- 1.全值匹配我最爱
- 2.最佳左前缀法则
- 3.不在索引列上做任何操作
- 4.存储引擎不能使用索引中范围条件右边的列
- 5.尽量使用覆盖索引
- 6.mysql在使用不等于(!=或者<>)的时候无法使用索引会导致全表扫描
- 7.is null,is not null 也无法使用索引
- 8.like以通配符开头(’$abc…’)mysql索引失效会变成全表扫描操作
- 9.字符串不加单引号会导致索引失效
- 10.少用or,用它连接时会索引失效
- 一般性建议
- LIKE
- explain select _* _from test01 where c1=’a1’ and c2 like ‘kk%’ and c3 = ‘a3’ ;
- ">

- explain select _* _from test01 where c1=’a1’ and c2 like ‘%kk’ and c3 = ‘a3’ ;
- explain select _* _from test01 where c1=’a1’ and c2 like ‘%kk%’ and c3 = ‘a3’ ;
- explain select _* _from test01 where c1=’a1’ and c2 like ‘K%kk%’ and c3 = ‘a3’ ;
- where > <
- explain select _* _from test01 where c1=’a1’ and c2 = ‘a2’ and c3= ‘a3’ and c4 = ‘a4’;
- explain select _* _from test01 where c1=’a1’ and c2 = ‘a2’ and c4 = ‘a4’ and c3= ‘a3’;
- explain select _* _from test01 where c4 = ‘a4’ and c3= ‘a3’ and c2 = ‘a2’ and c1=’a1’;
- explain select _* _from test01 where c1=’a1’ and c2 = ‘a2’ and c3> ‘a3’ and c4 = ‘a4’;
- order by
- explain select _* _from test01 where c1=’a1’ and c2 = ‘a2’ and c4 = ‘a4’ order by c3;
- explain select _* _from test01 where c1=’a1’ and c2 = ‘a2’ order by c3;
- explain select _* _from test01 where c1=’a1’ and c2 = ‘a2’ order by c4;
- explain select _* _from test01 where c1=’a1’ and c5 = ‘a5’ order by c2,c3;
- explain select _* _from test01 where c1=’a1’ and c5 = ‘a5’ order by c3,c2;
- explain select _* _from test01 where c1=’a1’ and c2 = ‘a2’ order by c2,c3;
- explain select _* _from test01 where c1=’a1’ and c2 = ‘a2’ and c5 = ‘a5’ order by c2,c3;
- explain select _* _from test01 where c1=’a1’ and c2 = ‘a2’ and c5 = ‘a5’ order by c3,c2;
- explain select _* _from test01 where c1=’a1’ and c5 = ‘a5’ order by c3,c2;
- group by
1.全值匹配我最爱
2.最佳左前缀法则
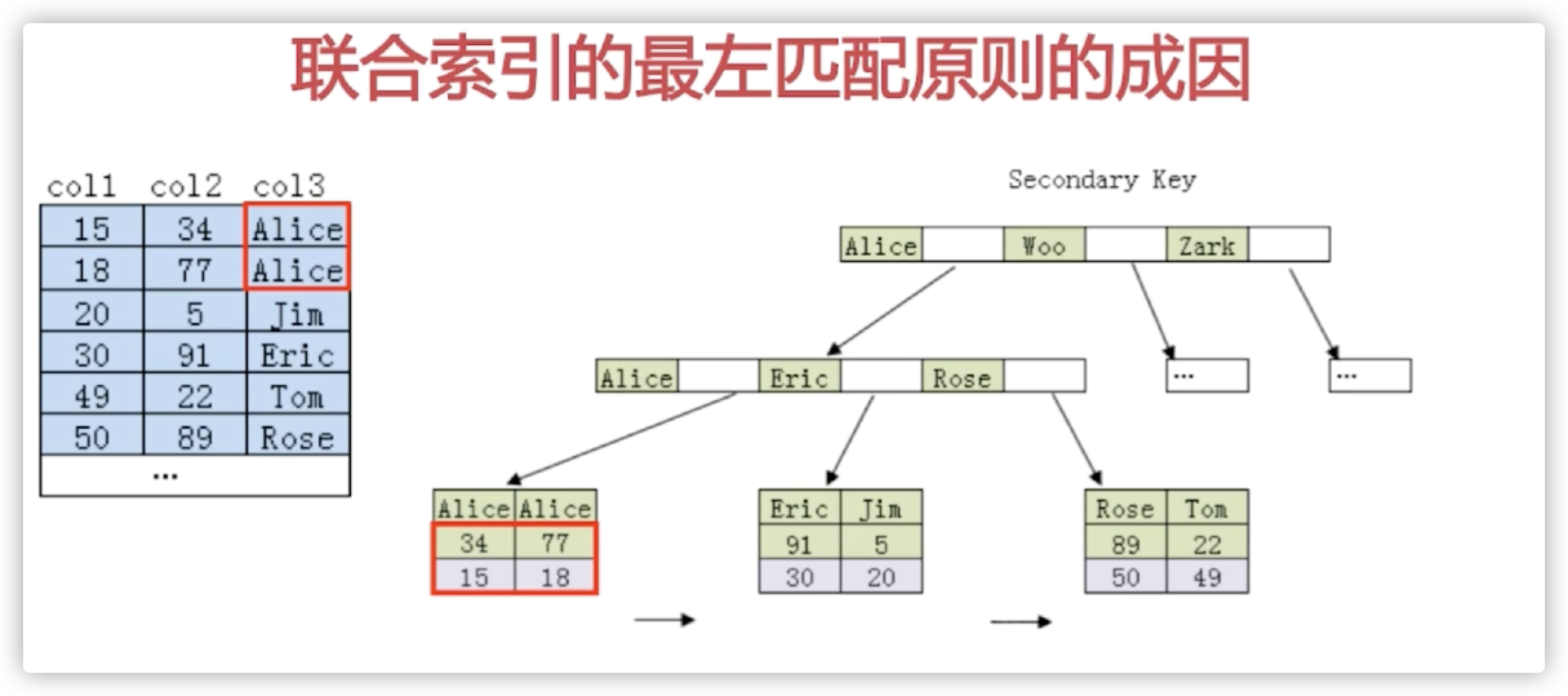
如果索引了多例,要遵守最左前缀法则。指的是查询从索引的最左前列开始并且不跳过索引中的列。
3.不在索引列上做任何操作
(计算、函数、(自动or手动)类型转换),会导致索引失效而转向全表扫描
4.存储引擎不能使用索引中范围条件右边的列
5.尽量使用覆盖索引
(只访问索引的查询(索引列和查询列一致)),减少select*
6.mysql在使用不等于(!=或者<>)的时候无法使用索引会导致全表扫描
7.is null,is not null 也无法使用索引
8.like以通配符开头(’$abc…’)mysql索引失效会变成全表扫描操作
解决like’%字符串%’索引不被使用的方法
1、可以使用主键索引
2、使用覆盖索引,查询字段必须是建立覆盖索引字段
3、当覆盖索引指向的字段是varchar(380)及380以上的字段时,覆盖索引会失效!
9.字符串不加单引号会导致索引失效
10.少用or,用它连接时会索引失效

一般性建议
- 对于单键索引,尽量选择针对当前query过滤性更好的索引
- 在选择组合索引的时候,当前Query中过滤性最好的字段在索引字段顺序中,位置越靠前越好
- 在选择组合索引的时候,尽量选择可以能包含当前query中的where子句中更多字段的索引
- 尽可能通过分析统计信息和调整query的写法来达到选择合适索引的目的
```sql
create table tewt01
(
id int auto_increment,
c1 varchar(10) null,
c2 varchar(10) null,
c3 varchar(10) null,
c4 varchar(10) null,
c5 varchar(10) null,
constraint tewt01_pk
);primary key (id)
insert into test01(c1, c2, c3, c4, c5) values (‘a1’,’a2’,’a3’,’a4’,’a5’); insert into test01(c1, c2, c3, c4, c5) values (‘b1’,’b2’,’b3’,’b4’,’b5’); insert into test01(c1, c2, c3, c4, c5) values (‘c1’,’c2’,’c3’,’c4’,’c5’); insert into test01(c1, c2, c3, c4, c5) values (‘d1’,’d2’,’d3’,’d4’,’d5’); insert into test01(c1, c2, c3, c4, c5) values (‘e1’,’e2’,’e3’,’e4’,’e5’);
create index idx_c1234 on test01(c1, c2, c3, c4); ```
LIKE
explain select _* _from test01 where c1=’a1’ and c2 like ‘kk%’ and c3 = ‘a3’ ;
explain select _* _from test01 where c1=’a1’ and c2 like ‘%kk’ and c3 = ‘a3’ ;

explain select _* _from test01 where c1=’a1’ and c2 like ‘%kk%’ and c3 = ‘a3’ ;

explain select _* _from test01 where c1=’a1’ and c2 like ‘K%kk%’ and c3 = ‘a3’ ;

where > <
explain select _* _from test01 where c1=’a1’ and c2 = ‘a2’ and c3= ‘a3’ and c4 = ‘a4’;

explain select _* _from test01 where c1=’a1’ and c2 = ‘a2’ and c4 = ‘a4’ and c3= ‘a3’;

explain select _* _from test01 where c4 = ‘a4’ and c3= ‘a3’ and c2 = ‘a2’ and c1=’a1’;

explain select _* _from test01 where c1=’a1’ and c2 = ‘a2’ and c3> ‘a3’ and c4 = ‘a4’;

order by
explain select _* _from test01 where c1=’a1’ and c2 = ‘a2’ and c4 = ‘a4’ order by c3;

explain select _* _from test01 where c1=’a1’ and c2 = ‘a2’ order by c3;

explain select _* _from test01 where c1=’a1’ and c2 = ‘a2’ order by c4;

explain select _* _from test01 where c1=’a1’ and c5 = ‘a5’ order by c2,c3;

explain select _* _from test01 where c1=’a1’ and c5 = ‘a5’ order by c3,c2;

explain select _* _from test01 where c1=’a1’ and c2 = ‘a2’ order by c2,c3;

explain select _* _from test01 where c1=’a1’ and c2 = ‘a2’ and c5 = ‘a5’ order by c2,c3;

explain select _* _from test01 where c1=’a1’ and c2 = ‘a2’ and c5 = ‘a5’ order by c3,c2;
一般情况下 排序和查找字段顺序不同会发生 文件排序
但是当排序字段已经是一个常量(这里的c2),只有c3 会参与排序
explain select _* _from test01 where c1=’a1’ and c5 = ‘a5’ order by c3,c2;
相比上面去掉c2 ,发生了 文件排序
group by
explain select c2,c3 from test01 where c1=’a1’ and c4 = ‘a4’ group by c2,c3;

explain select c2,c3 from test01 where c1=’a1’ and c4 = ‘a4’ group by c3,c2;


若有收获,就点个赞吧
0 人点赞
