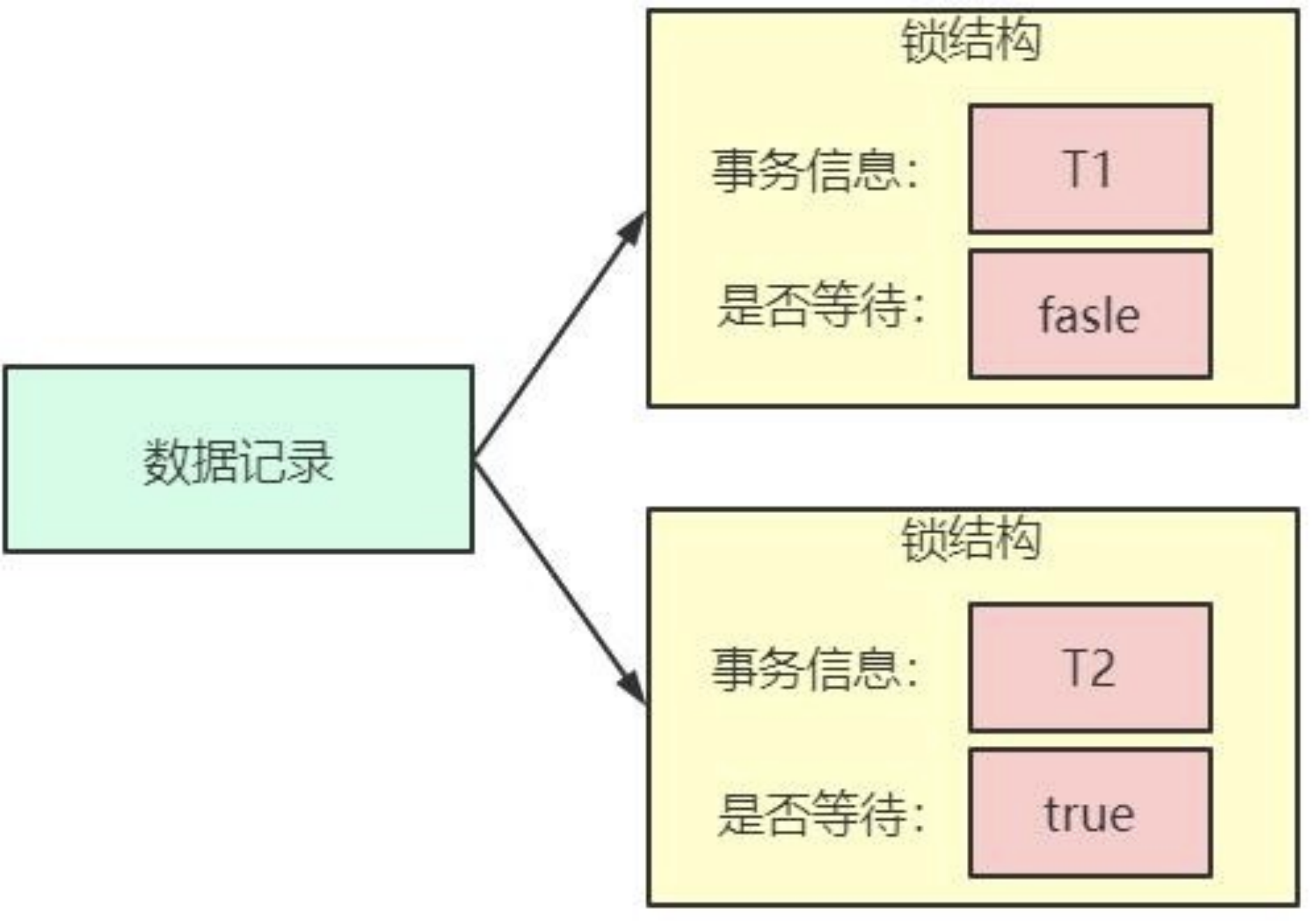
在事务 T1 提交之后,就会把该事务生成的锁结构释放掉,然后看看还有没有别的事务在等待获取锁,发现了事务 T2 还在等待获取锁,所以把事务 T2 对应的锁结构的 is_waiting 属性设置为 false,然后把该事务对应的线程唤醒,让它继续执行,此时事务 T2 就算获取到锁了。
这种实现方式非常像并发编程里的 CLH 队列。
对一条记录加锁的本质就是在内存中创建一个锁结构与之关联。那么,一个事务对多条记录加锁时,是不是就要创建多个锁结构呢。
比如 SELECT * FROM teacher LOCK IN SHARE MODE;
很显然,这条语句需要为 teacher 表中的所有记录进行加锁。那么,是不是需要为每条记录都生成一个锁结构呢?其实理论上创建多个锁结构没有问题,反而更容易理解。但是如果一个事务要获取 10,000 条记录的锁,要生成 10,000 个这样的结构,不管是执行效率还是空间效率来说都是很不划算的,所以实际上, 并不是一个记录一个锁结构。
当然锁结构实际是很复杂的,我们大概了解下里面包含哪些元素。
锁所在的事务信息:无论是表级锁还是行级锁,一个锁属于一个事务,这里记载着该锁对应的事务信息。
索引信息:对于行级锁来说,需要记录一下加锁的记录属于哪个索引。表锁/行锁信息:表级锁结构和行级锁结构在这个位置的内容是不同的。具体表现为表级锁记载着这是对哪个表加的锁,还有其他的一些信息;
而行级锁记载了记录所在的表空间、记录所在的页号、区分到底是为哪一条记录加了锁的数据结构。
锁模式:锁是 IS,IX,S,X 中的哪一种。
锁类型:表锁还是行锁,行锁的具体类型。
其他一些和锁管理相关的数据结构,比如哈希表和链表等。
基本上来说,同一个事务里,同一个数据页面,同一个加锁类型的锁会保存在一起

若有收获,就点个赞吧
0 人点赞
